Bei meiner Arbeit an der Uni Bern war ein Grossteil der Zeit in die Optimierung von Datenbank-Zugriffen geflossen. Das betraf hauptsächlich ein System für ein Portal für Dozierende und Studierende mit Stundenplänen, Kurseinschreibungen, Feeds zu etlichen Themen und nach Studienjahr getrennt, Kalendersynchronisation von personalisierten Kalendern uvm. Jenes Portal ist uralt und wurde einmal mit PHP4 entwickelt und sollte abgelöst werden. Wurde es aber nicht, sondern es wurde vor vielen Jahren mühsam unter PHP5 lauffähig gemacht, aber der Code blieb noch immer zumeist prozedural, mit vielen Includes und gespickt mit allen erdenklichen Highlights an Programmiersünden, sei es Wartbarkeit, Caching/ Performance, SQL-Injection oder Verständnis von Algorithmen und Gestaltung von Datenbankabfragen. Seit dem ersten Ablösetermin sind nun 8..9 Jahre vergangen … aber Herbst 2019 wird es endlich(!!) abgelöst. Heisst aber: bis dahin muss es weiter am Leben erhalten werden.
Es wurden 5 Applikationsteile, die “am meisten weh tun” ausgemacht und jene optimiert. Letzten Dienstag wurde es eingespielt. Doch, es hat sich gelohnt - da ist so ein markanter Abfall:
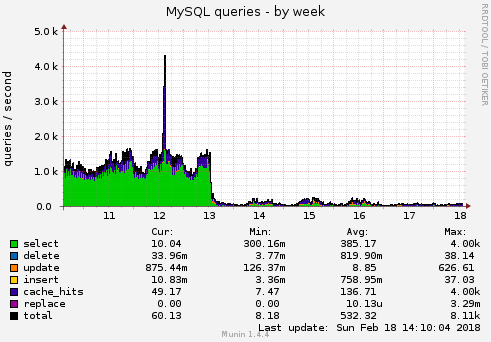
Man könnte meinen: da ist was kaputt. Aber nein: es funktioniert genau gleich!!
Ich hoffe, ich kann euch mit diesem Praxis-Beispiel motivieren: macht einmal eine Performance-Analyse und schaut genauer auf die Top 3!
Ich weiss, dass vieler Code unterirdisch ist. Und die Webseite weil so viele Teilapplikationen mit 10.000 Dateien hat, dass man einen Ansatzpunkt braucht, was sich am meisten lohnt. Denn optimieren kann man eigentlich so ziemlich alles. Aber wie findet man, was da am meisten Performance frisst?
Vorarbeiten/ Analyse
Das Logging der slowqueries sollte in der my.cnf aktiviert werden. Damit landen die langsamen Queries in einem Log. Jenes Logfile sollte man sogleich auch ins Logroation aufnehmen.
slow_query_log = 1
slow_query_log_file = /var/log/mysql/mysql-slow.log
Weiterhin hilfreich:
long_query_time = [Anzahl Sekunden]
log_queries_not_using_indexes = 1
Diese Slow Qery Logs sind nicht wirklich zu erfassen und zu verarbeiten. Man sollte das Analysetool mysqldumpslow (es gehört zu mysql) das Slowquery-Log die Zusammenstellung überlassen. So sieht man die häufigsten Qeries, diejenigen mit den meisten zurückgelieferten Records uvm.
Ich habe dazu einen Cronjob, der mir in einer Datei mehrere Top 10 zusammenstellt:
- Statements mit langer Laufzeit mysqldumpslow -s t -t 10 $SLOWLOG
- haeufig aufgerufene Queries mysqldumpslow -s c -t 10 $SLOWLOG
- Queries, die besonders viele Daten liefern mysqldumpslow -s r -t 10 $SLOWLOG
- Queries, die am laengsten warten mysqldumpslow -s l -t 10 $SLOWLOG
mit $SLOWLOG = /var/log/mysql/mysql-slow.log
Die aufgezeigten Ergebnisse, zeigen an, wie das Query heisst, z.B. DELETE FROM usertable WHERE matrikel=’S’ AND ts < 'S' - ah, es hat Platzhhalter - das ist cool, weil es ein gemeinsames Muster ist, wo im Programmcode ganz sicher Variablen drinstecken, wird damit zusammengefasst. Aber man kann nicht per Textsuche im Code 1:1 das böse Query finden. Wo dieses herkommt, gilt es noch herauszufinden, damit man überhaupt optimieren kann.
Die Aufzeichnung der Systemparameter und Mysql-Daten zu Anzahl Qries, Table-Cache in ein Monitoring oder RRD Tool hilft zur Sichtung der Peaks und der zeitlichen Zuordnung. Läuft ein bestimmert Cronjob oder ist es ein bestimmtes Ereignis, was eine besondere Last auslöst?
Man findet die Quelle der belastenden Queries nicht, ohne die Applikationen und deren Kommunikation mit Umsystemen zu kennen.
Optimierung
PHP 4 Code und viele Programmiersünden… Es brauchte je 1 Tag, um je einen Algorithmus zu optimieren. Das liegt hauptsächlich an der Nicht-Lesbarkeit des Codes. Und es wurden gar absonderliche bis phantastische Dinge gemacht, die man verstehen muss, warum der Programmierer das so machen wollte. Sei es “komische Queries”, sinnlose Variablenbelegungen, vertrackte Datumsfunktionen, seltsame Strubng-Manipulationen in Loop-Konstrukte verschachtelt.
Mein Glück (wenn man es so nennen darf) ist, dass es recht häufig Dinge nach einem solchen Muster gibt
(1)
SELECT * from usertable - Über alle gefundenen Records wird in PHP mit einer For-Schleife dann
a) etwas mit einem String-Vergleich gesucht und verarbeitet, was ich oft in einem SQL-Query selbst erledigen konnte. SQL ist massiv schneller, als die Logik per PHP in einer Schleife abzubilden
b) ein Update-Query zu machen, um Duplikate von einer Personen zu entfernen. Heisst: es wurde das Update stur mit allen gefundenen Personen ausgeführt. Besser ist ein Sql Group by count(userid) direkt wirklichen Duplikate finden zu lassen und wirklich nur die gelegenlich 1..2 Duplikate zu entfernen.
SELECT spalte,COUNT(spalte)
FROM tabelle
GROUP BY spalte
HAVING ( COUNT(spalte) > 1 )
Wenn man mehrere tausend Personen hat, kommen viele-viele Qeries zusammen. Das Qery, was innerhalb des Loops ist, ist jenes, was im slowquery-Analyzer aufgezeigt wurde.
(2)
Dasselbe schöne Spiel gab es mit Kalender-Exporten. Kalender sind personenspezifisch werden zyklisch mehrfach am Tag von Smartphones abgerufen. Eine Stichprobe im access.log ergab ca. 23.000 Kalender-Requests am Tag.
Es wurden per SELECT * die Tage im Range von-bis gesucht, an denen ein Studend/ Dozierender eine Veranstaltung haben.
Über jene Tage erfolgte pro Stunde 0..23 je 2 Query, um SELECT * einmal Stundenplaneinträge stundenweise zu erhalten. Und es wurde in einer 2. Datenbanktabelle, ob der Termin fix ist - oder nur im Preview/ Bearbeitungsmodus. Wenn man das für 1 ganzes akademisches Jahr oder gar mehrere Jahre abruft, kommt einiges zusammen: 5.000 - 8000 Queries sind schnell erreicht.
(3)
Oder mit einem dem SELECT * … werden alle Datenbankeinträge gelesen, um dann mit mysql_num_rows() nur die Anzahl zu lesen.
Es tut weh, sowas zu sehen .. ist aber ein einfacher Winner: mit SELECT count(Feld) ersetzen …
Resultat
Das habe ich oben ja schon in 2 Graphen vorweggenommen :-)
Nach Vereinfachung der Loops im Loop blieben 1 Request für Kalender und 1 pro Kalenderwoche übrig. 30 statt 6000 Queries. Der Kalenderabruf eines Dozierenden braucht statt 60 Sekunden nur noch 0.2 Sekunden.
Wenn ich nun auf den Mysql-Server schaue: die meisten Requests werden vom Query-Cache (in der nachfolgenden Grafik blau) beantwortet. So muss es auch sein.
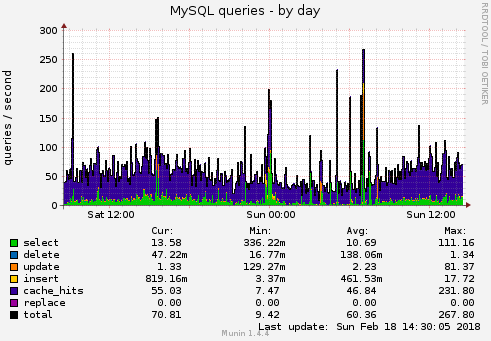
Im Total sank der Tages-Schnitt von 1000 Queries pro Sekunde auf unter 100. Dasselbe Bild habe ich beim Netzwerk-Traffic, Interrupts, beim Load, CPU …
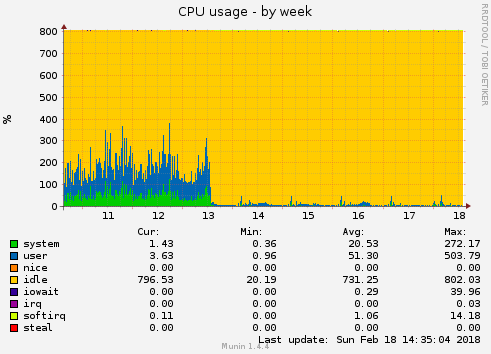
Sowas passiert, wenn der Entwickler zu wenig Programmier-Knowhow hat. Es hätte an vielen Stellen gereicht, dass man grob einen Plan hat, was SQL alles kann - dann könnte man immernoch nach der eigentlichen Syntax noch im Internet suchen, wie es dann genau geht.
Das Programmcode-Müll entsteht, lässt sich bereits einfach verhindern, wenn es in einem Projekt mind. 2 Entwickler gibt, die den Code gegenseitig checken bzw. die Merge-Requests des jeweils anderen prüfen.
Ein Kollege empfahl mir noch: schreib doch ein Buch mit Antipattern!
Tja, allein dieses Projekt liefert da Anhaltspunkte an Sünden en masse. Vielleicht schreibe ich noch den ein oder anderen Blog Eintrag.
weiterführende Links: