Table of Contents
Page: Profile
You can switch between an extended and a simple view. The simple view hides the advanced settings.
General data
Short title
A short name for the crawled website. It is used i.e. as title text in the tabs on top of the page.
Description of the project
Set a description of the project. It is visible on the starting page.
List of start urls for the crawler
Enter one or more urls as a list of urls (one per line) here. These will be the starting points to scan the website to generate the searchindex. The spider will stay on the given Hostname(s) and mark them as “internal”. All elements like css or javascript files or links that do not match any hostname of the starting urls are “external” resources. One url in most cases is enough because the spider follows all allowed links. You can add more urls if you have several tools on your domain that are not linked or you want to merge several domains into one search index. As an example if you have a website www.example.com and a blog in blog.example.com.
max. pages to scan
Before scanning a larger website you can make test with a limited number of pages by entering a low number here, i.e. “3”. Enter “0” (zero) for no limit.
Screenshot or profile image
You can add a single image for the profile.
There are 2 possibilities to add an image:
(1) paste You can copy a new image / screenshot into your clipboard, click into the dashed section and paste it. After pasting an image you will see a smaller preview and the image data size. This method is useful if you have a screenshot tool to create fast a cropped image without saving it as a file first.
(2) upload Select an image file (Jpeg or Png) from your local system. The classic way.
If you save the profile the image will be down scaled to max. 600 px height and width; smaller images keep their size.
Search index
The spider already respects the rules for spiders, like robots.txt, x-robots tag, robots command in html header, rel attributes in links.
List of regex that must match the full url
You can place additional rules to describe what must match to be part in the search index. In most cases just leave it empty = all urls are accepted. If you have just one domain in the list of starting urls you can use next option that is applied on the path.
List of regex that need to match to the path of a url
This option is similiar the last option, but the list of regex rules must match on the path. In most cases just leave it empty = all urls are accepted. Example: You have several subdirs in the webroot but want to have just a few of them in the index
^/blog/.*
^/docs/.*
^/pages/.*
List of exclude regex for the path applied after the include regex above
Here you can add more regex lines for finetuning. This is a list of elements to exclude. Remark: The spider cannot detect inifinite loops, like calendars with browsing buttons. Add its path here.
max. depth of directories for the scan
You can limit the depth of path by counting “/” in a url. Value is an integer account. This option will stop indexing if you would have a neverending loop with a longer and longer path.
optional: user and password
The use case is the scan for public websites. Additionally the basic authentication is supported (as only authentication method). To use a user and password divide with “:”
myuser:secretpassword
Noindex
Index contents marked with NoIndex anyway (default value: OFF)
NoFollow
Follow all links and ignore nofollow tagging (default value: OFF)
The next variables override the defaults for all profiles (see program settings).
search index scan - simultanous Requests (overrides the default of [N])
Here you can override the number of allowed parrallel GET requests while spidering. The current global value is given in the label text and in the placeholder text. Leave the field empty if you don’t want to override the default.
Content to remove from searchindex (1 line per regex; not casesensitive)
Here you can override the default rules “Content to remove from searchindex”. Leave the fied empty if you don’t want to override the default.
Hint: You see the global value as placeholder (dimmed text). If you don’t want to start from point zero you can double click into the textarea to start with the default text.
Search frontend
These options are only required if you want to add a search form with a website search into your website.
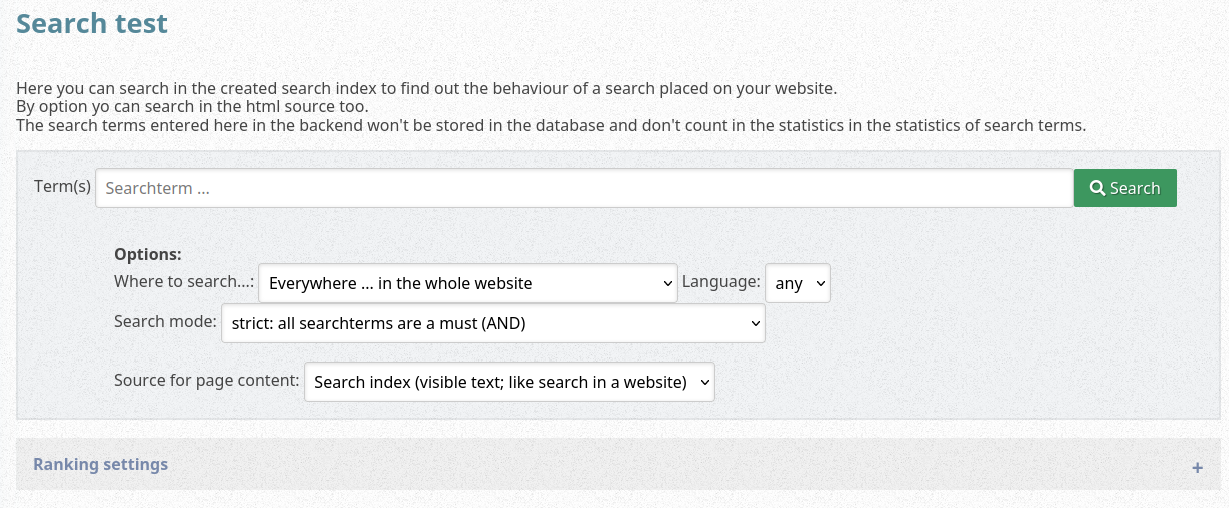
Search areas of the website (in JSON syntax)
The JSON describes in keys the visible text; values are names of subdirs You can define the options for the areas to search in.
{
"everywhere": "%",
"... Blog": "\/blog\/",
"... Photos": "\/photos\/",
"... Docs": "\/docs\/"
}
Items for language filter (one per line)
You can add an option field to search in documents in a given language. The language of a document is detected in the lang attribute in the html tag. Language specific parts inside the page are not detected. Line by line you can add values of ISO 639 / IANA registry (mostly 2 letter lowercase). The option to search in all languages will be added automatically.
Resources scan and analysis
Resources scan - simultanous Requests (overrides the default of [N])
Here you can override the number of allowed parrallel HEAD requests while spidering. The current global value is given in the label text and in the placeholder text. Leave the field empty if you don’t want to override the default.
Deny list
All urls in links images, … that contain one of the the texts will be excluded. There is 1 searchtext as regex per line. Hint: The most easy way to add a new - and useful - entry is by button of in the report view. The list here in the profile settings page is good for deleting entries or reorder them.