Do, 4. Juni, 2026
Restic [1] ist eine kommandozeilen-basierte Datensicherungssoftware, mit der Datei-Backups erstellt werden können. Backups werden lokal verschlüsselt. Als Ziel kann man Systeme mit unterschiedlichsten Protokollen anbinden: lokale Mounts, SSH-Verbindungen, S3, … und auch Http(s) zum Restic Rest Server [2].
Naja, genaugenommen nutze ich auf meinem Arbeitsrechner nicht plain den Restic Client, sondern einen Wrapper: IML Backup [3]. Bevor Restic anläuft, gibt es eine automatisierte Datenbank-Sicherung für Mysql/ Mariadb, Postgres, LDAP, CouchDB, Sqlite. Dieses Tool habe ich seit mehreren Jahren zur Daten-Sicherung von 200 Servern im Einsatz.
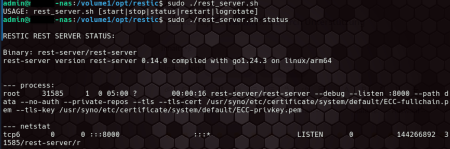
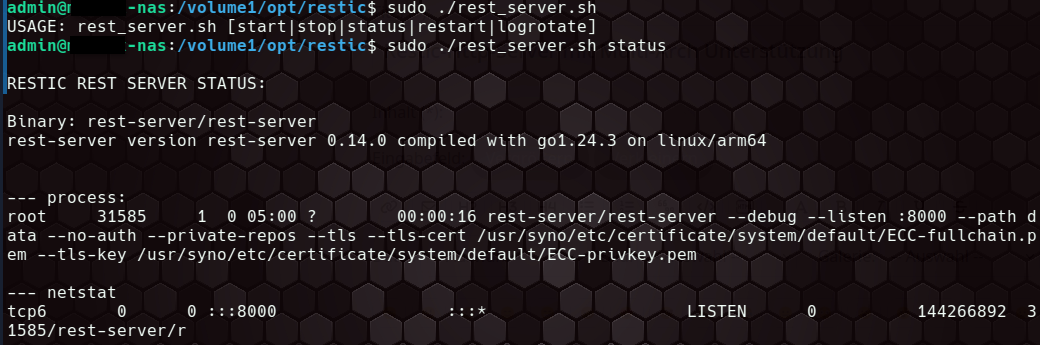
Mein Projekt “Restic Http Server on Synology NAS” [4] bietet eiinen Installer in Form eines Shellskripts für den Betrieb eines Restic Rest Server auf einem Synology NAS. Mit diesem Projekt habe ich daheim mein privates Synology NAS als Backup-Ziel der Rechner daheim eingerichtet. Es bringt noch kleine Helferleni mit.
- ein Server-Skript zur Handhabe des Restic-Servers: Starten, Stoppen, Status, Logrotation
- eine User-Verwaltung: User anlegen, Passwort setzen, User und dessen Daten löchen
Restic ist Freie Software … und meine Skripte sind es ebenso. Nachdem ich den Installer für die Arm64 Architektur ausgelegt habe, gab es nun vom User basti122303 einen Pull Request [5], der nun die Architekturen
von Synology Systemen erkennt.
Da es bei meinen Projekten bisher eher weniger Code-Beisteuerungen gab, freue ich mich über diese Erweiterung! Freie Software hat doch was Cooles! Cheers!
Weiterführende Links:
- https://restic.net/ - Restic Client (Windows, Mac, Linux und weitere)
- https://github.com/restic/rest-server - Restic Rest Http-Server
- https://os-docs.iml.unibe.ch/iml-backup/ - Restic Wrapper
- https://github.com/a … -server-for-synology - Installer für den Restic-Rest Server auf Synology
- https://github.com/a … -for-synology/pull/4 - Pull Request zur Unterstützung weiterer Architekturen
Mo, 1. September, 2025
Ich hatte mir jüngst Topgrade [1] installiert. Dies ist ein universeller System-Updater für Windows, Mac und etliche Linux Distributionen.
