Wenn man im Monitoring einen Check schreiben will, der die Antwort-Zeit einer Aktion oder Response eines Servers messen will, sind sekundengenaue Angaben zu grob. Mit dem Kommando
time [Kommando]
kann man sehen, wie lange das jeweilige Kommando brauchte:
$ time ls
[… Liste von Dateien …]
real 0m0,022s
user 0m0,000s
sys 0m0,015s
Die Gesamtzeit ist in der Zeile real enthalten. Angegeben sind die Minuten, ein “m” und danach die Sekunden mit 3 Nachkommastellen. Wobei die Tausendstel je nach System/ Sprache mit Punkt oder Komma getrennt sein könnten.
Aha, nun muss man “nur” noch die Zeile mit der Angabe “real” in den letzten 3 Zeilen der gesamten Ausgabe suchen und das Ganze parsen.
Als kleines Demo anbei einmal mundgerecht als Funktion (es läuft unter Linux und mit CYGWIN unter MS Windows):
#!/usr/bin/env bash
# —— FUNCTION
# measure time in ms
# @param string command to execute / measure
function getExecTime(){
local sCommand=$1
local tmpfile=$( mktemp )
( time eval $sCommand ) >$tmpfile 2>&1
local sRealtime=`cat $tmpfile | tail -3 | grep ”^real” | awk ’{ print $2 }’`
rm -f $tmpfile
local iMin=`echo $sRealtime | cut -f 1 -d ”m” `
local iMillisec=`echo $sRealtime | cut -f 2 -d ”m” | sed ”s#[.,s]##g” | sed ”s#^0*##g” `
typeset -i local iTime=$iMin*60000+$iMillisec
echo $iTime
}
# —— MAIN
echo
echo ”ZEITMESSUNG IN MILLISEKUNDEN”
echo
mytime=`getExecTime ’ls -ltr’`
echo Dauer: ${mytime} ms
Ein kleines Snippet von mir zum Updaten der Linux-Distro Manjaro.
Es aktualisiert die Softwarepakete der Distribution (Kernel, Programme u.s.w.) - danach aus den AUR (Arch User Repository) installierte Programme. Zum Schluss werden nicht benötigte Pakete entfernt.
Es werden noch Zwischenabfragen gestellt, die mit Yes oder No zu beantworten sind. Mit Auskommentieren der Zeile answer=Y kann man es teilautomatisieren, jedoch pamac wird immer eine Interaktion bedürfen und das Passwort erfragen.
Ich bin an unserem Institut am Neuaufbau des Monitorings mit ICINGA dran. Weil es so empfohlen wird, kommt das Director Modul zum Einsatz. Ach so, bereut habe ich dies nicht.
Das Monitoring funktioniert über passive Checks: jeder Server meldet sich selbst an und sendet seine Monitoring Daten zu Icinga ein.
Jeder unserer Server soll ein Host Objekt anlegen, die bemötigten Service-Objekte und und die Services mit dem Host-Objekt verknüpfen. Dazu “spricht” jeder Server per REST API mit dem Director. Der muss die Konfiguration zum Icinga-Server deployen.
Zum Einsenden der Daten braucht es den bereitgestellten Slot für den Host+Service auf dem Icinga-Service. Der Client spricht zum Einliefern der Monitoring-Daten ebenfalls mit einer REST-API - aber dann mit der des Icinga Daemons.
Zum Abstrahieren der REST-API Zugriffe auf verschiedene APIs habe ich alles rund um Http abstrahiert und eine Bash-Komponente geschrieben, die diverse Funktionen für Http-Zugriffe und Abfragen in Skripten einfacher verfügbar macht. Die Verwendbarkeit in Skripten war der Fokus. Die Funktionen ähneln vom Aussehen Methoden einer Klasse: “http.[Funktion]”.
Macht man einen Http-Request, so bleibt dessen Antwort im RAM. Bis man den nächsten Request macht - oder die Shell / das Skript beendet.
