Mo, 29. Juni, 2026
Das Blog Tool Flatpress [1] nutze ich schon Ewigkeiten… naja, und bei so vielen bereits geschriebenen Artikeln bleibe ich auch dabei. Es gab vor einigen Jahren eine Durststrecke, weil es nicht weiterentwickelt wurde. Aber zum Glück fanden sich Maintainer, die das Projekt weiterführen.
Gern unterstütze ich es auf meine Weise. Nun habe ich mein erstes Flatpress-Plugin [2] geschrieben, damit ich im Backend des Blogs bei Select-Boxen einen Textfilter zum schnelleren Auffinden von Einträgen aktiviere. Mein Plugin aktiviert dazu die jQuery Bibliothek Select2 [3].
Nach Aktivierung in Flatpress sieht das so aus: In einer Filterbox im Backen tippe einige Zeichen, um die Auswahl zu reduzieren.
Das Plugin wurde gleichsam im Wiki von Flatpress angemeldet [4]. Damit sollten es Suchende auch am entsprechenden Ort finden.
Weiterführende Links:
- www.flatpress.org Blog tool
- Github: Sourcecode und Readme zur Installation
- select2.org jQuery Plugin Select2
- wiki.flatpress.org Seite zum Plugin im Flatpress Wiki
Source:
Do, 4. Juni, 2026
Restic [1] ist eine kommandozeilen-basierte Datensicherungssoftware, mit der Datei-Backups erstellt werden können. Backups werden lokal verschlüsselt. Als Ziel kann man Systeme mit unterschiedlichsten Protokollen anbinden: lokale Mounts, SSH-Verbindungen, S3, … und auch Http(s) zum Restic Rest Server [2].
Naja, genaugenommen nutze ich auf meinem Arbeitsrechner nicht plain den Restic Client, sondern einen Wrapper: IML Backup [3]. Bevor Restic anläuft, gibt es eine automatisierte Datenbank-Sicherung für Mysql/ Mariadb, Postgres, LDAP, CouchDB, Sqlite. Dieses Tool habe ich seit mehreren Jahren zur Daten-Sicherung von 200 Servern im Einsatz.
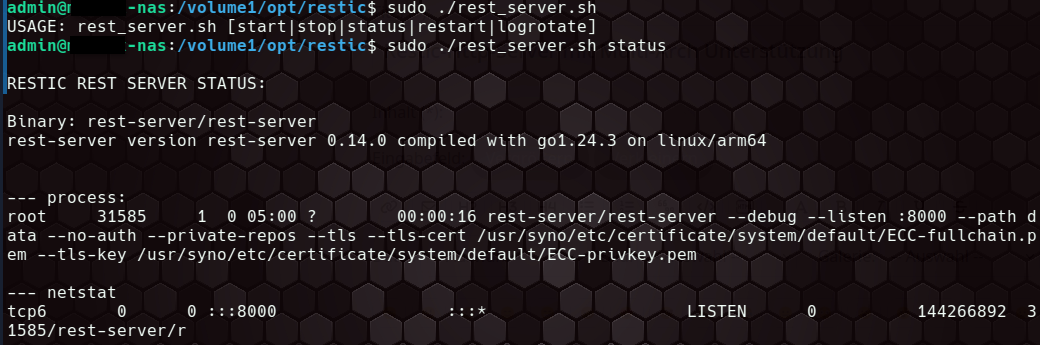
Mein Projekt “Restic Http Server on Synology NAS” [4] bietet eiinen Installer in Form eines Shellskripts für den Betrieb eines Restic Rest Server auf einem Synology NAS. Mit diesem Projekt habe ich daheim mein privates Synology NAS als Backup-Ziel der Rechner daheim eingerichtet. Es bringt noch kleine Helferleni mit.
- ein Server-Skript zur Handhabe des Restic-Servers: Starten, Stoppen, Status, Logrotation
- eine User-Verwaltung: User anlegen, Passwort setzen, User und dessen Daten löchen
Restic ist Freie Software … und meine Skripte sind es ebenso. Nachdem ich den Installer für die Arm64 Architektur ausgelegt habe, gab es nun vom User basti122303 einen Pull Request [5], der nun die Architekturen
von Synology Systemen erkennt.
Da es bei meinen Projekten bisher eher weniger Code-Beisteuerungen gab, freue ich mich über diese Erweiterung! Freie Software hat doch was Cooles! Cheers!
Weiterführende Links:
- https://restic.net/ - Restic Client (Windows, Mac, Linux und weitere)
- https://github.com/restic/rest-server - Restic Rest Http-Server
- https://os-docs.iml.unibe.ch/iml-backup/ - Restic Wrapper
- https://github.com/a … -server-for-synology - Installer für den Restic-Rest Server auf Synology
- https://github.com/a … -for-synology/pull/4 - Pull Request zur Unterstützung weiterer Architekturen
So, 29. März, 2026
Als Blog [1] Software nutze eine halbe Ewigkeit Flatpress [2].
Mittlerweile ist dieser bei Verion 1.5 angekommen und auch mit aktuellen PHP Versionen kompatibel. Es wurde Zeit, dass ich mal wieder ein Update angehe…
Unter der Haube gibt es eine neue Smarty Version als Template Engine, weshalb mein bisheriges Theme nicht mehr läuft. Kurzerhand wurde das Default-Theme hergenommen, jenes farbärmer gemacht und auf ganze Bildschirmbreite gestreckt. Noch ist es mehr ein Hack, als ein sauber aufgezogenes Theme. Vielleicht schiebe ich es mal später nach notwendigen Aufräumarbeiten hinterher.
Weiterführende Links:
- www.axel-hahn.de/blog/ - Axels Blog
- flatpress.org - Leichtgewichtiges Blogging Tool ohne Datenbank, GNU GPL
Mo, 1. September, 2025
Ich hatte mir jüngst Topgrade [1] installiert. Dies ist ein universeller System-Updater für Windows, Mac und etliche Linux Distributionen.
Ich war sofort happy - und so wurde es kurzerhand auf meinem Linux PC in einen Cronjob eingebunden.
Damit ich nicht im Blindflug bin, wollte ich per Desktop-Notifikation benachrichtigt werden. Folglich musste zusätzlich ein kleines Bash-Skript für einen Wrapper [2] her. Jener startet ganz einfach notfify-send vor und nach Ausführung von topgrade. Bei Beendigung mit Fehler bleibt der Hinweis bis Klick stehen. So verpasse ich auch bei Conjobs im Hintergrund keine fehlgeschlagenen Updates.
Das ist zu einfach :-)
Naja, fast. Der tricky Part ist: die Variable DBUS_SESSION_BUS_ADDRESS ist richtig zu belegen, dass eine Nachricht von einem eigentlich “leisen Hintergrund-Job” den Weg zum Desktop eines am Bildschirm sitzenden Benutzers findet. Shellskript-Bastler können sich das im Quellcode ansehen - für alle anderen funktioniert es halt out-of-the-box.
Weiterführende Links:
- Github: Topgrade (en)
- Github: Axels Topgrade-wrapper (en)
Do, 14. August, 2025
Um ein Web oder ein Verzeichnis mit Username und Passwort zu schützen, kann man mit Basic Authentication arbeiten. Man kann Benutzer oder Gruppen berechtigen, eine Seite zu öffnen.
Dazu hatte ich kürzlich 2 PHP Klassen zum Verwalten von htpasswd- und htgroup-Dateien veröffentlicht. Diese kann man in Programmierprojekten einsetzen.
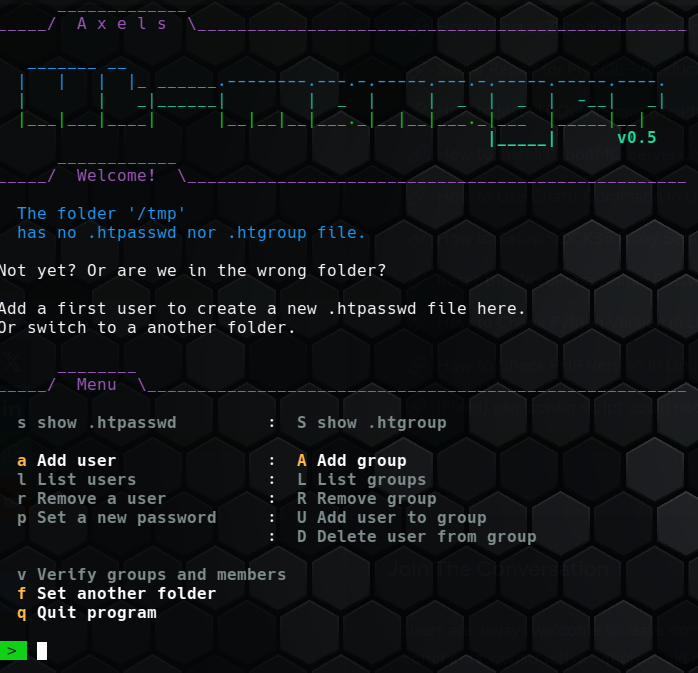
Nun habe ich mit jenen Klassen ein Konsolen-Werkzeug in PHP geschrieben, um Benutzer und Gruppen auf etwas bequemere Art und interaktiv im Terminal zu verwalten. Das Tool benötigt keinerlei fremde Werkzeuge, wie openssl oder htpasswd, um die Benutzerpasswörter zu erstellen.
Und so sieht das Ganze aus:
Mit -h oder –help sieht man die unterstützten Parameter. Man wählt mit –folder ein Verzeichnis (Default ist das das aktuelle Verzeichnis) und darin wird eine Datei mit Benutzern und eine für Gruppen verwaltet.
Es gibt ein wenig Comfort.
- Beim Löschen von Benutzern wird gewarnt, wenn dieser in Gruppen ist.
- Bei der Eingabe von Benutzernamen oder Gruppen gibt es eine Vervollständigung: mit der Tab-Taste kommt man schneller ans Ziel.
- Das Auflisten von Benutzern zeigt deren Gruppenzugehörigkit an - das Listing der Gruppen die Mitglieder.
- Eine Check-Funktion zeigt nicht existierende Gruppenmitglieder, User ohne Gruppen.
Dieses lässt sich mit SPC zu einem Binary compilieren. Für Linux werden vorcompilierte 64-Bit Binaries bereitgestellt. Im Projekt-Quellcode ist ein ./compiler/ Verzeichnis in dem der Download und Installation von SPC und das Compilieren zur ausfühtbaren Datei mitgeliefert wird.
Euer Hosting oder lokaler Rechner läuft mit Linux? Dann könnt ihr das Binary dorthin kopieren - nach Möglichkeit in ein Verzeichnis von $PATH. Und (nach SSH-Login) in der Konsole htpasswd- und htgroup-Dateien bearbeiten.
Euer Rechner/ Hosting hat PHP bereits an Bord? Dann kann man auch die gemergte PHP-Datei auf das Zielsystem kopieren und jenes auf der Konsole starten (per oder aber php )
Das Tool ist Freie Software unter GNU GPL 3 und kann kostenlos eingesetzt werden.
Weiterführende Links:
Do, 24. Juli, 2025
Ich habe so diverse Applikationen, die einen Passwortzugang für ein Backend benötigen.
Für so kleinere Sachen reicht eine .htpasswd-Datei und Basic Authentication. Um diese per PHP zu erzeugen und zu bearbeiten, habe ich keine geeignete Klassen gefunden … ergo schrieb ich sie mal selbst :-)
Das Projekt besteht aus je einer Klasse für die Verwaltung einer .htpasswd Datei und einer für die .htgroups. Sie können diese Dateien auslesen, Gruppen oder User hinzufügen oder aber löschen. Mit diesen PHP-Klassen kann man eine Benutzerverwaltung mit reinen PHP-Mitteln und ohne ein exec() der htpasswd Datei umsetzen.
Die Dokumentation enhält zudem Konfigurationsbeispiele verschiedener Szenarien für .htaccess Dateien.
Ich hoffe, der ein oder andere findet diese Klassen nützlich.
Weiterführende Links:
Mo, 21. Juli, 2025
Es hat 1.5 Jahre gebraucht vom ersten Entwurf bis zur Veröffentlichung. Scheinbar ist es komplizierter, als gedacht. Aber nun ist es vollbracht: der Artikel ist online.
Ich bin seit 12 Jahren am IML angestellt und erstmals sind Worte wie “Open source” oder “Freie Software” in einem Artikel unserer Instituts-Webseite aufgetaucht. Und das, obwohl seit über 10 Jahren in der Server-IT ausschliesslich Linux und Freie Software zum Einsatz kommt.
Was braucht es, um im Blick zu halten, ob die Infrastruktur rund läuft? Wir verwenden mehrere Monitoring-Werkzeuge für
- Logging
- Cronjobs
- System-Monitoring und
- Applikations-Monitoring
Das System-Monitoring Icinga2 ist unser zentraler Sammelpunkt, bei der Störungsinformationen zusammenfliessen - so hat man alles im Blick, ohne zwischen verschiedenen Fenstern (Tabs) hin- und herspringen zu müssen.
Wir setzen auf Freie Software und stellen im Umkehrzug Eigenentwicklungen als Freie Software zur Verfügung.
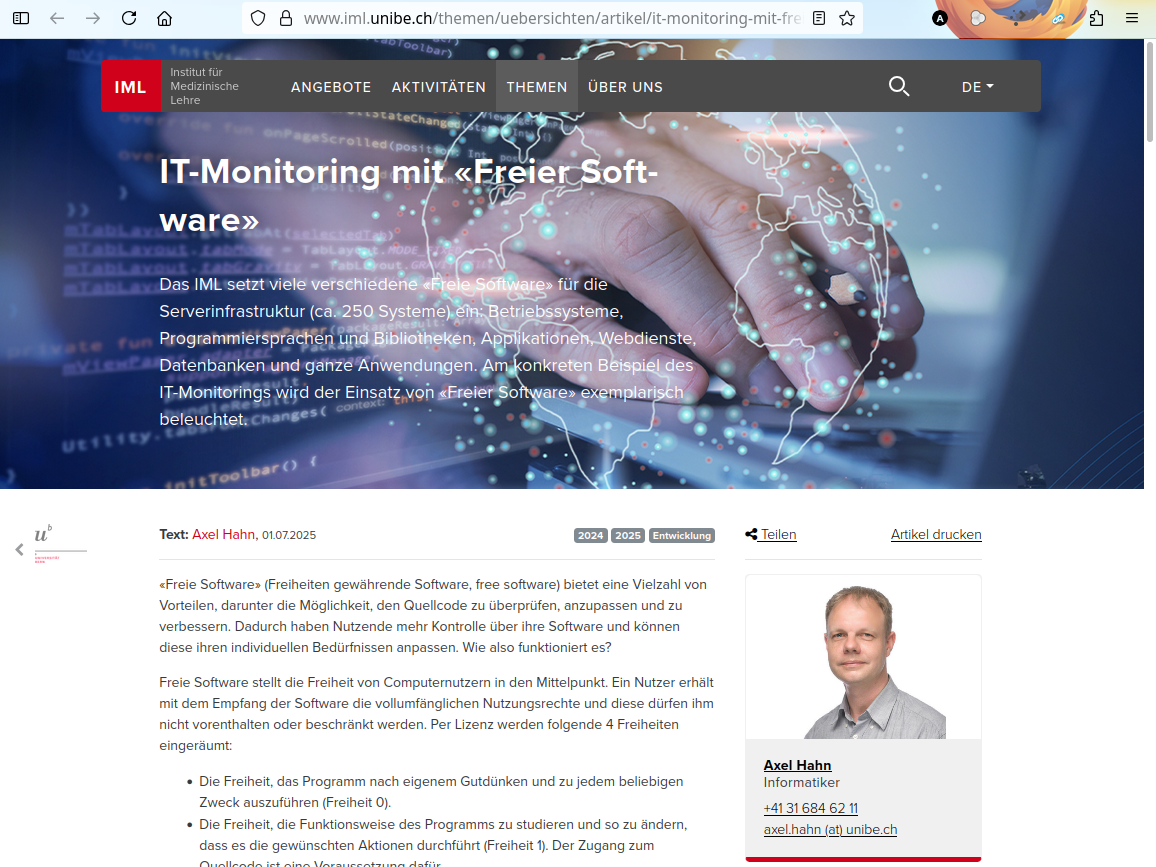
Am konkreten Beispiel unseres IT Monitorings wird das gelebte Prinzip von Nehmen und Geben beleuchtet.
Link: IML Webseite: IT-Monitoring mit “Freier Software”
Mi, 23. Oktober, 2024
Ich habe für diverse Projekte eine PHP-Entwicklungsumgebung. Mittlerweile als Docker Container.
Wenn meine Applikation in der Live Umgebung Emails versendet - wie gehe ich damit in der Dev-Umgebung um?
Ich wollte einen Email-Catcher haben, der statt Sendmail oder Postfix die Emails zu versenden, für mich abfängt.
Zum Glück ist das nicht soo schwer, dies ohne weitere Abhängigkeiten zu coden. So entstanden eine PHP-Klasse und 2 Skripte: eines, um die Emails vom STDIN einzufangen - und ein Viewer.
Ganz wichtig: es musste einfach zu verwenden sein! Voila: die Konfiguration besteht aus einer Zeile in der php.ini.
Wenn du in einer PHP Enwicklungsumgebung die versendeten Email abfangen und lesen willst: hier ist ein quick winner!
📜 License: GNU GPL 3.0
📄 Source: https://git-repo.iml … rce/php-emailcatcher
📗 Docs: https://os-docs.iml. … ch/php-emailcatcher/ (en)
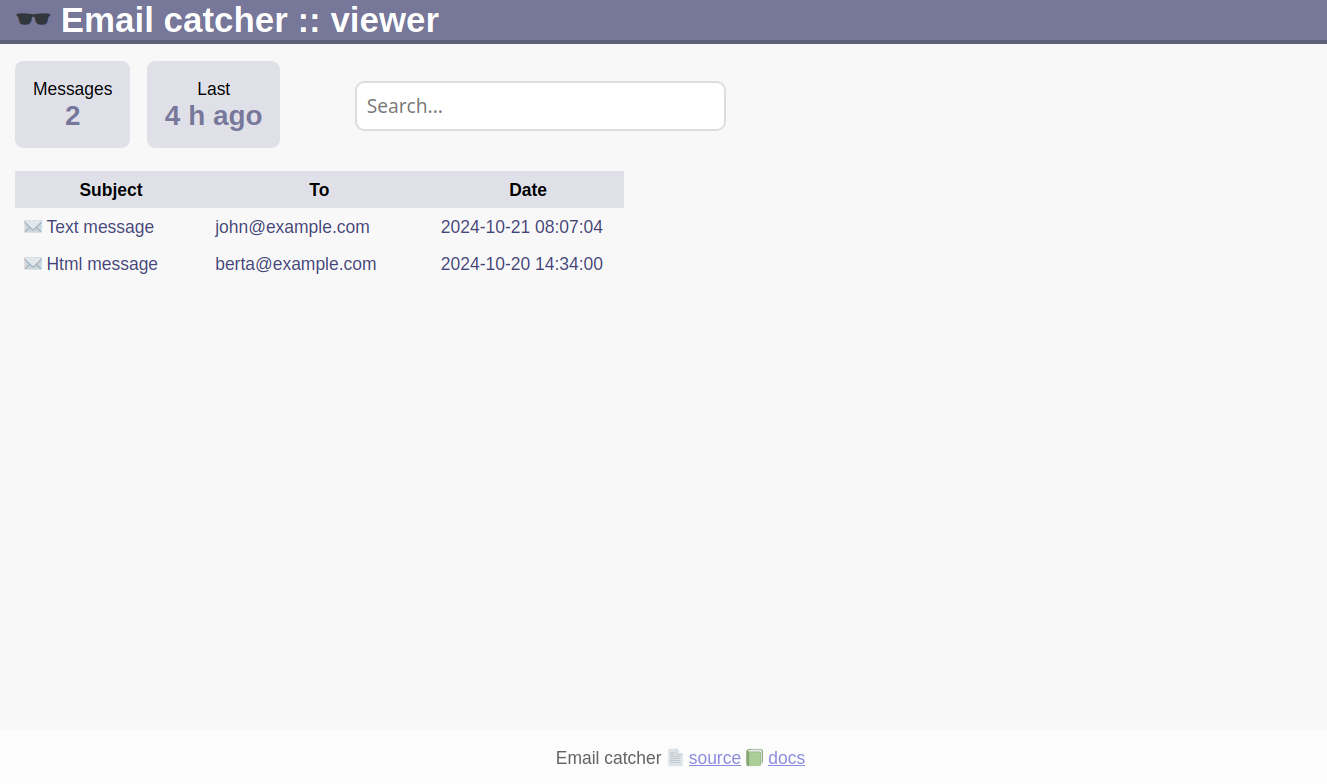
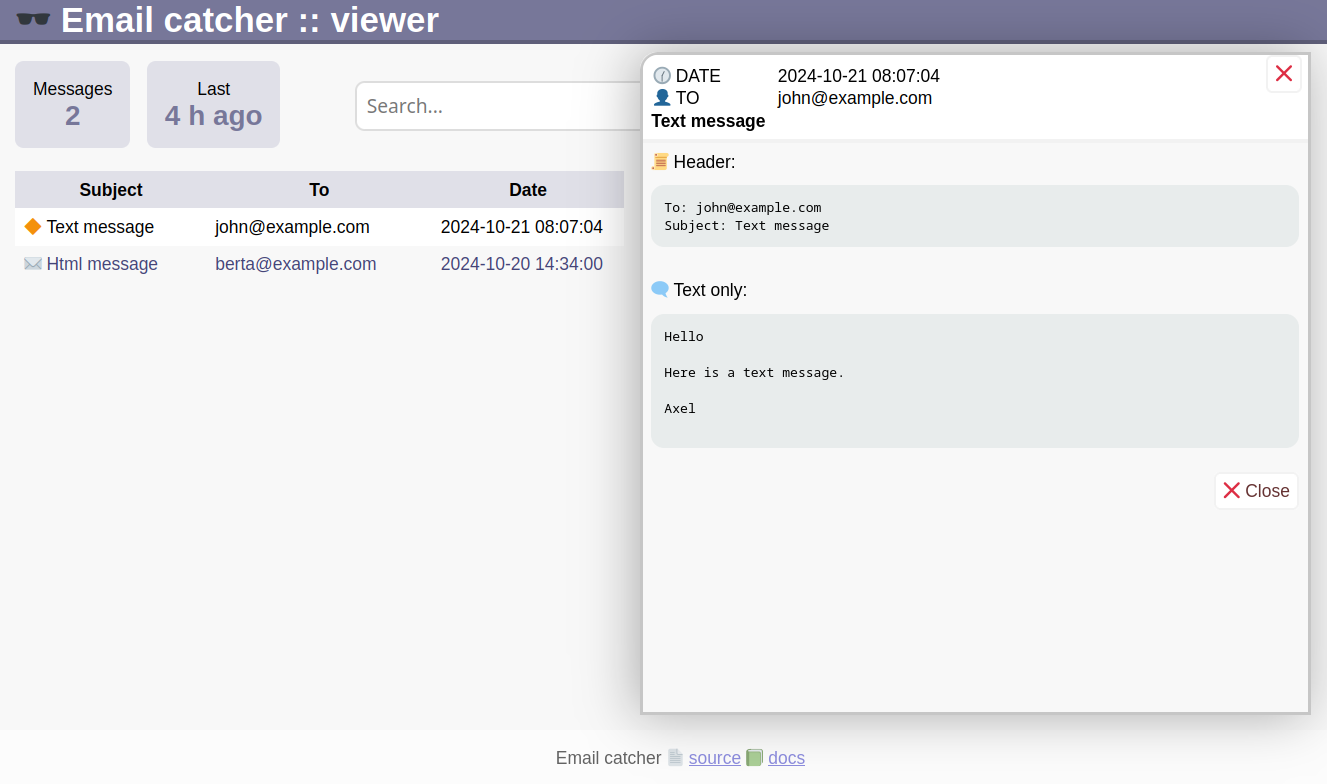
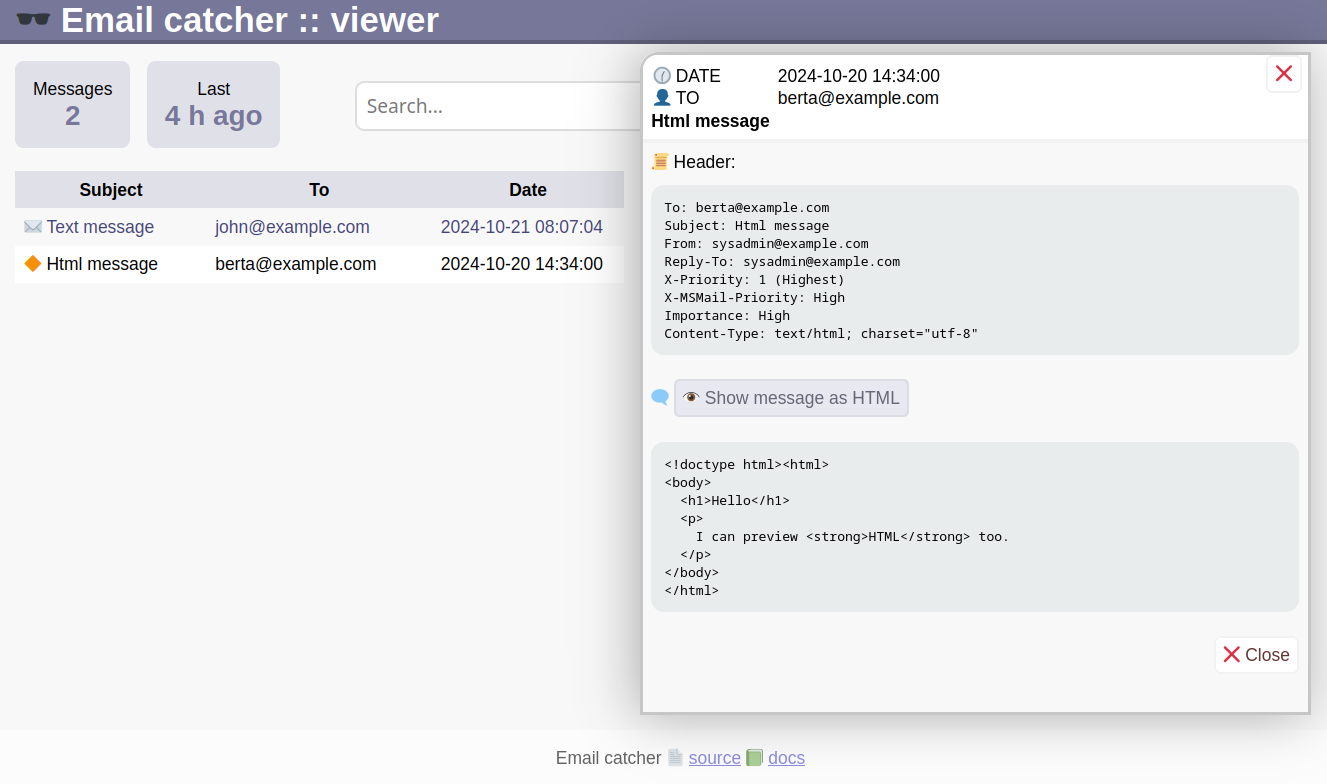
Screenshots - so sieht es aus:
Und so geht es:
Installation mit Git:
Unterhalb des Webroot lege ich im Unterverzeichnis “vendor” die Software ab.
cd [WEBROOT]
cd vendor
git clone https://git-repo.iml.unibe.ch/iml-open-source/php-emailcatcher.git emailcatcher
Einfangen der Email aktivieren:
In der php.ini ist mit sendmail_path auf das Skript php-sendmail.php zu verweisen.
[PHP]
…
sendmail_path = ”php [WEBROOT]/vendor/emailcatcher/php-sendmail.php”
Anm: Sofern php nicht im Pfad ist, muss man statt “php ” den kompletten Pfad angeben z.B. “/usr/bin/php “.
Test-Email versenden.
Viewer starten.
Unterhalb “vendor” ist im emailcatcher Verzeichnis eine viewer.php - die öffnet man im Webbrowser.
Z.B.: http://localhost/vendor/emailcatcher/viewer.php
Tja, und das war es bereits. Viel Spass damit!
Update:
Wenn man HTML Emails versendet und das Layout ansehen möchte, dann brauchte es in der präsentierten Version einige Klicks. Unnötige Klicks. Und immer wieder. HTML Emails wollte ich dann doch direkt sehen können. Im Localstorage des Webbrowsers wird sich der letzte Zustand der Anzeige gemerkt: Header anzeigen ja oder nein - und Ansicht als HTML oder Source.
Sieht wer weiteres Verbesserungspotetial zur Effiziensteigerung? Lasst es mich wissen oder macht einen Pull-Request.
Mi, 16. Oktober, 2024
An meinem Institut habe ich ein Projekt für eine Logon-Seite mit AAI / EduGain in einer funktionsfähigen Version released.
AAI ist eine Anmeldeform im universitären Bereich. Studierende und Dozenten anderer Universitäten melden sich mit dem Account ihrer eigenen Universität bei ihrem gewohnten Anmeldeprovider (IDP) an. Wenn die Authentifizierung erfolgreich war, dann kann der fremde IDP unserer Applikation den Erfolg des Logons in Form einer ID sowie einige minimale Metadaten senden. Mit jener ID lässt sich in der eigenen Anwendung ein User anlegen oder wiedererkennen. Regelbasiert oder manuell administrativ kann man einem Account Gruppen und Rollen zuweisen.
Das gibt es alles schon und ist spezifiziert, dokumentiert und schon lange produktiv im Einsatz. Sowas erfindet man nicht neu.
Mein Pro AAI Login ist in PHP programmiert - und folglich hilfreich für eine PHP-Anwendung mit Shibboleth. Der Ursprung der Entstehung war eine Ilias9 Installation.In früheren Ilias Versionen konnte man für die Start-/ Anmelde-Seite HTML-Code und Javascript einbinden. Auf diese Weise wurde ein externes Javascript WAYF (=Where are you from) von Switch eingebunden. Das funktionierte super.
In Ilias 9 kann man seine Startseite umfangreich zusammenklicken, aber Javascript konnte ich nicht einbetten. In Feldern für HTML-Code wurde es nach dem Speichern ausgefiltert. Nachdem ich mit dem Anmelde-Konfigurator aufgegeben hatte, sollte eine Seite her, die die Aufgabe der Anmeldeseite übernimmt. Zwar ist initial Ilias das erste Ziel-Projekt, aber es ist bewusst flexibel konfigurierbar ausgelegt, so dass es sich für andere Shibboleth geschützte Anwendung einsetzen liesse.
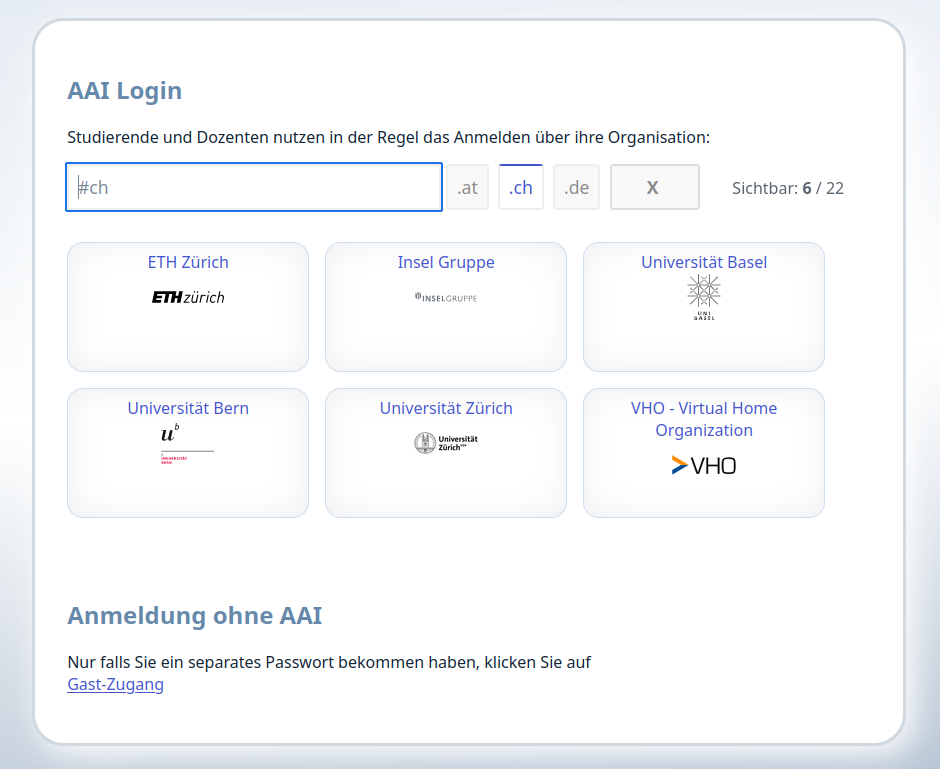
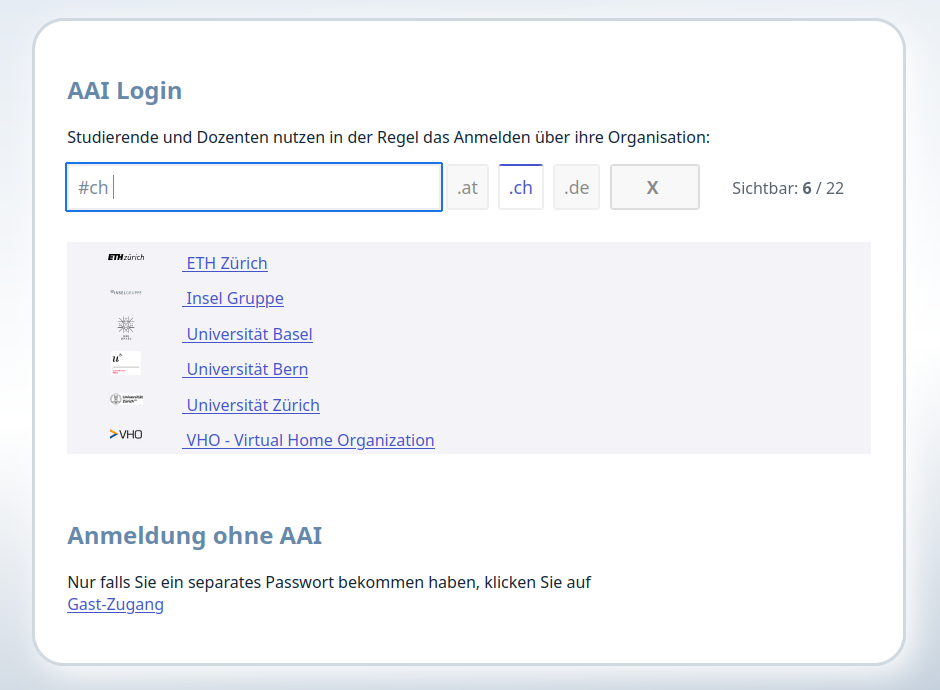
Die Logon-Seite bietet eine Liste der zugelassenen IDPs an. Mit enem Filterfeld lassen sich auf Tastendruck die angezeigten IDP reduzieren, damit ein Benutzer schnell das eigene Login finden kann.
Der Filter nach TLD (Länder-Domains) wird automatisch bereitgestellt.
Die Anmelde-(Auswahl-)Seite unterstützt Mehrsprachigkeit, mehrere Layouts (als Boxen, Liste, WAYF Auswahlseite). Hier die mitgelieferte Darstellungsform als Liste:
Weiterhin ist es flexibel bezüglich
- Sprachen. Ein deutsches und englisches Spachfile sind mitgeliefert. Der Aufwand für ein neues Sprachfile ist sehr überschaubar
- Ausgabetexte: Es gibt 3..4 Textelemente, die man frei konfigurieren kann. So kann man den HTML-Code vor und nach der Provider-Auswahl anpassen.
- Layout der Provider-Ausflistung: es werden 3 Layouts mitgliefert. 2 davon sieht man in obigen Screenshots. Ein neues Layout lässt sich schnell erstellen. Eine Klasse liefert bereits alle nötigen Daten, die man nur noch im gewünschten HTML-Code ausgeben lassen muss. Jedes Layout wird seine eigene CSS Datei einbinden - damit ist man völlig frei in der Gestaltung
- Farben: das Basislayout kommt von einer vorgegebenen CSS Datei. Mit Hilfe einer eigenen CSS Datei kann man alle CSS Rules üübersteuern und das Gesamtlayout verändern.
Die Lizenz erlaubt kostenfreie Verwendung, Einsicht in den Quellcode und Anpassung jedweder Art.
Feedbacks und Verbesserungsvorschläge sind willkommen.
📜 License: GNU GPL 3.0
📄 Source: https://git-repo.iml … pen-source/login-aai
📗 Docs: https://os-docs.iml.unibe.ch/login-aai/
Do, 25. Juli, 2024
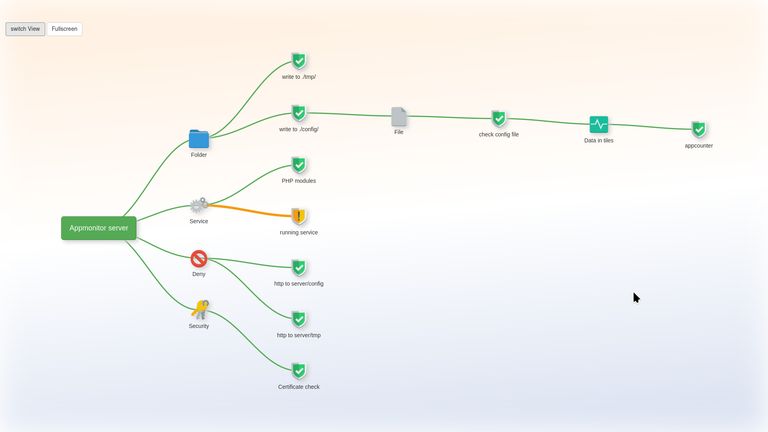
Der IML Appmonitor dient der Ergänzung unseres Systemmonitorings. Aus Sicht einer Applikation werden Prüfungen vorgenommen, die in ihrer Summe eine Aussage treffen, ob eine Applikation gerade lauffähig ist. Sei es die Verfügbarkeit von Ressourcen, APIs oder Datenbanken, Schreibzugriffe auf Upload Folder. Auch sollte man umgekehrt schützenswerte Informationen prüfen, ob diese bei gewöhnlichen Http-Anfragen eben nicht ausgeliefert werden und ein 40x Fehlercode melden.
Man kann Prüfungen miteinander verknüpfen, z.B. muss eine Konfigurationsdatei lesbar sein - die z.B. Credentials für eine Datenbank besitzt - dann ist die Prüfung der Datenbankverbindung von der Lesbarkeit der Konfigurationsdatei abhängig. So kann man einen Abhängigkeitsbaum zu visualisieren, der einem Projektmanager ein klareres Bild zu einer Störung vermitteln kann.
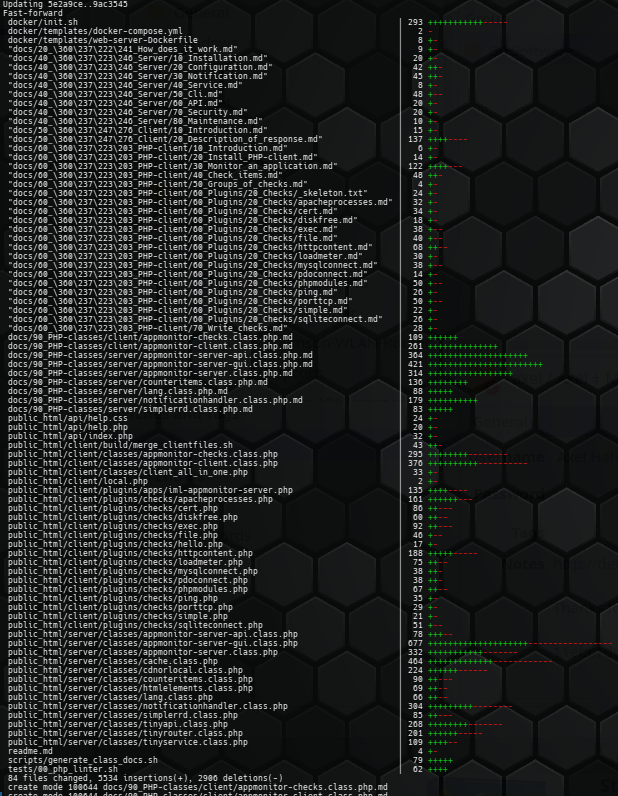
Im Zuge des Updates unserer PHP-Applikationen habe ich den PHP-Code unter PHP 8.3 aktualisiert:
- Bisher ist alles untypisiert gewesen. In Klassen wurden Variablen, Parameter von Methoden und deren Returncode typisiert (also eine Angabe, ob eine Variable ein String, Integer, Array, Objekt, … ist). Das hilft dem Compiler bei Optimierungen und sichert den Code ab. Ist aber auch - bei mechanischem, visuellen Ersetzen auch etwas fehleranfällig.
- PHPDoc wurde in allen Methoden geprüft - da gab es doch viele Kommentar-Sektionen, die nicht mit dem Code übereinstimmten
- Alle Arrays und Hashes wurden auf die verkürzte Array-Schreibweise umformatiert.
- Die Markdown-Hilfedateien wurden überarbeitet
Kurz: ohne Funktionalitätsgewinn wurden ein paar tausend Zeilen in 70+ Dateien geändert und heute gemergt: https://github.com/i … onitor/pull/88/files
Aber dem Programmcode tut es sicher gut, gelegentlich auf einen aktuelleren Stand gehoben zu werden.
Gleichartiges widerfuhr letzte Woche dem Code unseres Intranets.
Weiterführende Informationen: