Do, 18. August, 2022
Hach, das war ja mal wieder eine lustige Spam-Mail.
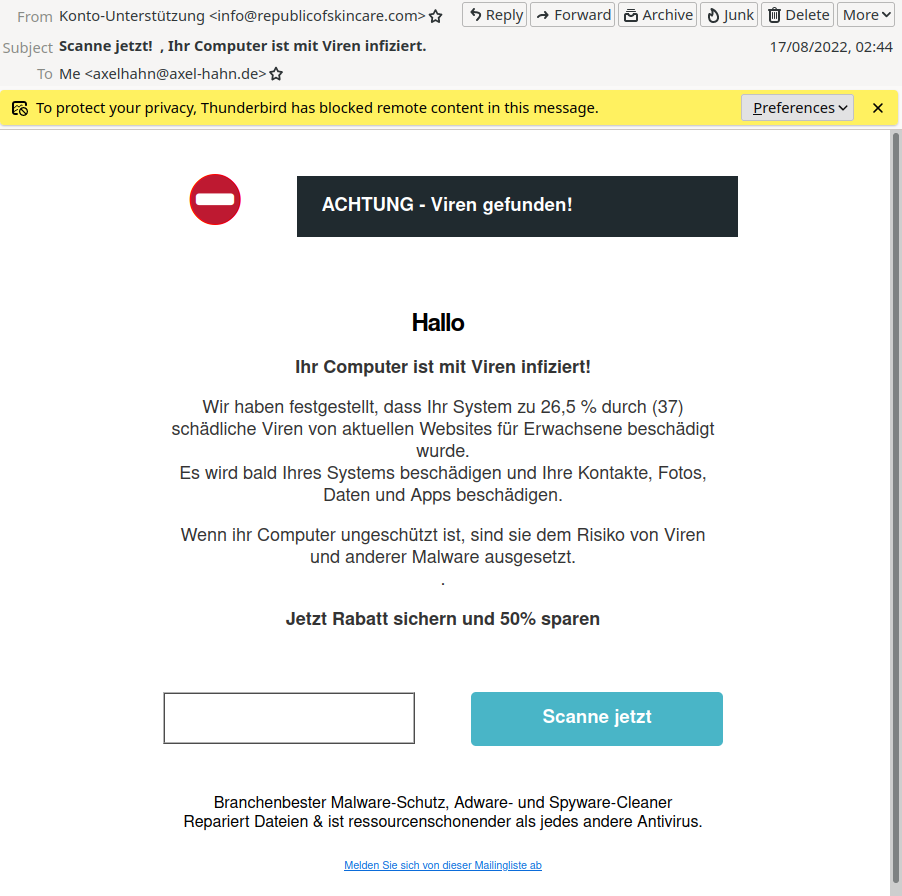
Jemand mit Absender info@republicofskincare.com kennt sich supergut mit Computern aus! Bei dem etwas fachfremd anmutenden Domainnamen ist es gut, dass sie sogleich mit fundiertem Wissen glänzen und meine Bedenken sowas von vom Tisch fegen.
Ganz usability freundlich werden mir 2 grosse Buttons angeboten. Der linke von beiden ist geisterhaft weiss und ist nicht beschriftet - den soll ich wahrscheinlich gar nicht anklicken. Dann ist ja nur noch einer übrig. Das nenne ich durchdachte Benutzerführung.
“Branchenbester Malware-Schutz, Adware- und Spyware-Cleaner
Repariert Dateien & ist ressourcenschonender als jedes andere Antivirus.”
Grandios!
So, 14. August, 2022
Es ist ein halbes Jahr her, dass ich Synology von DSM 7 auf Version aktualisierte. Dies bedingte eine neue Installation einer neueren Version von Emby. Und irgendwie war die Video-Wiedergabe seither immer nur am Ruckeln, dass ich den Spass verlor. Verursacher war Ffmpeg, das on-the-fly das Video-Ausgangsfile für eine Wiedergabe auf einem Ziel in eine Auflösung umrechnet. Mit Herunterschrauben der Auflösung während der Videowiedergabe kam man dem bei, aber schlechtere Auflösungen trüben auch den Filmgenuss.
Wie es der Zufall will habe ich mich nun nochmals in den Emby-Einstellungen verirrt (von der Emby Startseite rechts oben das Zahnrad-Symbol).
Unter Wiedergabe -> Video -> Heimnetzwerkqualität habe ich “auto” voreingestellt.
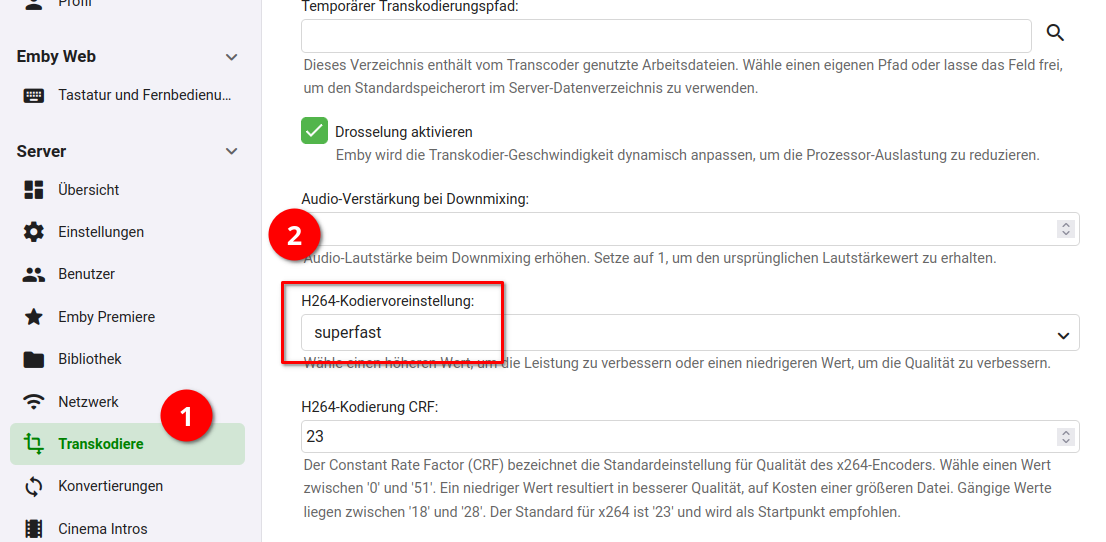
Im Menü unterhalb “Server” gibt es den Eintrag “Transcodiere“, wo man Hardware-Beschleunigung und andere Transcoding-Einstellungen setzen kann. Ich habe weder Emby Premiere noch würde ich mit der Synology eine Hardware-Beschleunigung aktivieren können. Aber auf dieser Einstellungsseite ist ja noch mehr.
Unter “H264-Kodiereinstellung” war “auto” gewählt. Und was soll ich sagen: das bewusste wählen einer langsameren Einstellung wirkt Wunder. Während bei Einstellung “auto” bei Fimlwiedergabe die CPU nahezu ausgelastet war und der Load sich bei 15 einpegelte … hingegen bei “superfast” wird die CPU nur noch kurz zu 20% belastet und liegt dann im einstelligen Bereich. Und bei Videowiedergabe die gewählte Videoqualität mit “auto” besser, als die zuvor gedrosselte Bandbreiten-Auswahl, damit es nicht ruckelte.
Wer mag, kann es von der schlechtesten Qualitätsstufe “superfast” schrittweise noch hochsetzen. Aber das ist eine gute Stellschraube, bei der man ansetzen kann.
Mo, 27. Juni, 2022
Mein Theme des Flatpress-Blog hat vor ein paar Wochen ein Update erhalten und wurde responsive. OK, das war auch überfällig, dass man auf Smartphone und Tablets ebenfalls Blog Texte lesen kann. Es gibt 3 Zoomstufen mit unterschiedlichen Rahmenbreiten.
Bei kleinen Auflösungen werden linke/ rechte Spalte mit Klick auf ein Hamburger-Menü eingeblendet.
Nun kam noch ebenjenes im Screenshot sichtbare Farbschema neu hinzu: den ganz farbenreichen Themes gesellt sich nun ein etwas einfacheres und mehrheitlich weisses. Ich hoffe es gefällt.
Zum Updaten in seiner Flatpress Instanz: im Ordner ./fp-interface/themes/ das Verzeichnis “atog” löschen und durch den im Github Repository ersetzen. In der Admin von Flatpress unter “Themes” kann man das Theme “A touch of glass” wählen und mit dem Link “Styles” die Farbwahl treffen.
weiterführende Links:
- Github: Projekt Seite des Themes
- Github: Theme A Touch Of Glass als ZIP
- Flatpress.org Blogging Engine in PHP ohne Datenbank
Mi, 13. April, 2022
Ich hatte bereits einmal einen ähnlichen Blog Eintrag geschrieben:
Bash: Ausführungszeit eines Kommandos in Millisekunden messen
Jene Methode basierte auf dem Parsing der Ausgabe des time Kommandos.
Nachfolgendes Beispiel-Snippet nimmt einen anderen Ansatz: Das Date-Kommando kann mit %N den Anteil der Nanosekunden zurückgeben. Man nimmt das date Kommando, um einen initialen Zeitstempel zu speichern. Zur Ausgabe der vergangenen Zeit liest man die Zeit erneut aus und berechnet die Differenz. Dazu könnte man bc hernehmen, aber das ist per Default auf einem Linux-Server vorinstalliert. Daher ist mal hier eine Variante mit awk:
export CW_timer_start
# Step 1
# start/ reset timer
# no parameter is required
function start_timer(){
CW_timer_start=$( date +%s.%N )
}
# Step 2 (as often you want)
# get time in sec and milliseconds since start
# no parameter is required
function show_timer(){
local timer_end=$( date +%s.%N )
local totaltime=$( awk ”BEGIN {print $timer_end - $CW_timer_start }” )
local sec_time=$( echo $totaltime | cut -f 1 -d ”.” )
test -z ”$sec_time” && sec_time=0
local ms_time=$( echo $totaltime | cut -f 2 -d ”.” | cut -c 1-3 )
echo ”$sec_time.$ms_time sec”
}
Die Funktion start_timer setzt den initialen Wert bzw. ein Reset.
Die Funktion show_timer zeigt die vergangene Zeit in Sekunden + Punkt + 3stellige Millisekunden an.
Ein Snippet zum Messen sieht grob etwa so aus:
# reset timer
start_timer
# hier irgendwas machen
# sei kreativ :-)
# Ausführungszeit:
echo ”verbrauchte Zeit: $( show_timer )”
Die Ausgabe ist dann soetwas, wie:
verbrauchte Zeit: 0.014 sec
Do, 24. März, 2022
Wer liebt sie nicht - die schönen Thüringer Alpen! Ich weiss noch, als ich Thüringer Rostbratwürsten auf dem Grill beim Brutzeln zusah wie auch den Blick über die schneebedeckten Bergkuppen genoss.
Wer den Fehler findet, kann ihn behalten :-)
Di, 22. März, 2022
Ich verwende diesen Aufruf, um Schemata auf dem Mysql Server zu dumpen:
mysqldump –opt
–default-character-set=utf8
–flush-logs
–single-transaction
–no-autocommit
–result-file=”$_dumpfile”
”$_dbname” 2>&1
$myrc=$?
… und stand vor dem Phänomen, dass der Exitcode 0 war - also eigentlich den Erfolg meldet - aber es keinerlei Daten im Dump gab.
Das Betriebssystem war ein Centos8 Stream. Das Problem lag in der Option –flush-logs, die nicht ausgeführt werden konnte, da das Verzeichnis /var/log/mysql/ (warum auch immer) nicht mehr vorhanden war. Dass ein leerer Dump ohne Daten erzeugt wird und kein Exitcode > 0, ist m.E. ein Fehler im mysqldump. Und den versuche ich, zu umschiffen.
Ich habe nach dem Dump noch einen Check hinzugefügt, der das Vorhandensein auf mind. ein CREATE oder aber INSERT Statements prüft. Oder anders: wenn man eine (korrekte) leere Datenbank ohne einzige Tabelle oder auch nur 1 einzigem gesicherten Datensatz hat, würde ein Fehler beim Backup gemeldet. Ich meine, damit lässt es sich leben.
mysqldump –opt
–default-character-set=utf8
–flush-logs
–single-transaction
–no-autocommit
–result-file=”$_dumpfile”
”$_dbname” 2>&1
$myrc=$?
if [ $myrc -eq 0 ]; then
if ! zgrep -iE ”(CREATE|INSERT)” ”$_dumpfile” >/dev/null
then
typeset -i local _iTables
_iTables=$( mysql –skip-column-names –batch -e ”use $_dbname; show tables ;” | wc -l )
if [ $_iTables -eq 0 ];
then
echo ”EMPTY DATABASE: $_dbname”
else
echo ”ERROR: no data - the dump doesn’t contain any CREATE or INSERT statement.”
# force an error
$myrc=1
fi
fi
fi
if [ $myrc -eq 0 ]; then
echo ”OK”
# Und dann hier noch komprimieren…
# gzip $_dumpfile”
# … und Erfolg der Kompression auswerten
else
echo ”ERROR: mysqldump failed.”
fi
Update:
- 24.03.2022 - eine leere Datenbank würde als Fehler gemeldet - daher zähle ich mal noch die Tabellen
weiterführende Links:
- mysql.com: mysqldump
- mariadb.com: mysqldump
- IML open source: IML-Backup (mein Backup Tool an unserem Institut zum lokalen Dumpen div. DBs und Backup mit Restic/ Duplicity)
- DOCs: os-docs.iml.unibe.ch/iml-backup/
Do, 10. März, 2022
Ich habe grad in die History geschaut: 20 Jahre (!!!) nutze ich schon den meinigen Cronwrapper auf Linux/ Unix-Systemen.
Und ich bin noch immer am Aktualisieren und Verfeinern von dessen Skripten oder Dokumentation. Auch weil ich dessen Idee so mag. Alles ist OpenSource - GNU GPL 3.0.
Das Repository [1] enthält
- cronwrapper.sh - ein Wrapper - wenn man Cronjobs hat, dann stellt man den einfach mal vorn dran
- cronstatus.sh - das Skript zeigt den Status aller auf dem System befindlichen Cronjobs
- inc_cronfunctions.sh - ein Script, dass in Bash geschriebene Cronjobs gesourct werden kann, um div. nützliche Funktionen zu nutzen.
- Dokumentation im Markdown Format zur Installation und allen Features.
Der einfachste Einstieg ist, den Wrapper cronwrapper.sh zu verwenden: mit allen bestehenden Cronjobs, egal welcher Programmiersprache jene sind, lässt sich dieser ergänzen. Und man erhält out-of-the-box kleine nette Features.
- STDOUT und STDERR werden eingefangen und in ein normiertes Logfile geschrieben (ohne jenes explizit angeben zu müssen)
- Das Logfile wird normiert und ist mit grep nach Output oder Metadaten durchsuchbar
Alle Cronjobs, die den Wrapper verwenden, werden mit dem Skript cronstatus.sh aufgelistet und bewertet:
- weisen sie exitcode 0 auf?
- sind sie in der vorgegebenen Frist gestartet worden?
Diese Ausgabe kann man auch in einem Monitoring Script für die Überwachng aller Cronjobs auf seinen Systemen einbinden.
Und als Goodie gibt es ein Include file inc_cronfunctions.sh,welches hilfreich sein kann, sofern die Cronjobs in Bash geschrieben sind: eine Reihe nützlicher Funktionen werden darin bereitgestellt, um das Schreiben von “sicheren” und lesbaren Conjobs zu erleichtern.
weiterführende Links: (en)
- Github: cronwrapper
- Docs auf axel-hahn.de
Mo, 21. Februar, 2022
Ich habe da eine PHP-Applikation, die ein Webinterface besitzt als auch per CLI einige Dinge - z.B. als Cronjob - aufruft.