Weil es ein Wrapper von Curl ist, kann man alle Http-Methoden, wie GET, HEAD, POST, PUT, DELETE verwenden.
Um einen ersten Eindruck zu vermitteln:
http.makeRequest GET https://www.axel-hahn.de/
Diese Aktion erzeugt keine Ausgabe.
Man kann dann mit Funktionen den Statuscode abfragen, den Http Response Header, den Body oder aber die Curl Daten (darin sind z.B. Upload- und Download-Speed und Verbindungszeiten).
http.getResponseHeader
… gibt alle Http-Response-Headerzeilen aus.
http.getStatuscode
… zeigt den Statuscode
http.isOk
… testet, ob die Anfrage mit einem 2xx Code zurückkam.
Für Icinga wurde der Zugriff mit Basic Authentication umgesetzt.
GET Abfragen lassen sich für N Sekunden cachen. Darüber hinaus kann man den Response exportieren und wieder importieren. Nach dem Import kann man wiederum den Response mit allen Funktionen erfragen - mit http.getRequestAge holt man sich das Alter der Ausführungszeit des Requests. Man kann ein Debugging aktivieren, um die interne Verarbeitung offenzulegen und nachzuvollziehen.
Und Einiges mehr.
Falls das für euch interessant klingt, schaut euch das Bash-Skript doch einmal an.
Meine beiden Manjaro Instanzen im Büro und daheim habe ich auf fish als Default-Shell umgestellt.
Nun wollte ich in der Konsole beim ersten Aufruf einer Shell den SSH Agent mitsamt meines SSH Keys starten lassen.
(1)
Dazu muss man einmal den “Ersatz” der ~/.bashrc finden - das wäre die Datei ~/.config/fish/config.fish. Wenn man als Newbie mit fish startet und noch gar nichts auskonfigriert hat, so exisitiert diese Datei nicht. Man muss sie anlegen.
(2)
Trick 2 ist die Meisterung des Starts des SSH-Agents. Unter fish wäre es mit
eval (ssh-agent -c)
aufzurufen.
(3)
Was mir beim Schreiben des allerersten 5-Zeilers so auffiel: die Syntax von fish untescheidet sich durchaus zu anderen Shells, wie sh, ksh oder bash: hier gibt es keinen Abschluss mit “fi” oder “esac”, aber davon verabschiedet man sich sicher gern. Und statt $? ist die Variable $status.
Hier mein kleines Snippet:
cat ~/.config/fish/config.fish
# ———————————————————————-
# Start SSH agent with my default key
# ———————————————————————-
ps -ef | grep -v grep | grep ”ssh-agent -c” >/dev/null
if test $status -ne 0
echo ”SSH-Agent wird gestartet…”
eval (ssh-agent -c)
ssh-add ~/.ssh/id_rsa
end
# ———————————————————————-
Ich brauchte da mal was für unsere Systemlandschaft: der Webservice soll neu gestartet werden, wenn sich eine vordefinierte Datei ändert. Wenn es ein Update der Web-Applikation gibt, dann kann jenes Update ein touch [Dateiname] auslösen.
Wenn das Check-Skript mit einem User läuft, der den Webservice starten darf - sei es mit root oder einem User, dem sudo auf systemctl erlaubt ist - dann kann ein Entwickler niedrige Applikationsrechte haben, ihn aber eine spezifische höhere Rechte erforderliche Aktion ausführen lassen, ohne ihm selbst root oder sudo Rechte geben zu müssen.
Mein Skript habe ich onfilechange.sh genannt.
Es benötigt minimal Parameter zum Erfassen der zu überwachenden Trigger-Dateien und das auszuführende Kommando.
Mit einem “-v” schaltet man den Verbose-Modus ein - dann sieht man mehr, was das Skript gerade macht.
