Do, 29. Januar, 2015
Ab morgen treten auf Facebook die neuen Datenschutzrichtlinien in Kraft, denen man automatisch zustimmt, wenn man sich ab dem Tag bei FB anmeldet.
Natürlich kann man sich bei FB darüber informieren. Das Datum der letzten Bearbeitung [1] wird dann auch gleich mal in die Zukunft gesetzt.
Schlussendlich geht es um mehr Werbung und Auswertung von Nutzungsdaten. Auf youronlinechoices [2] kann man anbieterweise einstellen, ob diese Nutzungsdaten zum Zwecke nutzungsbasierter Online Werbung verwenden dürfen. Facebook ist zwar als Partner aufgführt, aber ich habe es noch nicht geschafft, es bei Facebook zu deaktivieren. Aber man soll ja nie aufgeben ;-)
Weiterführende Links:
- Facebook Datenrichtlinie
- youronlinechoices - Präferenzmanagement
Update:
Um auf youronlinechoices alle Einträge deaktivieren zu können, muss man Adblocker, Ghostery, usw. kurzzeitig deaktivieren. Dann klappt es auch mit dem AUS-Schalter für Facebook.
Fr, 28. November, 2014
Nein, das mit dem Zusatz zur Version ist nur ein Witz - ein kleines Wortspiel :-)
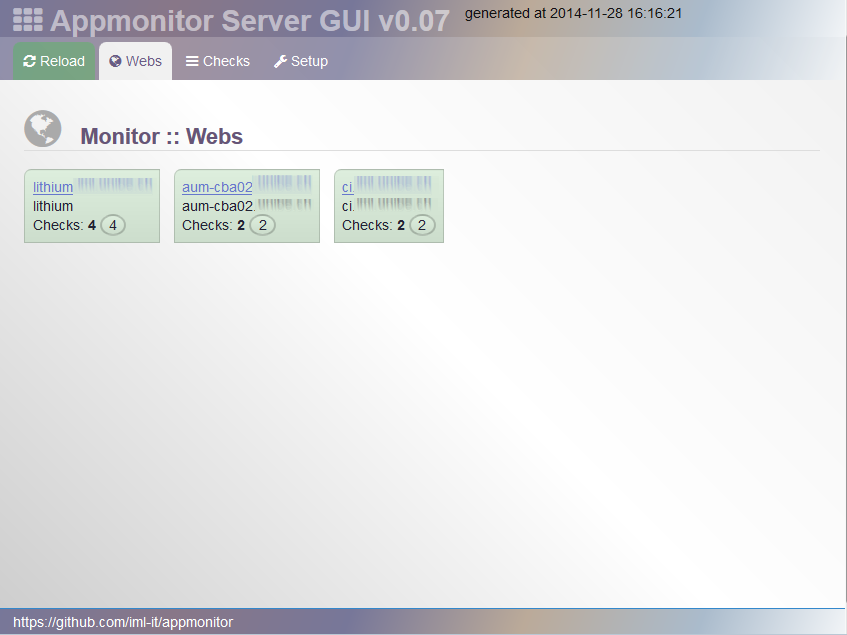
Aber im Ernst: Ich arbeite am Institut für Medizinische Lehre (IML) an der Uni Bern. Zum Monitoring von Web-Applikationen ist etwas in PHP Geschriebenes am Entstehen.
Das Grundprinzip ist:
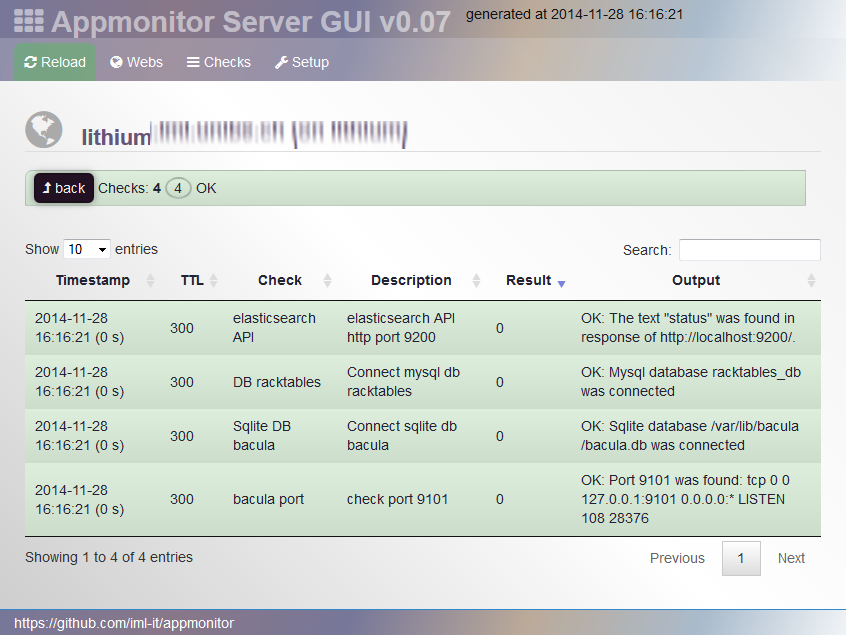
Web-Applikationen sollen als Client diverse Checks machen, was sie so zu ihrer Ausführung alles brauchen: Schreibrechte auf einem Verzeichnis, Verbindung zu einer Datenbank, Verbindung zu einem Remote-Server auf Port XY, whatever…
Jeden Check bewertet die Client-Applikation und stellt das Ergebnis ihrer Prüfung samt TTL (wann eine erneute Abfrage erfolgen darf) als JSON bereit. Weil das Format etwas neutrales ist, kann ein Client in verschiedenen Programmiersprachen geschrieben werden.
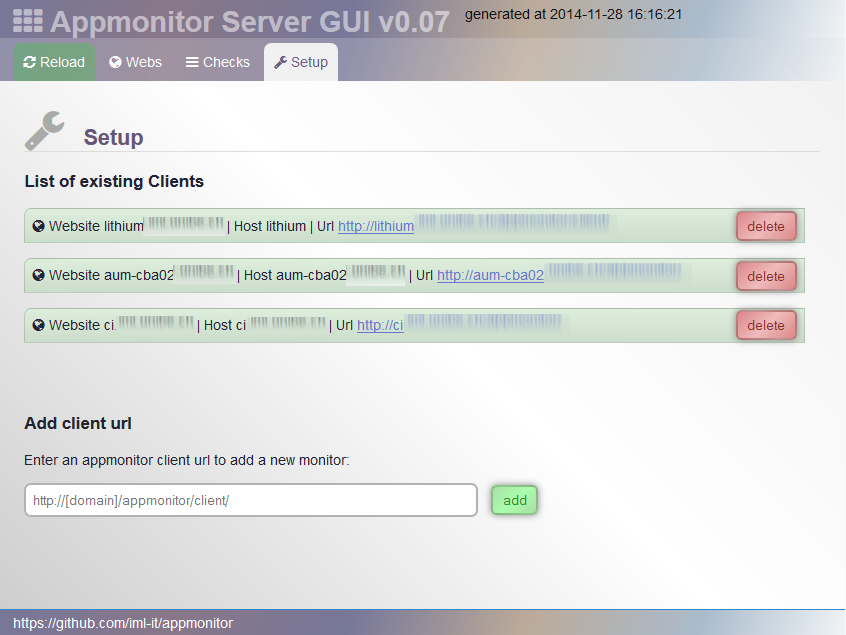
Ein Server sammelt die JSON Ergebnisse ein. Zunächst gibt es eine bunte Web-GUI - rein zum Ansehen des aktuellen Zustands (keine History). Neben der GUI soll beim Server in Kürze auch eine Schnittstelle für Monitoring-Systeme entstehen. Zunächst ein Nagios-Plugin für die Intregration in unser eigenes Monitoring.
UPDATE:
Die Screenshots haben rein “historischen Wert” - es wurde mittlerweile eine GUI mit AdminLTE darüber gestülpt. Github zeigt es bereits im Readme-Markdown.
Weiterführende Links:
Do, 27. November, 2014
Immer mal wieder gibt es Update bei meinen Tools.
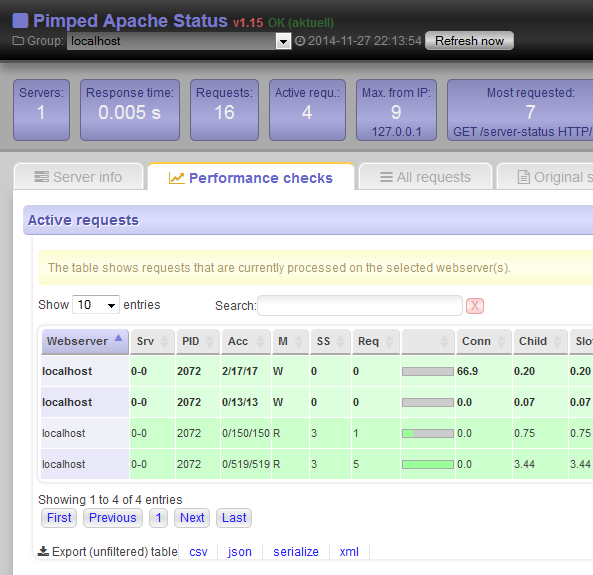
Beim Pimped Apache Status habe ich noch diverse Pläne. Ich wollte eigentlich Bootstrap 3 in ein Template verpacken, und es soll per WebGUI die Liste der Server und Tiles oben konfigurierbar werden, …
Nun, es sind heute “nur” die Icons eingecheckt worden und das Ganze wurde als Version 1.15 bereitgestellt.
Weiterführende Links:
Mo, 17. November, 2014
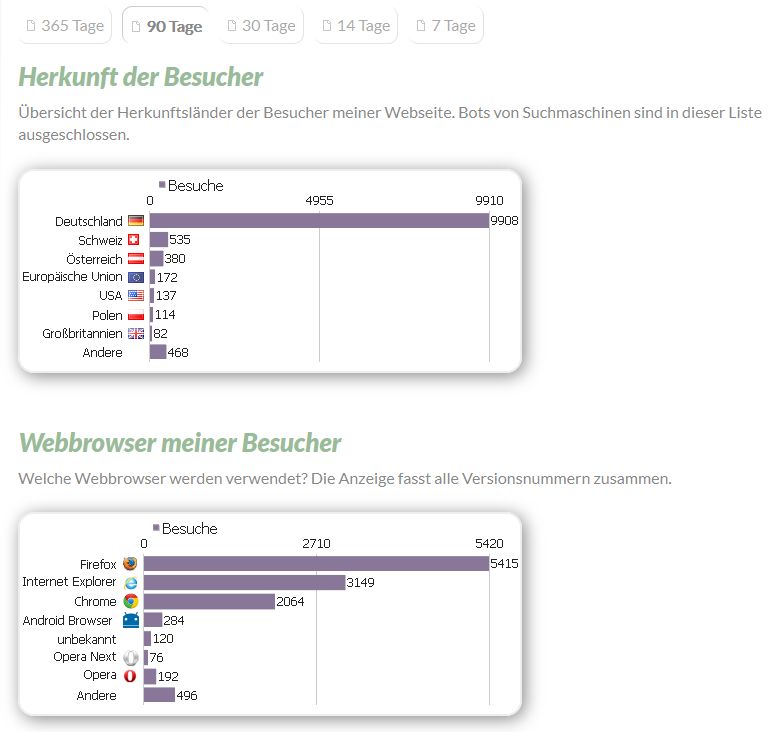
Ich wollte meine Statistik-Anzeige auf meiner Startseite etwas anders haben und die Grafiken von PIWIK [01] einbinden. Es gibt verschiedene APIs [02] zum Holen von Daten - als XML, JSON oder Grafik [03]. Aber die Grafiken sollten nicht mitsamt der URL der PIWIK-Api eingebunden sein - ich wollte die Grafiken holen, cachen und die gecachten Bilder einbinden.
Das Ergebnis auf der Webseite sieht dann so aus:
Konfiguration
Zunächst einmal die Basis-Daten als Konfiguration: Für die eigene Verwendung sind die Parameter anzupassen. Die Variablennamen sollten einleuchtend sein:
// anpassen
$sPiwikToken = ”419f6099c81111fdb6ae65…”;
$iPiwikSiteId = 7;
// Bildgroesse und Farbe
$iImageWidth = 500;
$iImageHeight = 200;
$sBarColor = ”887799”;
// Domain und Pfad zu Piwik anpassen
$sBaseUrl = ”http://[www.deine-domain.de/piwik]/index.php?module=API&method=ImageGraph.get”
. ”&idSite=$iPiwikSiteId&apiModule=[MODULE]&apiAction=[ACTION]”
. ”&period=range&date=last[DAYS]”
. ”&token_auth=$sPiwikToken”
. ”&width=$iImageWidth&height=$iImageHeight&colors=$sBarColor”;
[Weiterlesen…]
Mo, 3. November, 2014
Meine Webseite verwendet Concrete 5 als CMS.
Auf aktuelle Version 5.7 kann man dummerweise nicht upgraden, weil man im Unterbau zuviel geändert hat. Toll. Ich will einige Komponenten trotzdem aktualisieren.
Ich hatte so die famose Idee, auf meiner Webseite Bootstrap auszutauschen
VON v3.0
AUF v3.3
Der Konflikt besteht darin, dass das Backend mit Bootstrap 2 arbeitet und mit jQuery v1.7 daherkommt.
Bootstrap 3.3 braucht nun aber mind. jQuery 1.9. Mit vermeintlich gutem Gewissen habe ich die letzte 1-er Version von jquery heruntergeladen. Und mit jQuery 1.11 läuft wiederum das Bootstrap 2 Backend nicht mehr sauber.
Ein Teufelskreis ;-)
Erschwerend kommt hinzu, dass C5 das jQuery innerhalb
Loader::element(’header_required’);
irgendwo lädt (damit werden mehrere Html-Header Zeilen per echo rausgeschrieben).
Entweder man modifiziert Originale (davon rate ich per se ab), macht Custom-Elemente - oder ersetzt es in seinem Template. Letzters habe ich gemacht - mit Hilfe der ob_ Funktionen wird der Content abgegriffen und darin der Pfad zum jQuery File ersetzt.
// 2014-11-01 hahn
// HACK to use bootstrap 3.3 in live mode and concrete5 cms mode
// –> load specific jquery version
ob_start();
Loader::element(’header_required’);
$sHeadcontent = ob_get_contents();
ob_end_clean();
$u = new User();
if (!$u->isRegistered()) {
$sHeadcontent=str_replace(
’/concrete/js/jquery.js’, // or ’/updates/concrete[version]_updater/concrete/js/jquery.js’,
$this->getThemePath() . ’/js/jquery_1.11.1.js’,
$sHeadcontent
);
}
echo $sHeadcontent;
// ENDE jquery HACK
Eine andere Folge des jQuery Updates war die Inkompatibilität mit colorbox (Addon Lightboxed Image - 0.9.2).
Durch Aktualisieren der Dateien unter
[webroot]/packages/lightboxed_image/blocks/lightboxed_image
mit den aktuellen colorbox-Sourcen lief auch das wieder.
Update:
Eine andere Variante (die Auswirkung auf alle Themes hätte) wäre, die Datei concrete/elements/header_required.php in das Verzeichnis elements zu kopieren und dort anzupassen. So kommt man auch ohne die ob_-Funktionen aus.
weiterführende Links:
Di, 21. Oktober, 2014
Mit Sounds spielen macht einfach zuviel Spass. Diesmal mit 150 Sachen … äh: 150 bpm.
Downloads:
stereo: mp3 | ogg … und 5.1 surround: ogg | mp4
Sa, 20. September, 2014
Loriot: Das sieht aber sehr übersichtlich aus …
Mi, 10. September, 2014
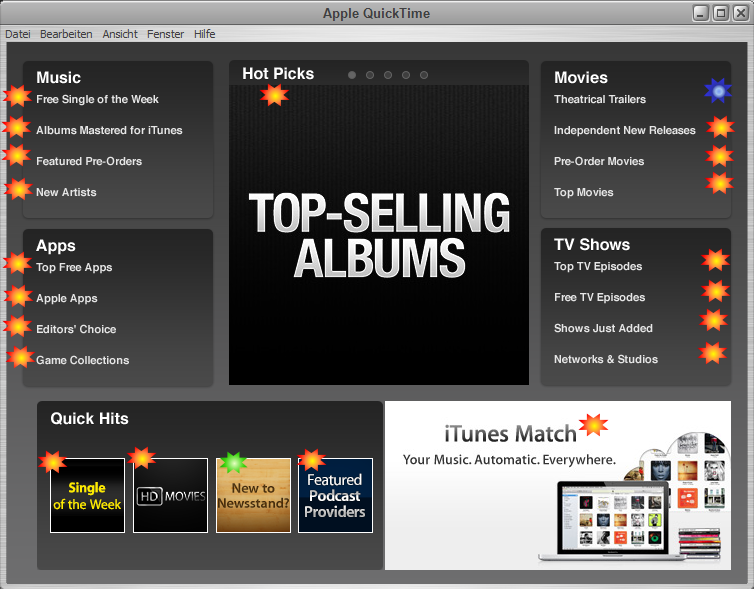
Mit choco install quicktime ist Apple Quicktime ja schnell installiert…
Startet man Quicktime, gibt es einen Startbildschirm mit viiiieeelen Links:
Ich habe mir mal erlaubt die Ziel-Links einzuzeichnen:
Nochmal langsam: es werden 20 (in Worten: zwanzig) Verlinkungen gesetzt, die allesamt auf dasselbe Ziel zeigen??