Beide Arten von Skripten - bei Http Aufruf oder aber CLI - durchliefen dasselbe Init-Prozedere und referenzierten ein und dasselbe File.
$this->sTouchfile = sys_get_temp_dir() . ’/some_file.tmp’;
Oder besser: ich hatte es zumindest gemeint. sys_get_temp_dir() wurde auf dem Linux-System als “/tmp” aufgelöst. Also optisch war es dieselbe Datei: /tmp/some_file.tmp - aber Das Webinterface erkannte eine Aktion auf CLI Seite nicht … und umgekehrt das CLI nicht eine Schreibaktion aus dem Webinterface.
Bis ich dann mal auf die Idee kam und mir mit einem per Http aufgerufenem Skript eine spezifische Datei in /tmp/ anlegte und diese mal im Filesystem suchte. Unter dem PHP-FPM Service war als /tmp/ jenes “tmp” Verzeichnis verwendet worden:
/tmp/systemd-private-d1b7cf65cce54d4ca9f98c49cca1887f-httpd.service-NoEzTN/tmp/
Das hat mir das ungewöhnliche Verhalten auch sofort erklärt.
Man merke: /tmp sollte man meiden, wenn man gemeinsame Daten per http als auch CLI Daten teilt. Ich habe in meiner Applikation von sys_get_temp_dir() auf ein “tmp” unterhalb [Approot] umgestellt…
weiterführende Links:
- php.net: sys_get_temp_dir()
Mo, 14. Februar, 2022
Manchmal möchte man Hilfsausgaben in seinem Bash-Skript haben. 2 kleine Hildfsfunktionen definiert:
- _wd für write debug infos zur Ausgabe von optional sichtbaren Kommentaren und
- _we für write error zum Einblenden von Fehlermeldungen.
# write a debug message in yellow to STDERR
function _wd(){
test $DEBUG -eq 0 || echo -e ”e[33m# DEBUG: $*e[0m” >&2
}
# write error message in red to STDERR
function _we(){
echo -e ”e[31m# ERROR: $*e[0m” >&2
}
… und dann kann man in seinem Skript schreiben
# global var: enable debug output: 0|1
DEBUG=1
…
# example debug output
_wd ”show 3 oldest items in directory content”
ls -ltr | head -3
…
# example error
_we ”Something went wrong :-/”
exit 1
Mi, 5. Januar, 2022
Ich habe seit gut einem Jahr einen gebrauchten Toyota Auris Hybrid. Für jenen wird ein Kraftstoffverbrauch von 3.9 l auf 100 km angegeben - was ich bisher nicht erreichte. Ich war grundsätzlich darüber - und im Schnitt habe mit Auswertung bei Tankfüllungen gut 0.7 l mehr.
Nun war einen ganzen Tag mitsamt Kind und Kegel unterwegs - nur per Ortsverkehr und Landstrasse. Es geht also doch irgendwie. Nun kam ich für eine Tour einmal auf den Wert des angegebenen Werksverbrauchs.
Manches glaubt man auch erst, wenn man es einmal mit eigenen Augen sieht :-)
Der Trick ist wohl generell, dass es längere Fahrwege braucht, bis alles warmgelaufen und die Batterie gut genug geladen ist, um effizient daherzurollen.
Ansonsten braucht es zum kraftstoffsparenden Fahren:
- vorausschauendes Ausrollen bei Ampeln oder Kreuzungen
- manuelles Einschalten der Rekupation für sanftes Bremsen oder bei Bergab-Fahrt
- Gebrauch des Tempomat - ich nutze den auch im Stadtverkehr
Aber egal ob 3.9 oder 4.5 Liter - irgendwie ist das nicht schlecht, für meinen 7 Jahre alten Kombi - mit immerhin 1.5t Leergewicht.