Parameter:
-c [command]
command to execute on a file change
-f [filename(s)]
filenames to watch; separate multiple files with space and put all in quotes
-h
show this help
-i
force inotifywait command
-s
force stat command
-v
verbose mode; enable showing debug output
-w [integer]
for stat mode: wait time in seconds betweeen each test or on missing file; default: 5 sec
Ein erstes einfaches Beispiel:
Es wird der Text Hallo ausgegeben, sobald man (z.B. in einem 2. Terminal) die Datei /tmp/mytestfile toucht oder beschreibt.
Mit einem zusätzlichen Parameter -v kann man etwas genauer reinschauen, wie das Skript onfilechange.sh arbeitet.
Auf der Kommandozeile macht das Skript wenig Sinn. Um es permanent laufen zu lassen, sollte man es als Dienst einrichten. Wie man mit dem Skript einen Systemd Service einrichtet, ist in der Readme enthalten. Folge ganz unten dem Link zum Sourcecode.
Lizenz: Free software; GNU GPL 3.0
Und noch etwas zu den Interna, wie man die Datei-Überwachung bewerkstelligen kann:
(1)
Das gibt es zum einen inotifywait . Das Tool erhält man in vielen Distros mit Installation der “inotify-tools”.
Nachteile:
- Die Datei / alle zu prüfende Dateien müssen immer existieren. Wenn es einen Prozess gibt, der das Löschen der Trigger-Datei zulässt, ist diese Kommando ungünstig
- Installation der “inotify-tools” ist erforderlich
Vorteile:
+ Man kann mehrere Dateien zum Überwachen andocken
+ Man kann spezifisch definieren, welche Events man überwachen möchte
+ Ohne einen Loop zu verwenden, kann man nach Beendigung mit Returncode 0 ein Kommando starten. Die Ausführung erfolgt sofort
(2)
Das Kommando stat liefert etliche Datei-Attribute, wie Namen, letzer Zugriff, letzte Änderung, Rechte, …
Nachteile
- man kann nur 1 Datei prüfen. Bei mehreren muss man sich einen Loop über n Dateien bauen
- es braucht eine while Schleife und ein sleep N, um zyklisch einen Zustand zu überwachen
- der Kommando-Aufruf erfolgt nicht sofort, sondern ist entspr. sleep in dessen Wartezeiten etwas verzögert.
Vorteile:
+ Man kann obige Nachteile weitestgehend umgehen - dann ist die Prüfung mit stat auch die zuverlässigere Variante
+ Es ist in jeder Distribution in der Standard-Installation enthalten
Ich hatte, mal irgendwann OBS auf meinem Rechner installiert … seinerzeit für einen recht banalen Zweck (Vollbild-Streaming zu Youtube) … und jenes geriet fast in Vergessenheit, weil nie wieder gebraucht.
Bis - ja bis eines wunderschönen Tages jemand in unserem Institut meinte, “… mit OBS kann ich für eine Demo sehr einfach Bild-Kompositionen auf andere Bildschirme streamen…”. Es sei einfach und verbirgt viele komplexe Einstellungen, zu denen man aber auch kommt.
Dies war der Wink mit dem Zaunpfahl, das Werkzeug gleichen Abends nochmals hervorzukramen: Man kann mehrere Bildschirmszenen ertsellen und dazwischen umschalten? Diese auch speichern? Und statt streamen vielleicht auch ein Video aufzeichnen?
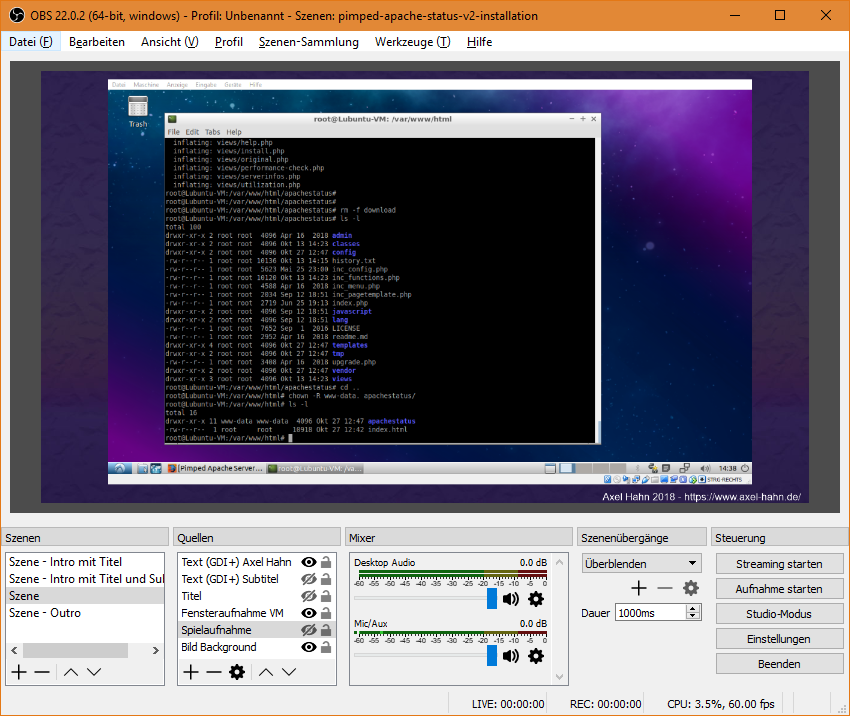
Ich habe mich zu Beginn wohl zu initial wenig auf das Werkzeug eingelassen. Die Einstiegsoberfläche ist halbwegs einfach. Sobald man aber irgendeine Einstellung bearbeitet, wird man mit zahlreichen Optionen regelrecht eingedeckt. Das Speichern der erstellten Szene habe ich gar nicht gefunden, weil ich es als “Pojekt” links oben im ersten Menüpunkt erwartet hätte. Man muss sich wirklich erst etwas genauer umsehen.
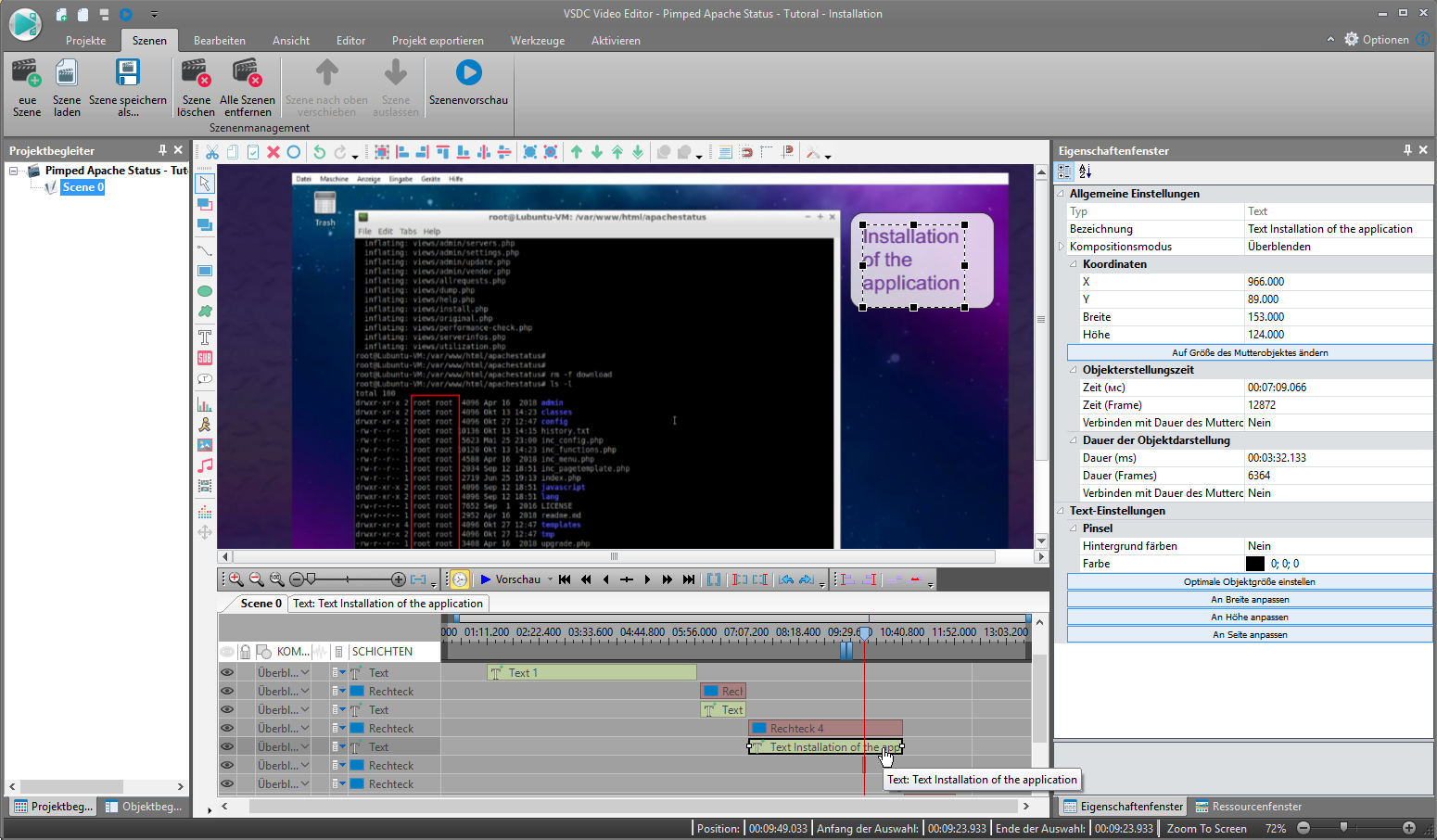
Weil ich schon immer mal ein Tutorial mit Aufzeichnung des Bildschirminhaltes machen wollte, habe ich mich nochmals hingesetzt und probiert.
Als Erstlingswerk entstand ein Installationsvideo für mein Monitoring Werkzeug Pimped Apache Status.
Das Haupfenster ist spartanisch … aber hat es in sich
links unten: “Szenen” - eine Liste mit verschiedenen Settings: Start-Bildschirmseite mit Text, dann eine oder mehrere mehrere mit Interaktionen, eine Outro-Szene.
links unten 2: “Quellen” - pro Szene kann man ein Setup von Quellen platzieren. Ein Bild oder Programmfenster, Webcam oder Videoquelle, Text - alle Elemente kann man skalieren und verschieben und so beliebig anordnen. Die Quellen kann man in mehreren Szenen verwenden (verlinken) - damit werden Änderungen eines Textes oder einer Farbe in allen Szenen übernommen.
OBS zeichnet die Szenen-Umschaltung, die ich manuell gesteuert habe (Anm.: man kann dies auch automatisieren) und die in einer Szene eingebetten Bildschirmaktionen als eine Video-Datei auf.
Nach der Aufnahme war das per Webcam aufgezeichnete Audio zu leise - das musste noch normalisiert werden. Und das Video nochmals encodet.
Weil ich noch zusätzlich einige Annotationen einbringen wollte, z.B. weitere Texte und Hervorhebungen in der Ausgabe auf der Konsole, wurde noch ein 2. Video-Bearbeitungswerkzeug herangezogen.
Und dann die Videodatei ein drittes Mal encodet. Davon wird die Videoqualität nicht besser. Hier habe ich noch Potential für Optimierungen.
Aber dann ging es “sogleich” auf Youtube.
Voila:
weiterführende Links:
obsproject.com OBS Studio (Free and open source software for video recording and live streaming)
Ich habe bei meinem Hoster ein shared Hosting. Dort läuft seit (gefühlt) “ewig” eine Piwik-Instanz. Heute Matomo.
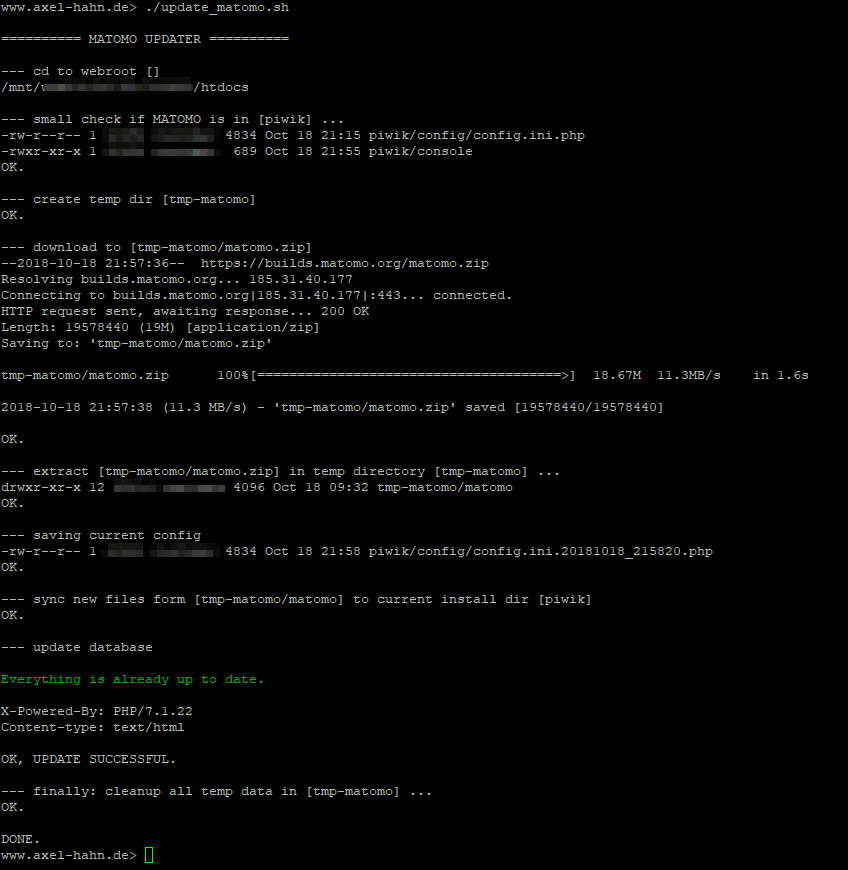
Das aktuellste Matomo Zipfile enthält das Unterverzeichnis “matomo”. Aber meine Instanz liegt noch in einem andersnamigen Verzeichnis.
Damit ich auch künftig weiter automatisiert auf die aktuelle Matomo Version aktualisieren kann, habe ich ein Shellskript geschrieben, was das entpackte Achiv ins eigentliche Installverzeichnis schiebt.
Falls dies noch wer gebrauchen kann … bitteschön und am liebsten auf Github schauen [2] :-) Anzupassen ist der Bereich Config…
Wir verwenden Puppet als Werkzeug zum Verteilen unserer Server-Konfigurationen auf Linux-Systeme. Für das Löschen von Dateien älterer N Tage in einem Startordner haben wir oft mehrere angepasste Shell-Skripte mit einem Suchbefehl verwendet.
Das IML CLEANUP macht einfach eine Aufteilung von Logik- und Konfigurationsdaten. Es ist einfacher, eine kleine Konfigurationsdatei zu erzeugen (besonders, wenn Sie Automatisierungswerkzeuge wie Puppet, Ansible oder Chef verwenden) anstatt mehrere Bereinigungsskripte zu bearbeiten.
Man kann mehrere Konfigurationsdateien anlegen, die jeweils etwa so aussehen:
Bei einigen Servern habe ich einen Cronjob, der ruft ein Shellskript auf, welches den IST Zustand einiger Dienste auflistet. Also, auf einem Server, welche Mysql- und Postgres-Datenbankschemata es gibt, auf dem nächsten welche Apache VHosts existieren und auf dem Fileserver welche Samba-Shares usw.
Schlussendlich landet es auf einem Wiki (Dokuwiki in diesem Fall - hier sind die Seiten Txt-Dateien im Filesystem - das macht die Sache sehr einfach).
Beim Samba Server war es bis anhin recht unschön, weil umständlich gecodet. Nun habe ich 3 kleine Funktionen hinzugefügt, mit denen ich (endlich :-)) eine INI Datei parsen kann.
Die Funktionen kann man in eine Datei mit Leserechten (ohne Execute-Recht) auslagern, die man im Skript sourct (per source oder Punkt-Kommando).
_getInisections[Name der Ini-Datei] listet alle Sektionstitel auf
_getInisectiondata[Name der Ini-Datei] [Name der Sektion] listet die angegebene Sektion auf. Mit dieser Ausgabe sieht man eine Sektion alleinstehend - und kann sich die Variablen herausziehen … aber wenn man die Variablen kennt, gibt es noch die nächste Funktion
_getIniValue[Name der Ini-Datei] [Name der Sektion] [Name der Variable] gibt den Wert einer Variable aus der angegebenen Sektion zurück
In der Samba-Konfiguration (/etc/samba/smb.conf) sind die Variablen und Werte nicht zwingend ab Zeilenanfang - daher sind im Regex Leerzeichen und Tabs hinzugefügt.
# Helper for ini files: get all sections
# param1 - name of the ini file
function _getInisections(){
local myfile=$1
grep ”^\[” $myfile | sed ’s,^\[,,’ | sed ’s,\],,’
}
# Helper for ini files: get all content inside a section
# param1 - name of the ini file
# param2 - name of the section in ini file
function _getInisectiondata(){
local myfile=$1
local mysection=$2
mysection=$( sed ”s#/#\/#g” <<< ”$mysection” )
sed -e ”0,/^\[${mysection}\]/ d” -e ’/^\[/,$ d’ $myfile | grep -v ”^[#;]”
}
# Helper for ini files: get a value of a variable in a given section
# param1 - name of the ini file
# param2 - name of the section in ini file
# param3 - name of the variable to read
function _getIniValue(){
local myfile=$1
local mysection=$2
local myvarname=$3
_getInisectiondata ${myfile} ${mysection} | grep ”[^\a][\ \t]*${myvarname}[\ \t]*=.*” | cut -f 2 -d ”=” | sed -e ’s,^\ *,,’
}
Und als Anwendungsbeispiel: ein Snippet mit einem Loop über die Samba-Konfiguration. Ausgegeben wird eine Tabelle mit Name des Shares, Beschreibung (Wert “comment”) und Pfad des Shares (Wert “path”):
smbconf=/etc/samba/smb.conf
# Ausgabe des Tabellen-Header in Wiki-Syntax
echo ”^Share^Kommentar^Pfad^”
# Loop ueber alle Sektionen
for mysection in `_getInisections $smbconf | grep -v global`
do
# Ini-Werte aus der Sektion lesen
myComment=`_getIniValue ${smbconf} ${mysection} ”comment”`
mypath=`_getIniValue ${smbconf} ${mysection} ”path”`
# Ausgabe der Tabellen-Zeile - Pipes sind Spaltentrenner
echo ”|${mysection}|${myComment}|${mypath}|”
done
UPDATES:
15.05.2019: Korrektur der fehlenden Backslahes (die wirft das Blogtool immer raus, wenn man es nicht als Html-Entity schreibt) plus verbessertes Handling mit laschen Regex und Leerzeichen. Danke an Frank!
04.03.2021: Sektionen mit eckigen Klammern aus Kommentaren ignorieren. Zusätzlich werden Kommentare mit Semikolon am Anfang ebenfalls ignoriert. Ein local macht eine Variable nur innerhalb der Funktion bekannt.
09.02.2022 Update von _getIniValue: [^\a] statt ^
19.03.2023: Ein Follower Projekt: Ich habe aus der class like Bash Funktionen erstellt. Mit Validator und anständiger Dokumentation https://www.axel-hah … docs/bash_iniparser/