Ich war sofort happy - und so wurde es kurzerhand auf meinem Linux PC in einen Cronjob eingebunden.
Damit ich nicht im Blindflug bin, wollte ich per Desktop-Notifikation benachrichtigt werden. Folglich musste zusätzlich ein kleines Bash-Skript für einen Wrapper [2] her. Jener startet ganz einfach notfify-send vor und nach Ausführung von topgrade. Bei Beendigung mit Fehler bleibt der Hinweis bis Klick stehen. So verpasse ich auch bei Conjobs im Hintergrund keine fehlgeschlagenen Updates.
Das ist zu einfach :-)
Naja, fast. Der tricky Part ist: die Variable DBUS_SESSION_BUS_ADDRESS ist richtig zu belegen, dass eine Nachricht von einem eigentlich “leisen Hintergrund-Job” den Weg zum Desktop eines am Bildschirm sitzenden Benutzers findet. Shellskript-Bastler können sich das im Quellcode ansehen - für alle anderen funktioniert es halt out-of-the-box.
Weiterführende Links:
- Github: Topgrade (en)
- Github: Axels Topgrade-wrapper (en)
Do, 21. November, 2024
Mit Bash code ich diverse Sachen, um mir das Admin Leben zu vereinfachen.
Sobald man JSON Dateien oder JSON als API-Response vor sich hat, ist plattformübergreifend jq das Tool der Wahl für ein schnelles Pretty Print oder seinen starken Filter-Funktionen.
Wenn ich in einer Variable die komplette Liste hineinhole …
# Holen einer JSON-Liste
$OUT_TOKENS= $( curl $URL )
Für jeden Eintrag wünsche ich eine Verarbeitung. Mit seq kann ich von 1 .. N loopen. Die Anzahl der Elemente müssen wir uns daher zunächst einmal holen. Am enfachsten, wenn ich eine “id” oder einen anderen Key drin habe.
# IDs / Einträge zählen:
iTokenCount=$( jq ”.[].id ” < ”$OUT_TOKENS” | wc -l )
Mit einem jq Filter kann ich mir innerhalb der Schleife das N-te Element aus der Variable $OUT_TOKENS herausziehen, in eine eigene Variable legen und dann anschliessend jene zerlegen.
Snippet:
# einmal drüber loopen
for i in $( seq 1 $iTokenCount )
do
# get N-th token
entry=”$( jq ”.[$i]” < ”$OUT_TOKENS”)”
# …
done
Nehmen wir mal an, ich möchte aus jedem Listen-Eintrag den Key “name” auslesen. Und vielleicht noch einen 2. oder 3…
Dann schreibt man zunächst eine kleine Funktion
# Get a single value from json
# param string json data
# param string key
# return string
function getKey(){
jq -r ”.$2” <<< ”$1” | grep -v ”null”
}
… welche man dann innerhalb des Loops verwendet:
for i in $( seq 1 $iTokenCount )
do
# get N-th token
entry=”$( jq ”.[$i]” < ”$OUT_TOKENS”)”
sName=$( getKey ”$entry” ”name” )
if [ -z ”$sName” ]; then
continue
fi
sExpire=$( getKey ”$entry” ”expires_at” )
# …
done
Weiterführende Links
Do, 13. Juni, 2024
Am 5. und 6. Juni fand in Berlin die Icinga Summit 2024 statt.
Es waren 2 angenehme Tage, um sich mit anderen zu Monitoring & mehr auszutauschen.
Meine erste Rede auf englisch vor “grossem” Publikum lief dann doch besser, als gedacht. Anschliessend kamen mehrere Leute auf mich zu, um mir nach dem im Vortrag Gehörtem noch Tipps mit auf den Weg zu geben. Das ist doch sympathisch!
Weiterführende Links:
- https://icinga.com/summit/]icinga.com/summit/ (Seite wurde deaktiviert)
Do, 21. März, 2024
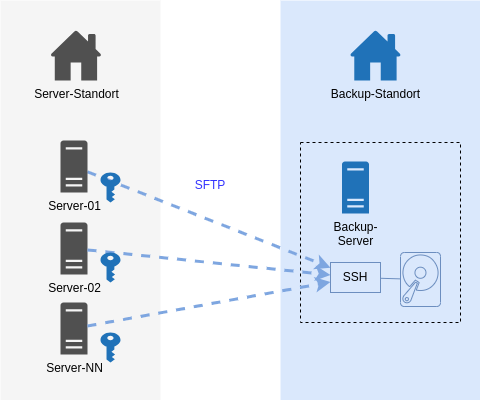
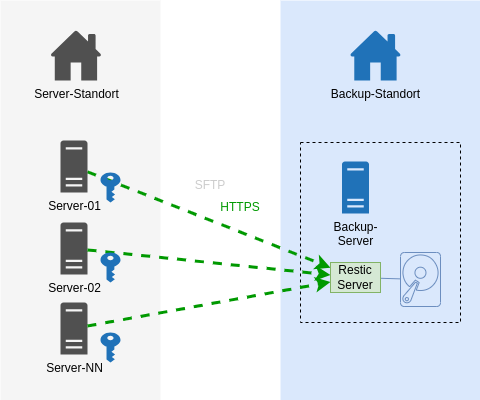
Unser Server Backup mit dem IML Backup [1] am Institut mit 150+ Systemen lief über Jahre mit Restic [2] und via SFTP zu einem Storage. Mit Restic bin ich soweit sehr zufrieden: es verschlüsselt Daten lokal vor der Übertragung und muss nach einem Initialbackup nur noch inkrementelle Backups machen. Auch das Restore von einzelnen Dateien und Ordnern hat uns nie im Stich gelassen. Insbesondere das Mounten mit Fuse ist ein hilfreiches Feature.
Dann sah ich im Januar 2024 das Videos des CCC [3]. Auf der “wichtigsten Folie des ganze Vortrags” waren Anforderungen an Backups gelistet, um sich gut gegen Ransomware-Verschlüsselungen der Infrastruktur zu wappnen. Bei vielen Punkten waren wir demnach bereits gut gewappnet. Aber es gab unschöne Schwachpunkte. Da diese jeweils eine Rechteausweitung als root voraussetzen, war dies mit “kalkulierten Risiko”.
Ein System kann seine eigenen Backup-Daten löschen.
Damit Backups nicht übermässig gross werden, werden alle N Tage im Anschluss des backups alte Daten älter 180 Tage gelöscht. Wenn ein Sysem gekapert plus der root-Account erreicht würde, kann durch böswilliges Setzen eines Delta statt 180 Tage auf 0 Tage setzend ist so ziemlich alles weggeputzt werden.
Ein System kann theoretisch Backups anderer Systeme löschen.
Bei Einbruch und Rechteausweitung auf root könnte wäre Folgendes denkbar: alle Systeme schreiben auf das Backup-Ziel mit demselben SSH-User. Auf der Zielseite gehören die Dateien demselben User und thoretisch könnte ein System Zugriff auf Backup-Daten eines anderen Systems erhalten und diese zwar nicht entschlüsseln, aber wg. Schreibrechten eben auch löschen.
Es geht nun auch besser.
Auf dem Backup-Endpoint wurde nun der Restic-Rest-Server [4] installiert, der als Systemd Service eingerichtet wurde. Die Backup-Clients kommunizieren nun statt via SSH mit HTTPS. Sie teilen nicht mehr den auf allen Systemen gleichen privaten SSH-Schlüssel.
In den Startparametern des Rest-Servers wurden diese Optionen aufgenommen, um folgende Härtungen zu erreichen:
Ein User (Server) darf nur sein eigenes Repository beschreiben.
Option:
–private-repos
Das Unterbindet das Ausbrechen auf Backup-Daten anderer Systeme.
Jeder Backup-Client (unsere Server) bekommt einen eigenen User und ein eigenes Http-Auth Passwort zugewiesen.
Auf dem Restic Rest Server werden Usernamen und das verschlüsselte Passwort in eine .htpasswd eingetragen.
Stolperfalle: Es böte sich an, die Benutzer gleich zu benennen, wie den Server. Eine Limitierung in der der .htpasswd lässt einen Punkt im Benutzernamen jedoch nicht zu. Aber das Ersetzen des Punkts im FQDN durch einen Unterstrich führt zu keinerlei Überschneidungen. Dem schliest sich an, dass das Backup-Verzeichnis nun statt [Backup-Dir]/ nun [Backup-Dir]/ ist. Bei der Umstellung von SSH auf HTTPS muss somit das Backup-Ziel-Verzeichnis beim Backup-Server umbenannt werden.
Ein User (Server) darf Daten nur anhängen.
Option:
–append-only
Kurz: Löschen ist nicht mehr möglich. Das klingt sicher.
Der Pferdefuss: unser auf jedem Einzelsystem befindliche Restic Prune Job zum Löschen älter N Tage funktioniert so nicht mehr. Ich habe es auch probiert: es wird mit einem 40x Statuscode zurückgewiesen.
Unsere Abhilfe sieht wie folgt aus: auf dem Backup-Zielserver läuft nun ein Cronjob, der über alle Backup-Repos das Pruning macht [4]. Wir lassen es erkennen, wie alt das letzte Prubg war und pausieren das Prune auf ein Repository dann für N Tage. Damit Restic auf Inhalte zugreifen kann, muss das Passwort zum Entschlüsseln aller Serverdaten für das Skript greifbar sein. Wir generieren mit Ansible eine Konfigurationsdatei, die alle Benutzernamen und Restic-Verschlüsselungspasswörter am Backup-System niederschreibt. Diese Datei gehört root:root und hat die Rechte 0400.
Zustand NEU:
Das Ergebnis ist derselbe Datenfluss - nur mit einem anderen Protokoll - Https statt ssh. Entscheidend sind die 2 o.g. Optionen für den Restic Server auf dem Backup-Ziel.
Dies war eine Beschreibung mit hoher Flughöhe mit weniger technischen Details. Bei Fragen nutzt gern die Kommentarfunktion oder fragt mich an.
Weiterführende Links:
- Docs: IML Backup (en)
- Github: Restic (en)
- CCC Dez 2023: Hirne hacken - Hackback Edition
- Github: Restic REST Server (en)
- os-docs.iml.unibe.ch: rest-pruner.sh (en)
Fr, 25. August, 2023
Ich skripte meine Dinge hauptsächlich in Bash.
Und weil niemand etwas nutzt, was nicht dokumentiert ist, habe ich 2 neue Dokumentationen online gestellt:
(1)
Kürzlich habe ich eine Bash-Komponente geschrieben, die die Handhabe der ANSI Farben vereinfacht.
Man kann eingfach Farben für Vordergrund und Hintergrund setzen - mit Namen einer Farbe oder HTML-CSS-Farbangabe.
Doc zu bash_colorfunctions
Rein zur Veranschaulichung: damit kann man farbige Texte ausgeben mit
color.echo ”white” ”green” ”Yep, it seems to work!”
… oder aber die Farbe nur setzen, um nachfolgende Kommandos in jener Farbe die Ausgabe machen zu lassen. Zum Aufheben der Farbdefinition ruft man ein color.reset auf:
color.fg ”blue”
ls -l
color.reset
(2)
Schon einige Monate auf Github ist mein Projekt, das mit Hilfe eines lokal installiertten Nginx den Zugriff auf eine Webapplikation als Docker Container mit Https und mit Namen der Applikation ansprechen lässt.
Doc zu nginx-docker-proxy
Beide Projekte sind freie Software und Opensource.
Do, 25. Mai, 2023
Wie oft ich das schon im Linux Filesystem gebraucht habe: in einem aktuellen oder angegebenen Verzeichnis prüfen, ob der Linux-Benutzer XY bis dorthin “durchkommt” und Berechtigungen in einem Verzeichnis oder auf eine Datei hat.
Also schrieb ich ein Shellskript. Man ruft es mit einem Parameter für ein zu prüfendes Verzeichnisses auf. Oder ohne Parameter für das aktuelle Verzeichnis.
Ich fange mal mit dessen Ausgabe an:
$ lsup
drwxr-xr-x 1 root root 244 Apr 2 23:34 /
drwxr-xr-x 1 root root 100 Jun 4 2022 /home
drwx—— 1 axel autologin 1.7K May 25 18:17 /home/axel
drwxr-xr-x 1 axel autologin 232 May 25 19:50 /home/axel/tmp
Ab dem Root-Verzeichnis werden mit ls -ld alle Verzeichnisebenen bis zum angegebenen Punkt angezeigt.
Syntax:
$ lsup -h
===== LSUP v1.3 :: make an ls upwards … =====
Show directory permissions above by walking from / to the given file.
You can add no or one or multiple files as params.
SYNTAX:
lsup Walk up from current directory
lsup FILE [FILE N] Walk up from given file/ directory
If the target is relative it will walk up
to the current directory
lsup -h Show this help and exit
EXAMPLES:
lsup
lsup .
lsup /var/log/
lsup my/relative/file.txt
lsup /home /tmp /var
Zur Installation: als User root;: cd /usr/bin/ und nachfolgenden Code in eine Datei namens “lsup” werfen und ein chmod 0755 lsup hinterher.
#!/usr/bin/env bash
# ======================================================================
#
# Make an ls -d from root (/) to given dir to see directory
# permissions above
#
# ———————————————————————-
# 2020-12-01 v1.0 Axel Hahn
# 2023-02-06 v1.1 Axel Hahn handle dirs with spaces
# 2023-02-10 v1.2 Axel Hahn handle unlimited spaces
# 2023-03-25 v1.3 Axel Hahn fix relative files; support multiple files
# ======================================================================
_version=1.3
# ———————————————————————-
# FUNCTIONS
# ———————————————————————-
function help(){
local self=$( basename $0 )
cat <<EOH
===== LSUP v$_version :: make an ls upwards … =====
Show directory permissions above by walking from / to the given file.
You can add no or one or multiple files as params.
SYNTAX:
$self Walk up from current directory
$self FILE [FILE N] Walk up from given file/ directory
If the target is relative it will walk up
to the current directory
$self -h Show this help and exit
EXAMPLES:
$self
$self .
$self /var/log/
$self my/relative/file.txt
$self /home /tmp /var
EOH
}
# ———————————————————————-
# MAIN
# ———————————————————————-
if [ ”$1” = ”-h” ]; then
help
exit 0
fi
test -z ”$1” && ”$0” ”$( pwd )”
# loop over all given params
while [ $# -gt 0 ]; do
# param 1 with trailing slash
mydir=”${1%/}”
if ! echo ”$mydir” | grep ”^/” >/dev/null; then
mydir=”$( pwd )/$mydir”
fi
ls -ld ”$mydir” >/dev/null 2>&1 || echo ”ERROR: File or directory does not exist: $mydir”
ls -ld ”$mydir” >/dev/null 2>/dev/null || exit 1
mypath=
arraylist=()
arraylist+=(’/')
IFS=”/” read -ra aFields <<< ”$mydir”
typeset -i iDepth=${#aFields[@]}-1
for iCounter in $( seq 1 ${iDepth})
do
mypath+=”/${aFields[$iCounter]}”
arraylist+=( ”${mypath}” )
done
# echo ”>>>>> $mypath”
eval ”ls -lhd ${arraylist[*]}”
shift 1
test $# -gt 0 && echo
done
# ———————————————————————-
Viel Spass damit!
Mi, 10. Mai, 2023
Ich brauchte da auf die Schnelle mal was: ich wollte mehrere Systeme mit Ping antesten, ob sie im Netz sind.
Die Liste der zu testenden Systeme sollte untereinander stehen und pro System angeben; ich bin erreichbar … oder auch nicht.
Ja natürlich haben wir ein System-Monitoring, aber das ist etwas träge - ich wollte das Ganze alle wenige Sekunden aktualisieren. Im Rack wollte ich Kabel ziehen und umstecken - und nebenher sehen, welches Gerät offline geht und wieder da ist.
Hier mein Bash-Skript:
#!/bin/bash
cfgfile=”$0.cfg”
while true; do
clear
echo ”>>>>> PING TEST :: $( date )”
echo
cat ”$cfgfile” | grep ”^[a-z1-9]” | while read -r target
do
printf ”%-35s > ” $target
if ! ping -c1 $target 2>&1 | grep ”transmitted”; then
echo ”FAILED”
fi
done
sleep 1
done
Im Endlos-Loop wird der Bildschirm gelöscht, ein Header mit Datum ausgegeben. Ich lese eine Datei aus, die meine Liste von Geräten enthält.
Ein Gerät wird einmalig angepingt (Parameter -c 1) - genau das geht sehr schnell. Es wird ausgegeben, ob es erreichbar war oder nicht.
Nach Abarbeiten der Liste folgt ein sleep 1 - und nach dieser nur kurzen Wartezeit geht es von vorn los.
Die Configdatei mit der Liste der Server - je einer pro Zeile - Leerzeilen, Kommentare u.ä werden ignoriert:
#
# my server list
#
server-01.example.com
server-02.example.com
server-03.example.com
server-04.example.com
server-05.example.com
Das Ganze sieht in der Ausgabe am Terminal grob aus:
>>>>> PING TEST :: Mi 10 Mai 2023 16:37:41 CEST
server-01.example.com > 1 packets transmitted, 1 received, 0% packet loss, time 0ms
server-02.example.com > 1 packets transmitted, 1 received, 0% packet loss, time 0ms
server-03.example.com > 1 packets transmitted, 1 received, 0% packet loss, time 0ms
server-04.example.com > 1 packets transmitted, 1 received, 0% packet loss, time 0ms
server-05.example.com > FAILED
So, 16. April, 2023
Mein Backup-Skript (es dumpt lokale Datenbanken, unterstützt zig Hooks, sichert mit Restic/ Duplicity) kennt einen neuen Trick.
Auf meinem Linux-Desktop wollte ich Popup-Informationen zu einem im Hintergrund (Cronjob als root) gestarteten Skript sehen.
Und wie geht das?
Eine gängige Lösung ist notify-send (aus dem Paket libnotify).
$ notify-send –help
Usage:
notify-send [OPTION?] <SUMMARY> [BODY] - create a notification
Help Options:
-?, –help Show help options
Application Options:
-u, –urgency=LEVEL Specifies the urgency level (low, normal, critical).
-t, –expire-time=TIME Specifies the timeout in milliseconds at which to expire the notification.
-a, –app-name=APP_NAME Specifies the app name for the icon
-i, –icon=ICON Specifies an icon filename or stock icon to display.
-c, –category=TYPE[,TYPE…] Specifies the notification category.
-e, –transient Create a transient notification
-h, –hint=TYPE:NAME:VALUE Specifies basic extra data to pass. Valid types are boolean, int, double, string, byte and variant.
-p, –print-id Print the notification ID.
-r, –replace-id=REPLACE_ID The ID of the notification to replace.
-w, –wait Wait for the notification to be closed before exiting.
-A, –action=[NAME=]Text… Specifies the actions to display to the user. Implies –wait to wait for user input. May be set multiple times. The name of the action is output to stdout. If NAME is not specified, the numerical index of the option is used (starting with 0).
-v, –version Version of the package.
Das funktioniert problemlos im Kontext des aktuell eingeloggten Benutzers mit einer X-Session.
Aber mit sudo oder als Cronjob als root?
Aber eines nach dem Anderen.
Wenn ich ein Skript mit sudo starte, dann enthält die Umgebungsvariable SUDO_USER denjenigen Benutzer, der das sudo ausgelöst hat. Das Skript läuft dann als User root. Das notify-send soll aber nicht auf einer X-Session des root Users etwas enblenden, sondern einem anderen unprivilegierten Benutzer. Hier kommt die Variable DBUS_SESSION_BUS_ADDRESS ins Spiel. Wenn man die UID des Benutzers kennt, kann man es sich zusammensetzen. Diese bekommt man mit id -u [Benutzername] … und der Benutzername ist ja in SUDO_USER.
Snippet:
if [ -n ”$SUDO_USER” ]; then
export DBUS_SESSION_BUS_ADDRESS=unix:path=/run/user/$(id -u $SUDO_USER)/bus
fi
Mit jenem Snippet kann man im selben Skript auslösen
su ”$SUDO_USER” -c ”notify-send ’Titel’ ’Mein Nachrichtentext’”
und es kommt bei … genau: “meinem” Desktop an und nicht bei root. Wunderbar!
Jetzt ist da noch die Sache mit dem Cronjob als root. Hier ist ja kein sudo. Aber das ist gar banaler als man denkt: man setzt einfach die Variable SUDO_USER im Environment - also vor den Deinitionen der Zeitangaben und Aufrufe:
$cat /etc/cron.d/client-backup
SUDO_USER=axel
17 * * * * root /usr/local/bin/cronwrapper.sh 1440 /opt/imlbackup/client/backup.sh ’iml-backup’
Feintuning:
ein Simples notify-send “Titel” “Mein Nachrichtentext” verschwindet nach ein paar Sekunden. Wenn ein Fehler auftritt, dann möchte ich die Meldung sehen, lesen und proaktiv verschwinden lassen. Genau das erledigt der Parameter –urgency für uns
notify-send –urgency=critical “Fehler” “Da ging etwas schief :-/”
Hier noch ein kompletteres Bash Snippet:
if [ -n ”$SUDO_USER” ]; then
export DBUS_SESSION_BUS_ADDRESS=unix:path=/run/user/$(id -u $SUDO_USER)/bus
fi
(…)
# show a desktop notification using notify-send
# param string summary (aka title)
# param string message text
# paran integer optional: exitcode; if set it adds a prefix OK or ERRROR on summary and sets urgency on error
function notify(){
local _summary=”$1”
local _body=”$( date +%H:%M:%S ) $2”
local _rc=”$3”
local _urgency=”normal”
if [ -n ”$DBUS_SESSION_BUS_ADDRESS” ]; then
if [ -n ”$_rc” ]; then
if [ ”$_rc” = ”0” ]; then
_summary=”OK: ${_summary}”
else
_summary=”ERROR: ${_summary}”
_urgency=”critical”
fi
fi
su ”$SUDO_USER” -c ”notify-send –urgency=${_urgency} ’${_summary}’ ’${_body}’”
fi
}
Mi, 8. Februar, 2023
Wir lassen diverse Applikationen mit Ansible von einem Git-Repository installieren. Etwa so:
- name: ’install - Clone repo {{ repo_url }}’
ansible.builtin.git:
repo: ’{{ repo_url }}’
dest: ’{{ install_dir }}’
Dummerweise kommt dann noch ein Verschenken der Berechtigungen hinterher.
Seit Kurzem - mit einer neueren Git Version - häufen sich Abbrüche beim Git pull
detected dubious ownership in repository
Und auch die Lösung wird in der Fehlermeldung mitgegeben:
git config –global –add safe.directory [Verzeichnis]
Ja denn … packen wir doch einen Schnipsel hierfür dazu:
# set install dir as safedir …
- name: ”FIX - add installdir {{ install_dir }} as safedir”
ansible.builtin.shell: |
git config –global –get-all safe.directory \
| grep ”{{ install_dir }}” \
|| git config –global –add safe.directory ”{{ install_dir }}”
Wenn es ein paar mehr Server sind, sollte man sich das in in eine Rolle verpacken, um es etwas abstrakter zu halten.
Zum Reparieren packt man es zur einmaligen Ausführung des Playbooks VOR das ansible.builtin.git … aber dann gehört es dahinter.
Der Shell-Aufruf präft, ob der Pfad bereits aufgenommen ist - nur wenn nicht, wird er hinzugefügt. Ansonsten würde ein mehrfaches “add” zu zigfachen Duplikaten desselben Pfades führen.