Und was ist das für ein Ziel auf eine Textwüste beim blau markierten Link?
Was in aller Welt ist der Sinn dieses Links?
Hey Apple, das ist eines euerer Produkte Stand zweitausendvierzehn!?
Was lasst ihr denn da für einen Sch(… rott) auf die Welt los?
Qualität ist etwas anderes.
UPDATE
(*) Link wurde deaktiviert
Di, 5. August, 2014
Ich habe eine E-Mail bekommen. Irgendein Arbogast Brock meint, mir unterstellen zu müssen, ich hätte zum Zeitpunkt XY mit IP irgendwas einen superdollen Film heruntergeladen.
Wie ich sowas liebe …
Ich war am 30.07.2014 im Urlaub - und es war keiner hier daheim - das MUSS also Unfug sein.
Die Anrede:
Arbogast weiss also nicht mal meinen Namen.
Die IP-Adresse:
72.91.170.240 - dazu kann man whois [IP-Adresse] aufrufen (unter Linux/ Mac ist es ein mitinstalliertes Kommandozeilentool - oder es gibt auch Webseiten, die diese Aufgabe lösen - einmal nach “whois” suchen).
Jedenfalls ist obiges eine IP der Fa. Verizon Online LLC in Ashburn (USA). Aha.
Wie dumm muss man sein, dass nicht einmal die IP des Landes des Angeschriebenen Opfers übereinstimmt?!
Arbogast weiss also nicht mal, wo ich eigentlich bin.
Der Anhang:
Im Anhang ist ein CAB-Archiv. Darin wiederum ist eine EXE-Datei.
Warum genau sollte ich nochmal eine EXE-Datei von einem unbekannten Absender - ohne eine angegebene Adresse öffnen?
Gesehen .. gelacht .. F8.
Mo, 19. Mai, 2014
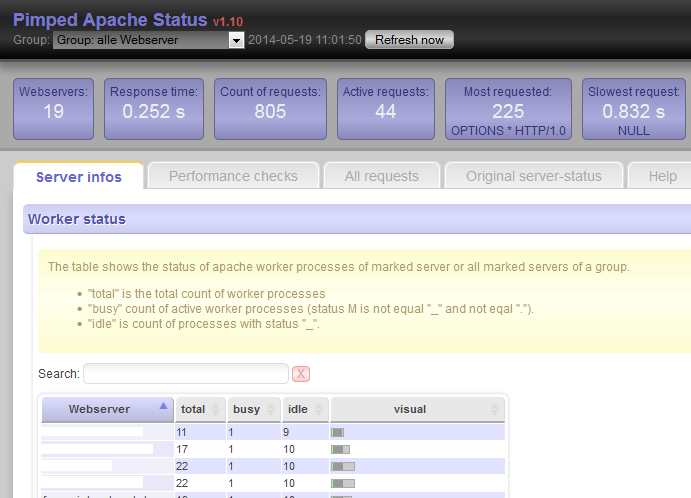
Mein PHP Tool “Pimped Apache Server Status” macht den Apache Status lesbar. Dies funktioniert auch mit mehreren Webservern gleichzeitig und eignet sich so auch zum Live Monitoring von loadbalancten Webseiten.
Im letzten Update kamen 2 Boxen in der oberen Reihe hinzu. Sie zeigen die Anzahl der abgefragten Webserver an und wie lange dies brauchte.
Im LAN bei mir auf Arbeit wird der Status von 19 Webservern in weniger als 0.3 Sekunden geholt.
Wie weit es nach oben skaliert, weiss ich noch nicht. Erfahrungsberichte von anderen Webmastern/ Sysadmins sind daher willkommen!
Update:
Ich habe mich noch einmal genauer belesen…
Die einzelnen Apache Server status werden in der Methode ServerStatus->getStatus() (s. Datei ./classes/serverstatus.class.php) mittels curl_multi_exec() geholt. Bei dieser Funktion erfolgen die Requests - wie ich es auf php.net lese - sequentiell.
Erst ab PHP Version 5.5 gibt es eine Funktion curl_multi_setopt, mit der man parallele Requests steuern kann - aber auf diese PHP-Version ist mein Tool noch nicht getrimmt.
Weiterführende Links: