Mo, 29. Juni, 2026
Das Blog Tool Flatpress [1] nutze ich schon Ewigkeiten… naja, und bei so vielen bereits geschriebenen Artikeln bleibe ich auch dabei. Es gab vor einigen Jahren eine Durststrecke, weil es nicht weiterentwickelt wurde. Aber zum Glück fanden sich Maintainer, die das Projekt weiterführen.
Gern unterstütze ich es auf meine Weise. Nun habe ich mein erstes Flatpress-Plugin [2] geschrieben, damit ich im Backend des Blogs bei Select-Boxen einen Textfilter zum schnelleren Auffinden von Einträgen aktiviere. Mein Plugin aktiviert dazu die jQuery Bibliothek Select2 [3].
Nach Aktivierung in Flatpress sieht das so aus: In einer Filterbox im Backen tippe einige Zeichen, um die Auswahl zu reduzieren.
Das Plugin wurde gleichsam im Wiki von Flatpress angemeldet [4]. Damit sollten es Suchende auch am entsprechenden Ort finden.
Weiterführende Links:
- www.flatpress.org Blog tool
- Github: Sourcecode und Readme zur Installation
- select2.org jQuery Plugin Select2
- wiki.flatpress.org Seite zum Plugin im Flatpress Wiki
Source:
Do, 4. Juni, 2026
Restic [1] ist eine kommandozeilen-basierte Datensicherungssoftware, mit der Datei-Backups erstellt werden können. Backups werden lokal verschlüsselt. Als Ziel kann man Systeme mit unterschiedlichsten Protokollen anbinden: lokale Mounts, SSH-Verbindungen, S3, … und auch Http(s) zum Restic Rest Server [2].
Naja, genaugenommen nutze ich auf meinem Arbeitsrechner nicht plain den Restic Client, sondern einen Wrapper: IML Backup [3]. Bevor Restic anläuft, gibt es eine automatisierte Datenbank-Sicherung für Mysql/ Mariadb, Postgres, LDAP, CouchDB, Sqlite. Dieses Tool habe ich seit mehreren Jahren zur Daten-Sicherung von 200 Servern im Einsatz.
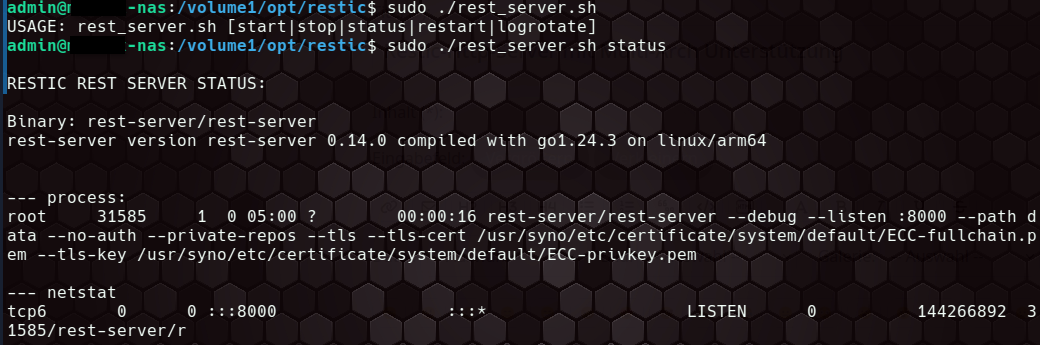
Mein Projekt “Restic Http Server on Synology NAS” [4] bietet eiinen Installer in Form eines Shellskripts für den Betrieb eines Restic Rest Server auf einem Synology NAS. Mit diesem Projekt habe ich daheim mein privates Synology NAS als Backup-Ziel der Rechner daheim eingerichtet. Es bringt noch kleine Helferleni mit.
- ein Server-Skript zur Handhabe des Restic-Servers: Starten, Stoppen, Status, Logrotation
- eine User-Verwaltung: User anlegen, Passwort setzen, User und dessen Daten löchen
Restic ist Freie Software … und meine Skripte sind es ebenso. Nachdem ich den Installer für die Arm64 Architektur ausgelegt habe, gab es nun vom User basti122303 einen Pull Request [5], der nun die Architekturen
von Synology Systemen erkennt.
Da es bei meinen Projekten bisher eher weniger Code-Beisteuerungen gab, freue ich mich über diese Erweiterung! Freie Software hat doch was Cooles! Cheers!
Weiterführende Links:
- https://restic.net/ - Restic Client (Windows, Mac, Linux und weitere)
- https://github.com/restic/rest-server - Restic Rest Http-Server
- https://os-docs.iml.unibe.ch/iml-backup/ - Restic Wrapper
- https://github.com/a … -server-for-synology - Installer für den Restic-Rest Server auf Synology
- https://github.com/a … -for-synology/pull/4 - Pull Request zur Unterstützung weiterer Architekturen
So, 29. März, 2026
Als Blog [1] Software nutze eine halbe Ewigkeit Flatpress [2].
Mittlerweile ist dieser bei Verion 1.5 angekommen und auch mit aktuellen PHP Versionen kompatibel. Es wurde Zeit, dass ich mal wieder ein Update angehe…
Unter der Haube gibt es eine neue Smarty Version als Template Engine, weshalb mein bisheriges Theme nicht mehr läuft. Kurzerhand wurde das Default-Theme hergenommen, jenes farbärmer gemacht und auf ganze Bildschirmbreite gestreckt. Noch ist es mehr ein Hack, als ein sauber aufgezogenes Theme. Vielleicht schiebe ich es mal später nach notwendigen Aufräumarbeiten hinterher.
Weiterführende Links:
- www.axel-hahn.de/blog/ - Axels Blog
- flatpress.org - Leichtgewichtiges Blogging Tool ohne Datenbank, GNU GPL
Mo, 1. September, 2025
Ich hatte mir jüngst Topgrade [1] installiert. Dies ist ein universeller System-Updater für Windows, Mac und etliche Linux Distributionen.
Ich war sofort happy - und so wurde es kurzerhand auf meinem Linux PC in einen Cronjob eingebunden.
Damit ich nicht im Blindflug bin, wollte ich per Desktop-Notifikation benachrichtigt werden. Folglich musste zusätzlich ein kleines Bash-Skript für einen Wrapper [2] her. Jener startet ganz einfach notfify-send vor und nach Ausführung von topgrade. Bei Beendigung mit Fehler bleibt der Hinweis bis Klick stehen. So verpasse ich auch bei Conjobs im Hintergrund keine fehlgeschlagenen Updates.
Das ist zu einfach :-)
Naja, fast. Der tricky Part ist: die Variable DBUS_SESSION_BUS_ADDRESS ist richtig zu belegen, dass eine Nachricht von einem eigentlich “leisen Hintergrund-Job” den Weg zum Desktop eines am Bildschirm sitzenden Benutzers findet. Shellskript-Bastler können sich das im Quellcode ansehen - für alle anderen funktioniert es halt out-of-the-box.
Weiterführende Links:
- Github: Topgrade (en)
- Github: Axels Topgrade-wrapper (en)
Do, 14. August, 2025
Um ein Web oder ein Verzeichnis mit Username und Passwort zu schützen, kann man mit Basic Authentication arbeiten. Man kann Benutzer oder Gruppen berechtigen, eine Seite zu öffnen.
Dazu hatte ich kürzlich 2 PHP Klassen zum Verwalten von htpasswd- und htgroup-Dateien veröffentlicht. Diese kann man in Programmierprojekten einsetzen.
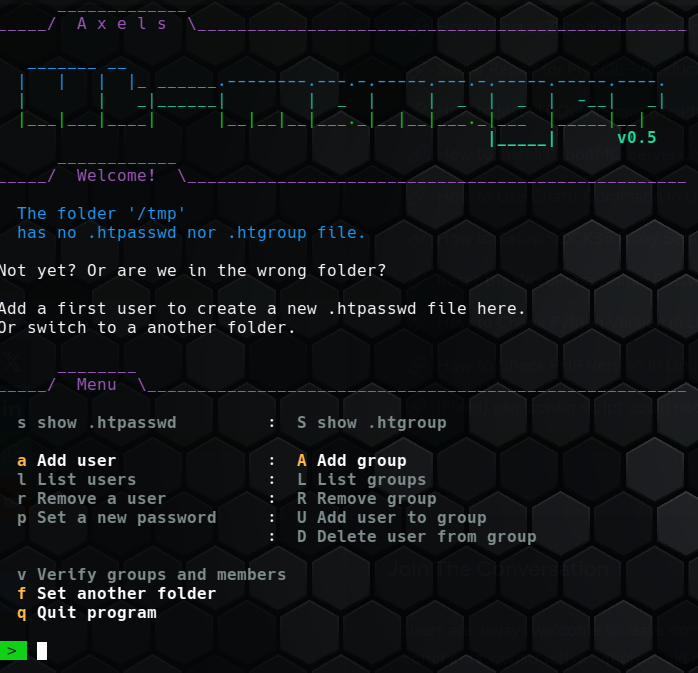
Nun habe ich mit jenen Klassen ein Konsolen-Werkzeug in PHP geschrieben, um Benutzer und Gruppen auf etwas bequemere Art und interaktiv im Terminal zu verwalten. Das Tool benötigt keinerlei fremde Werkzeuge, wie openssl oder htpasswd, um die Benutzerpasswörter zu erstellen.
Und so sieht das Ganze aus:
Mit -h oder –help sieht man die unterstützten Parameter. Man wählt mit –folder ein Verzeichnis (Default ist das das aktuelle Verzeichnis) und darin wird eine Datei mit Benutzern und eine für Gruppen verwaltet.
Es gibt ein wenig Comfort.
- Beim Löschen von Benutzern wird gewarnt, wenn dieser in Gruppen ist.
- Bei der Eingabe von Benutzernamen oder Gruppen gibt es eine Vervollständigung: mit der Tab-Taste kommt man schneller ans Ziel.
- Das Auflisten von Benutzern zeigt deren Gruppenzugehörigkit an - das Listing der Gruppen die Mitglieder.
- Eine Check-Funktion zeigt nicht existierende Gruppenmitglieder, User ohne Gruppen.
Dieses lässt sich mit SPC zu einem Binary compilieren. Für Linux werden vorcompilierte 64-Bit Binaries bereitgestellt. Im Projekt-Quellcode ist ein ./compiler/ Verzeichnis in dem der Download und Installation von SPC und das Compilieren zur ausfühtbaren Datei mitgeliefert wird.
Euer Hosting oder lokaler Rechner läuft mit Linux? Dann könnt ihr das Binary dorthin kopieren - nach Möglichkeit in ein Verzeichnis von $PATH. Und (nach SSH-Login) in der Konsole htpasswd- und htgroup-Dateien bearbeiten.
Euer Rechner/ Hosting hat PHP bereits an Bord? Dann kann man auch die gemergte PHP-Datei auf das Zielsystem kopieren und jenes auf der Konsole starten (per oder aber php )
Das Tool ist Freie Software unter GNU GPL 3 und kann kostenlos eingesetzt werden.
Weiterführende Links:
Do, 24. Juli, 2025
Ich habe so diverse Applikationen, die einen Passwortzugang für ein Backend benötigen.
Für so kleinere Sachen reicht eine .htpasswd-Datei und Basic Authentication. Um diese per PHP zu erzeugen und zu bearbeiten, habe ich keine geeignete Klassen gefunden … ergo schrieb ich sie mal selbst :-)
Das Projekt besteht aus je einer Klasse für die Verwaltung einer .htpasswd Datei und einer für die .htgroups. Sie können diese Dateien auslesen, Gruppen oder User hinzufügen oder aber löschen. Mit diesen PHP-Klassen kann man eine Benutzerverwaltung mit reinen PHP-Mitteln und ohne ein exec() der htpasswd Datei umsetzen.
Die Dokumentation enhält zudem Konfigurationsbeispiele verschiedener Szenarien für .htaccess Dateien.
Ich hoffe, der ein oder andere findet diese Klassen nützlich.
Weiterführende Links:
Mo, 21. Juli, 2025
Es hat 1.5 Jahre gebraucht vom ersten Entwurf bis zur Veröffentlichung. Scheinbar ist es komplizierter, als gedacht. Aber nun ist es vollbracht: der Artikel ist online.
Ich bin seit 12 Jahren am IML angestellt und erstmals sind Worte wie “Open source” oder “Freie Software” in einem Artikel unserer Instituts-Webseite aufgetaucht. Und das, obwohl seit über 10 Jahren in der Server-IT ausschliesslich Linux und Freie Software zum Einsatz kommt.
Was braucht es, um im Blick zu halten, ob die Infrastruktur rund läuft? Wir verwenden mehrere Monitoring-Werkzeuge für
- Logging
- Cronjobs
- System-Monitoring und
- Applikations-Monitoring
Das System-Monitoring Icinga2 ist unser zentraler Sammelpunkt, bei der Störungsinformationen zusammenfliessen - so hat man alles im Blick, ohne zwischen verschiedenen Fenstern (Tabs) hin- und herspringen zu müssen.
Wir setzen auf Freie Software und stellen im Umkehrzug Eigenentwicklungen als Freie Software zur Verfügung.
Am konkreten Beispiel unseres IT Monitorings wird das gelebte Prinzip von Nehmen und Geben beleuchtet.
Link: IML Webseite: IT-Monitoring mit “Freier Software”
Mi, 23. April, 2025
Hier ein weiterer Javascript-Schnipsel…
Manchmal möchte ich in einer webbasierten Admin eine Schaltfläche haben, die etwas löscht oder eine Aktion auslöst, die aber nicht mit einem GET Request ausgelöst werden können soll. Also mein A-Tag oder Button-Tag soll beispielsweise einen POST request auslösen und Parameter mitgeben können. Aber auch PUT oder DELETE Requests sind möglich.
Die nachfolgende Funktion führt einen Http-Request aus und zeigt den Output in einer DOM-ID oder aber bei Fehlen der ID im gesamten Browser-Fenster. Wobei Letzteres noch den schönen Effekt hat, dass ein F5 im Browser-Fenster den POST request nicht wiederholt.
/**
* Make an http request with given method, url, form data.
* The response can be shown in a given dom id or in the full browser window.
*
* @param {string} method http method; eg. GET, POST, PUT, …
* @param {string} url url to request
* @param {json} data request body as key -> value in a JSON
* @param {string} idOut optional: id of output element in DOM; default: write response in browser
* @return void
*/
async function httprequest(method=”GET”, url = ”", data = {}, idOut = null) {
// console.log(”httprequest(”+method+”, ”+url+”, ”+data+”, ”+idOut+”)”);
if (method == ”POST” || method == ”PUT”) {
var fd = new FormData();
for (var key in data) {
fd.append(key, data[key]);
}
} else {
var fd = null;
}
// Default options are marked with *
const response = await fetch(url, {
method: method, // *GET, POST, PUT, DELETE, etc.
mode: ”cors”, // no-cors, *cors, same-origin
cache: ”no-cache”, // *default, no-cache, reload, force-cache, only-if-cached
credentials: ”same-origin”, // include, *same-origin, omit
headers: {
// ”Content-Type”: ”application/json”,
// ’Content-Type’: ’application/x-www-form-urlencoded’,
// ’Content-Type’: ’multipart/form-data’,
},
redirect: ”follow”, // manual, *follow, error
referrerPolicy: ”no-referrer”, // no-referrer, *no-referrer-when-downgrade, origin, origin-when-cross-origin, same-origin, strict-origin, strict-origin-when-cross-origin, unsafe-url
body: fd, // body data type must match ”Content-Type” header
});
// return response.json(); // parses JSON response into native JavaScript objects
var responsebody = await response.text();
if (idOut) {
document.getElementById(idOut).innerHTML = responsebody;
} else {
document.open();
document.write(responsebody);
document.close();
}
}
Und so wird sie verwendet:
Nachfolgendes HTML-Snippet zeigt einen Button. Beim onclick-Event sehen wir die obige Funktion einmal eingebunden.
Man sieht
- die Http-Methode: POST
- die aufzurufende URL: die aktuelle - mittels location.href
- POST-Parameter: als JSON wird die Variable “action” mit dem Wert “backup” übergeben. Mit PHP liesse sich dies mit $_POST['’action’] lesen.
<button
class=”btn”
onclick=”httprequest(’POST’, location.href , {’action’: ’backup’})”
>Create new backup</button>
Die Funktion ist noch nicht featurecomplete. Sie kann noch erweitert werden, um Http-Request-Header mit zu übergeben. Aber ich hoffe, für den ein oder anderen ist sie bereits in dieser Form nützlich.
Weiterführende Links:
Mo, 16. Dezember, 2024
PHP 8.4 ist seit Ende November live.
Meine PHP-Klasse ahCache, die beliebige Daten (Strings, Hashes, Objekte) im lokalen Dateisystem cachen kann, ist hiermit offiziell PHP 8.4 kompatibel. Es musste lediglich eine Methode angepasst werden. Das war um Glück überschaubar.
Die Dokumentation wurde gleichsam umgestellt. Sie ist nun im Repository direkt enthalten und wird - wie schon eineige meiner anderen Projekte - mit Daux.io gerendert.
Weiterführende Linke
Do, 21. November, 2024
Mit Bash code ich diverse Sachen, um mir das Admin Leben zu vereinfachen.
Sobald man JSON Dateien oder JSON als API-Response vor sich hat, ist plattformübergreifend jq das Tool der Wahl für ein schnelles Pretty Print oder seinen starken Filter-Funktionen.
Wenn ich in einer Variable die komplette Liste hineinhole …
# Holen einer JSON-Liste
$OUT_TOKENS= $( curl $URL )
Für jeden Eintrag wünsche ich eine Verarbeitung. Mit seq kann ich von 1 .. N loopen. Die Anzahl der Elemente müssen wir uns daher zunächst einmal holen. Am enfachsten, wenn ich eine “id” oder einen anderen Key drin habe.
# IDs / Einträge zählen:
iTokenCount=$( jq ”.[].id ” < ”$OUT_TOKENS” | wc -l )
Mit einem jq Filter kann ich mir innerhalb der Schleife das N-te Element aus der Variable $OUT_TOKENS herausziehen, in eine eigene Variable legen und dann anschliessend jene zerlegen.
Snippet:
# einmal drüber loopen
for i in $( seq 1 $iTokenCount )
do
# get N-th token
entry=”$( jq ”.[$i]” < ”$OUT_TOKENS”)”
# …
done
Nehmen wir mal an, ich möchte aus jedem Listen-Eintrag den Key “name” auslesen. Und vielleicht noch einen 2. oder 3…
Dann schreibt man zunächst eine kleine Funktion
# Get a single value from json
# param string json data
# param string key
# return string
function getKey(){
jq -r ”.$2” <<< ”$1” | grep -v ”null”
}
… welche man dann innerhalb des Loops verwendet:
for i in $( seq 1 $iTokenCount )
do
# get N-th token
entry=”$( jq ”.[$i]” < ”$OUT_TOKENS”)”
sName=$( getKey ”$entry” ”name” )
if [ -z ”$sName” ]; then
continue
fi
sExpire=$( getKey ”$entry” ”expires_at” )
# …
done
Weiterführende Links