Mi, 14. Juli, 2021
Der grafische Software-Manager wollte pacman nicht aktualisieren … und wegen jenes Konflikts alle möglichen Pakete auch nicht.
Dann aktualisere ich halt “pamac upgrade pacman” von Hand und schaue, was passiert.
axel@mypc~> pamac upgrade pacman
(…)
vulkan-intel 21.1.4-1
(21.1.2-1) extra 2.3 MB
vulkan-radeon 21.1.4-1
(21.1.2-1) extra 1.7 MB
wireless-regdb 2021.04.21-1
(2020.11.20-1) core 10.3 kB
Wird installiert (10):
syndication 5.84.0-1
extra 1.0 MB
electron12 12.0.14-1
community 50.7 MB
layer-shell-qt 5.22.3-1
extra 23.1 kB
ksystemstats 5.22.3-1
extra 162.9 kB
pahole 1.21-1 extra
262.9 kB
nodejs-nopt 5.0.0-2
community 13.4 kB
libpamac 11.0.1-3 (Ersetzt:
pamac-common) extra 818.4 kB
kio-fuse 5.0.1-1 extra
70.3 kB
fakeroot 1.25.3-2 core
bison 3.7.6-1 core
Zu erstellen (2):
package-query 1.12-1 (1.10-1) AUR
zoom 5.7.1-1 (5.6.7-1) AUR
Wird entfernt (1):
pamac-common 10.0.6-2 (Konflikt mit: libpamac)
Download-Größe gesamt: 2.3 GB
Gesamtgröße installiert: 269.3 MB
Gesamtgröße entfernt: 9.5 MB
Build-Dateien bearbeiten : [e]
Transaktion durchführen ? [e/j/N] j
Warning: installing pacman (6.0.0-1) breaks dependency ’pacman<5.3′
required by package-query
Add package-query to remove
Fehler: Failed to prepare transaction:
could not satisfy dependencies:
- removing package-query breaks dependency ’package-query>=1.9′ required
by yaourt,
- if possible, remove yaourt and retry
Leider nein.
Beim Lesen von “installing pacman (6.0.0-1) breaks dependency ‘pacman<5.3' " dachte ich schon fast: oh, ein Henne-Ei-Problem?
Die Lösung:
Ich bin einfach dem letzten Rat in der Ausgabe gefolgt und habe yaourt entfernt.
axel@mypc~ [1]> pamac remove yaourt
Vorbereitung…
Abhängigkeiten werden überprüft…
Wird entfernt (1):
yaourt 1.9-2
Gesamtgröße entfernt: 849.9 kB
Transaktion durchführen ? [j/N] j
Removing yaourt (1.9-2)… [1/1]
Vorgang erfolgreich abgeschlossen.
Und nun nochmal der Versuch eines Updates …
axel@mypc~> pamac upgrade pacman
…
… hurra, nun klappt es!
weiterführende Links:
- manjaro.org (en)
Do, 8. Juli, 2021
Um die Frage des Titels zu beantworten, kommt man schnell auf ein … als root startet man
su - [USERNAME] -c [KOMMANDO]
Und wenn der User, unter dem ich das Kommando starten will, keine Shell hat? Tja, dann kommt eine Fehlermeldung der Art
This account is currently not available.
Wirklich sehr lange habe ich mir beholfen, dass ich dem User in der /etc/passwd eine Shell gegeben habe - das /usr/bin/nologin oder /bin/false wurde durch ein /bin/bash o.ä. ersetzt. Jaja, ganz generell fördern man [Kommando] oder [Kommando] –help hilfreiche Dinge zutage. Aber das ist völlig unnötig. Der “Trick” ist, dass man bei su mit dem Parameter -s eine Shell vorgibt, z.B. die /bin/sh.
su - [USERNAME] -c [KOMMANDO] -s /bin/bash
Um die Parameter wegzulassen und optisch zu vereinfachen, kann man auch eine kleine Funktion in sein Skript setzen:
# run a command as another posix user (even if it does not have a shell)
#
# example:
# runas www-data ”/some/where/mysript.sh”
#
# param string username
# param string command to execute. Needs to be quoted.
# param string optional: shell (default: /bin/sh)
function runas(){
local _user=$1
local _cmd=$2
local _shell=$3
test -z ”$_shell” && _shell=/bin/sh
su $_user -s $_shell -c ”$_cmd”
}
Dann kann man im Skript etwas kürzer schreiben:
runas [USERNAME] [KOMMANDO]
weiterführende Links:
- man7.org: Manpage für su
Do, 24. Juni, 2021
Wenn eine bestehende Mysql Replikation nicht mehr funktioniert, so half mir etliche Male im Laufe der Berufszeit als Webmaster beim Schweizer Radio DRS / Sysadmin Daseins an der Uni Bern ein top-down-Skript weiter. Wenn gerade Stress ist und man in der Situation nicht erst alle Kommandos zur Wiederinbetriebnahme des Slave nachschlagen mag, dann ist ist man froh, wenn man ein Skript dafür parat liegen hat.
reinit_mysql_replication.sh
Es gibt keine Parameter.
Installation:
Man benötigt einen Mysql Client. Ich hatte daher die Skripte am Mysql-Slave unterhalb /root zu liegen. Daher ist die Verbindung zum Slave ohne Passwort (wird aus der /root/.my.cnf gelesen).
Es wird auch vom eigenen Rechner aus funktionieren, der die Mysql-Ports von Master und Slave erreichen kann. Es ist nur “einen Tick” langsamer (sprich: bei vielen und/ oder grossen Datenbanken > 1 GB Gesamtgrösse nicht zu empfehlen).
Konfiguration:
Die *dist Datei ist umzukopieren und die Hostnamen und Root-Passwörter für Master + Slave sind zu setzen.
Start:
Das Skript reinit_mysql_replication.sh führt der Reihe nach folgende Aktionen aus: es …
- zeigt aktuellen Slave Status
- wartet dann auf ein RETURN, bevor die Replikation neu aufgesetzt wird
Aktionen zum Neuaufsetzen der Replikation: das Skript …
- liest die Position des Binlog am Master (per SQL “SHOW MASTER STATUS G;”)
- sperrt den Master für Schreibaktionen (”FLUSH TABLES WITH READ LOCK;”)
- holt aktuelle Datenbank-Dumps vom Master (mysqldump –all-databases –lock-all-tables …)
- hebt Schreibsperre am Master auf (”UNLOCK TABLES;”)
- stoppt den Slave (”STOP SLAVE G;”)
- importiert Dumps des Master auf dem Slave (cat $dumpMaster | mysql $paramdbSlave)
- setzt am Slave binfile und Position (”CHANGE MASTER TO MASTER_LOG_FILE = …” ; “CHANGE MASTER TO MASTER_LOG_POS = …”)
- startet den Slave (”START SLAVE G;”)
weiterführende Links:
- git-repo.iml.unibe.ch: iml-open-source/mysql-slave-scripts
Fr, 30. April, 2021
Ttyrec ist ein Open Source Werkzeug, mit dem man auf der Konsole alle Eingaben “mitschneiden” kann. Damit lassen sich Demos zur Handhabe von Installationen anfertigen oder ASCII Animationen aufzeichnen. Zur Wiedergabe gibt es ein ttyplay - oder für Webseiten auch einen Video Player, um eigene Online Dokumentationen zu ergänzen.
BTW: von ttyrec gibt es noch Portierungen in anderen Programmiersprachen, wie Python, Go, …
Aber zurück zu Manjaro. Es gibt mehrere AUR Pakete, um ttyrec auf Manjaro Linux builden zu lassen. Der Compilervorgang schlug bei mir aber jeweils fehl, weil ein man Verzeichnis bereits existiert:
Fehler: Vorgang konnte nicht abgeschlossen werden:
In Konflikt stehende Dateien:
- ovh-ttyrec-git: /usr/local/share/man existiert bereits im Dateisystem (gehört zu filesystem)
Die Lösung klingt etwas zu einfach … aber immerhin funktioniert es: man schaut einmal, was in diesem Verzeichnis ist und benennt es temporär um, um es dann anschliessend nach der Complilierung wiederherzustellen.
Gesagt - getan … und mit einem Underscore umbenannt:
axel@tux > sudo -i
root@tux# ls -l /usr/local/share/man
lrwxrwxrwx 1 root root 6 20. Jan 17:33 /usr/local/share/man -> ../man
root@tux# mv /usr/local/share/man /usr/local/share/man_
Ja, dann installieren / compilieren wir das nochmal … und starten pamac install ovh-ttyrec-git
root@tux# pamac install ovh-ttyrec-git
Warnung: ovh-ttyrec-git ist nur im AUR verfügbar
Vorbereitung…
Klone ovh-ttyrec-git Build-Dateien…
Running as unit: run-u161595.service
Finished with result: success
Main processes terminated with: code=exited/status=0
Service runtime: 309ms
Running as unit: run-u161597.service
Finished with result: success
Main processes terminated with: code=exited/status=0
Service runtime: 9ms
Überprüfe ovh-ttyrec-git Abhängigkeiten…
Abhängigkeiten werden aufgelöst…
Interne Konflikte werden überprüft…
Zu erstellen (1):
ovh-ttyrec-git v1.1.6.3.r0.gb8bdaab-1 AUR
Build-Dateien bearbeiten : [e]
Transaktion durchführen ? [e/j/N] j
Erstelle ovh-ttyrec-git…
Running as unit: run-u161604.service
Press ^] three times within 1s to disconnect TTY.
==> Making package: ovh-ttyrec-git v1.1.6.7.r1.ga13ca74-1 (Di 13 Apr 2021 17:24:30)
==> Checking runtime dependencies…
==> Checking buildtime dependencies…
==> Retrieving sources…
-> Updating ovh-ttyrec git repo…
Fetching origin
==> Validating source files with sha256sums…
ovh-ttyrec … Skipped
==> Removing existing $srcdir/ directory…
==> Extracting sources…
-> Creating working copy of ovh-ttyrec git repo…
Cloning into ’ovh-ttyrec’…
done.
Switched to a new branch ’makepkg’
==> Starting prepare()…
Looking for compiler… gcc
Checking if compiler can create executables… yes
Checking how to get pthread support… -pthread
Looking for libzstd… yes
Checking whether we can link zstd statically… no
Looking for isastream()… no
Looking for cfmakeraw()… yes
Looking for getpt()… yes
Looking for posix_openpt()… yes
Looking for grantpt()… yes
Looking for openpty()… yes (pty.h, libutil)
Checking for supported compiler options…
… OK -Wall
… OK -Wextra
… OK -pedantic
… OK -Wno-unused-result
… OK -Wbad-function-cast
… OK -Wmissing-declarations
… OK -Wmissing-prototypes
… OK -Wnested-externs
… OK -Wold-style-definition
… OK -Wstrict-prototypes
… OK -Wpointer-sign
… OK -Wmissing-parameter-type
… OK -Wold-style-declaration
… OK -Wl,–as-needed
… OK -Wno-unused-command-line-argument
You may run make now
==> Starting pkgver()…
==> Starting build()…
(…)
Vorgang erfolgreich abgeschlossen.
Das “erfolgreich abgeschlossen” klingt ja schonmal gut.
Jetzt muss ich nur noch das man Verzeichnis wiederherstellen. Durch das Complilieren entstand:
root@tux# ls -l /usr/local/share/man/man1/
insgesamt 12
-rw-r–r– 1 root root 641 13. Apr 17:24 ttyplay.1.gz
-rw-r–r– 1 root root 1751 13. Apr 17:24 ttyrec.1.gz
-rw-r–r– 1 root root 308 13. Apr 17:24 ttytime.1.gz
In /usr/local/share/ sieht es nun so aus:
root@tux# ls -l
insgesamt 4
lrwxrwxrwx 1 root root 6 20. Jan 17:33 man -> ../man
drwxr-xr-x 3 root root 4096 13. Apr 17:24 man_ttyrec
Hier muss man nur das man_ttyrec/man1 in das man hineinschieben.
root@tux# mv man_ttyrec/man1/ ../man
Und das war’s dann.
Hurra, das Paket ist erfolgreich installiert… und ttyrec lässt sich starten.
weiterführende Links:
- Wikipedia: ttyrec (en)
- Arch-Linux AUR: Suche nach ttyrec (en)
Mi, 28. April, 2021
Restic [1] ist ein in Go geschriebenes Backup-Tool für die Kommandozeile … oder zum Skripten. Es besteht aus einem einzigen Binary und hat keinerlei Abhängigkeiten zu Libs, Paketen oder irgendwas. Es erzeugt dedulizierte Backups: initial wird ein Vollbackup gemacht und dann nie wieder - es braucht dann nur noch inkrementelle Backups. Restic gibt es für Windows/ Mac/ Linux und diverse Plattformen (BSD, Solaris, Mips, … - siehe Releases (dort etwas scrollen :-) [2]).
Das hat was.
Daheim werfe ich gerade einen Http-Server als Backup-Endpoint auf die Synology [3].
Auf Systeme am Institut habe ich grob 150 Linux-Systeme - mit altem und neuen Linux Varianten verschiedener Distributionen. Ich habe ein Bash Skript geschrieben, das mit wget das Binary des Restic Client holt, entpackt und ins /usr/bin legt. Wer es für ein anderes OS oder Architektur braucht, müsste den Suffix “_linux_amd64” ersetzen … oder aber auch dynamisch machen (mit
uname -a
könnte man hinkommen).
#!/usr/bin/env bash
# ——————————————————
# CONFIG
# ——————————————————
resticversion=0.12.0
doLink=0
installdir=/usr/bin
resticfile=restic_${resticversion}_linux_amd64
downloadfile=${resticfile}.bz2
downloadurl=https://github.com/restic/restic/releases/download/v${resticversion}/${downloadfile}
# ——————————————————
# MAIN
# ——————————————————
echo
echo ”##### INSTALL RESTIC CLIENT into $installdir #####”
echo
echo —– DOWNLOAD
if [ ! -f ”${downloadfile}” ]; then
wget -O ”${downloadfile}.running” -S ”${downloadurl}”
&& mv ”${downloadfile}.running” ”${downloadfile}”
else
echo SKIP download
fi
echo
echo —– UNCOMPRESS
bzip2 -d ”${downloadfile}”
echo
echo —– INSTALL
mv ”${resticfile}” ”${installdir}”
chmod 755 ”${installdir}/${resticfile}”
rm -f ”${installdir}/restic” 2>/dev/null
test $doLink -eq 0 || ln -s ”${installdir}/${resticfile}” ”${installdir}/restic”
test $doLink -eq 0 && mv ”${installdir}/${resticfile}” ”${installdir}/restic”
echo
echo —– SELF-UPDATE
restic self-update
echo
echo —– RESULT:
test $doLink -eq 0 || ls -l ”${installdir}/${resticfile}”
ls -l ”${installdir}/restic”
echo
echo —– CURRENT VERSION:
restic version
echo
echo —– DONE
weiterführende Links:
- https://restic.net/ Homepage von Restic
- Github: Restic Releases
- Github: Skript zur Installation eines Restic Http Servers auf einer Synology
Sa, 10. Oktober, 2020
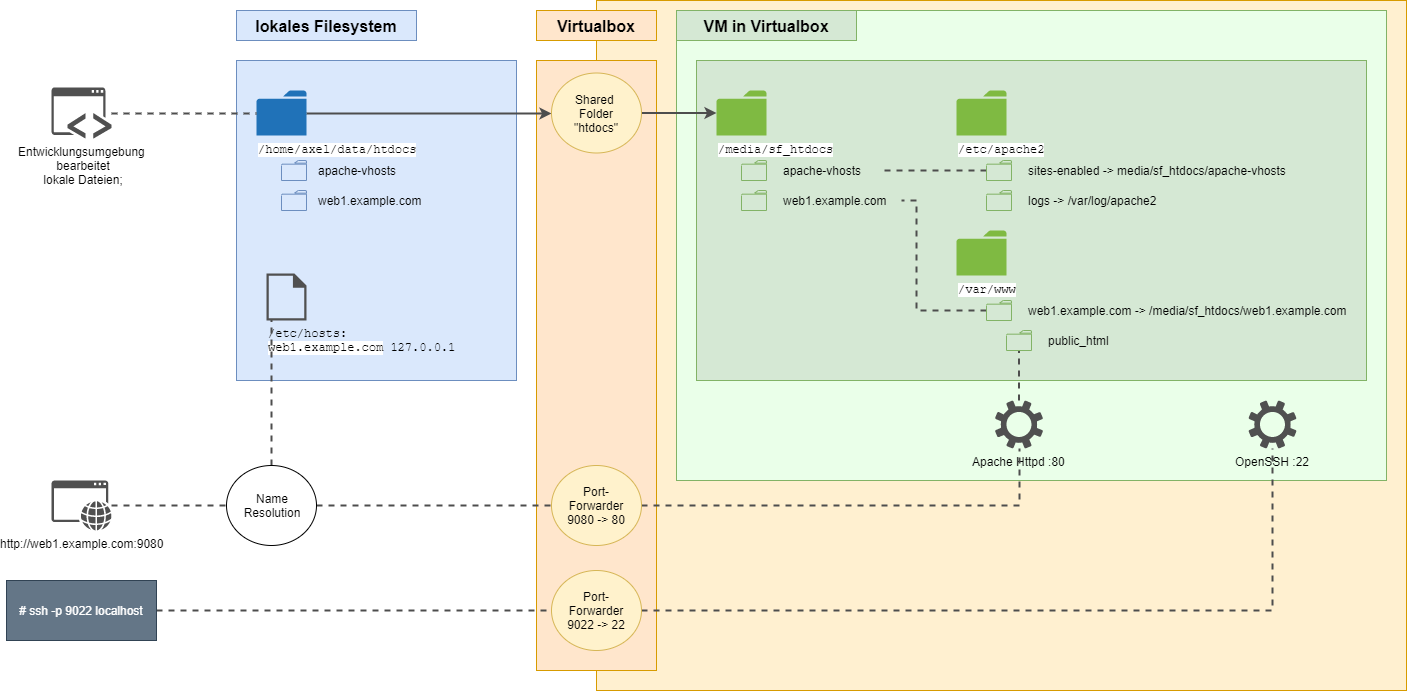
Wenn man auf seiner lokalen Maschine entwickelt - aber seinen Code auf mehreren Betriebsystemen - oder unterschiedlichen Software-Versionen - sei es z.B. Programmiersprache (Ruby, NodeJs, PHP) oder Datenbankversion - dann braucht man verschiedene Testsysteme. Der eine mag Docker bevorzugen … ich beschreibe die Variante mit Virtualbox, weil dies über Linux und Windows für Clients als auch Ziel-VMs durchmischt funktioniert.
— Virtualbox.
Virtualbox ist kostenlos und OpenSource. Es existiert für Windows, Mac, Linux und Solaris.
In der Virtualbox habe ich je 1 VM mit einer Linux-Instanzen installiert (Debian, CentOS). In der VM ist das Setting installiert, was ich zum Testen heranziehen möchte.
- Zum einen SSH, damit ich von der Konsole auf die VM komme - ohne dass ich über das “Fenster” der VM gehen muss.
- Und dann Webserver, Programmiersprache, Module, Libraries … und was es sonst auf dem Zielsystem braucht.
— Dateien der Applikation
Was hingegen NICHT in der VM ist, ist die Applikation / Webseite: diese ist lokal bei mir auf dem Rechner. Ich nenne es mal abstrakt: web1.example.com.
[meine Webs] <<< Basisverzeichnis aller meiner Webseiten
|
+– …
+– web1.example.com <<< Verzeichnis ist Name der Webseite/ Applikation
| |
| +– …
| +– public_html <<< jenes public_html ist DOCUMENT_ROOT der Webseite
| +– …
+– …
Um diese Struktur in einer Virtualbox VM verfügbar zu machen, hat Virtualbox ein Feature der Shared Folders. Das lokale Verzeichnis meiner Webdaten wird dann automatisch ins Linux reingemountet und ist unter /media/sf_[Name]/ sichtbar.
Man könnte nun im Apache Httpd das Web als VHost einrichten und Document_root auf das /media Verzeichnis zeigen lassen. Ich mag es aber, wenn es an einem schönen Ort liegt. Daher lege ich unter /var/www einen Softlink namens web1.example.com an, der auf /media/sf_[Name]/web1.example.com/ zeigt.
Wenn man Linux-Systeme zum Testen braucht - z.B. Debian und CentOS - dann kann man die Apache Config auch lokal halten … und einen Softlink als /etc/apache2/sites-enabled bzw. /etc/httpd/conf.d anlegen.
Mit der lokal installierten IDE meiner Wahl kann ich dann lokal meine Dateien bearbeiten - und mit Speichern habe ich es 1:1 in einer gestarteten VM.
— Dienste
Zum Zugriff per SSH … oder auf das Web muss ich jede laufende VM ansprechen können - auf deren Port 80/ 443 resp 22.
Virtualbox kennt dazu in den Netzwerkeinstellungen der VM das Portmapping.
Es braucht eindeutige Ports, wenn man mehrere VMs laufen lassen und diese parallel ansprechen wollte, z.B. VM 1 leitet SSH von 8022 auf 22 um, VM 2 geht 1000 Ports hoch und leitet 9022 auf 22 um; Port 80 und andere analog SSH Login auf VM 2:
ssh -p 9022 localhost
Und beim Webbrowser? Und mehreren VHosts in der jeweiligen VM?
Man kann sich mit der /etc/hosts behelfen und die Namen der Domain auf 127.0.0.1 zeigen lassen
web1.example.com 127.0.0.1
Im Browser gibt man mit http://web1.example.com:[Port] das jeweilige Web an … und der Port steuert die Anfrage zur gewünschten VM.
Grafisch sieht das Ganze etwa so aus:
Viel Spass beim Nachbauen!
weiterführende Links:
- www.virtualbox.org/ (en)
Mo, 28. September, 2020
Ich möchte Mysql/ MariaDB Server monitoren. Dazu legt man einen Monitoring-User in der Datenbank an, der dann Select Rechte auf mysql.* bekommt, um aus der Datenbank Statusinformationen zu lesen. Der User soll ein langes Zufallspasswort bekommen. Die Installation muss mit dem root User auf der Datenbank erfolgen.
Im Monitoring Modus will ich kein Passwort als Parameter übergeben, damit es nicht in der Prozessliste erscheinen kann. Dies lässt sich mit einer .my.cnf im HOME Verzeichnis bewerkstelligen.
Schritt 0: Vorbereitung
Initial setze ich mein HOME und die Variable cfgfile auf die .my.cnf:
# — set HOME
HOME=/etc/icinga2-passive-client
# — other vars…
cfgfile=$HOME/.my.cnf
myuser=icingamonitor
datafile=/tmp/mysql-status.txt
Schritt 1: Ein Zufalls-Passwort erzeugen.
Ich will nur parametriesieren können, wie lang das zu erstellende Passwort ist … daher die Variable vorab.
Das Passwort kommt durch eine Ausgabe des Zufallsgenerators /dev/urandom zustande - wobei mittels tr nur Ziffern und Buchstaben gefiltert werden.
pwlength=64
mypw=$( head /dev/urandom | tr -dc A-Za-z0-9 | head -c $pwlength )
Schritt 2: Mysql-User mit Rechten anlegen.
Dieser Aufruf funktioniert nur mit dem root (oder anderen zusätzl. angelegten Admin-) User.
Wenn Linux-Root passwortlosen Zugriff auf den Datenbank-Root-User hat, muss man das HOME auf /root setzen, damit dessen .my.cnf gefunden wird.
HOME=/root
mysql -e ”CREATE USER $myuser@localhost IDENTIFIED BY ’$mypw’;”
if [ $? -ne 0 ]; then
echo ”ERROR: mysql command to create user failed.”
exit 1
fi
echo ”- grant SELECT on mysql tables …”
mysql -e ”GRANT SELECT ON mysql.* TO $myuser@localhost;”
if [ $? -ne 0 ]; then
echo ”ERROR: mysql command to grant permissions failed.”
exit 1
fi
echo ”- flush privileges …”
mysql -e ”FLUSH PRIVILEGES;”
OK, damit habe ich nun meinen Datenbank-User. Dessen Passwort ich selbst nicht kenne, aber ich weiss, dass es 64 Zufalls-Zeichen besitzt und “halbwegs” safe sein dürfte. Damit erspare ich mir bei zig-zig lokalen Mysql/ MariaDb Services die Verwaltung der Kennwörter für den Monitoring-User.
Schritt 3: Mysql-User-Konfigurationsdatei anlegen.
Die Konfigurationsdatei ist in einem Verzeichnis des Monitoring-Users anzulegen. Zum Erzeugen der Datei wird hier nur auf $cfgfile zurückgegriffen.
cat >$cfgfile <<EOF
#
# generated on `date`
#
[client]
user=$myuser
host=localhost
password=$mypw
EOF
ls -l $cfgfile
if [ $? -ne 0 ]; then
echo ”ERROR: creation of config file failed.”
exit 1
fi
Nachdem Schritte 1..3 als root erfolgten, sollte bei Aufruf des Skripts mit dem Monitoring User das $HOME wie in Schritt 0 umgebogen sein, damit die soeben erzeugte .my.cnf angezogen wird. Und voila: dann hat der Monitoring Aufruf einen passwortlosen Zugriff.
Man kann den Status lesen, dies in eine Datei umleiten … und dann die gewünschten Variablen per grep lesen.
function _mysqlreadvars(){
mysql -e ”SHOW GLOBAL VARIABLES ;” –skip-column-names >$datafile
mysql -e ”SHOW STATUS ;” –skip-column-names >>$datafile
}
function _mysqlgetvar() {
local sVarname=$1
grep ”^$sVarname[^_a-z]” ${datafile} | awk ’{ print $2 }’
}
# init
_mysqlreadvars
_mysqlgetvar max_connections
_mysqlgetvar Max_used_connections
# cleanup
rm -f $datafile
Die Codeschnipsel sind zur Veranschaulichung aus dem Gesamtkontext herausgerissen. Das komplette Skript ist unten verlinkt.
weiterführende Links:
- git-repo.iml.unibe.ch: check_mysqlserver
Mo, 17. August, 2020
Meine Audiowiedergabe ging plötzlich nicht mehr … Also irgendetwas stimmt hier nicht.
als root:
# aplay -l
**** List of PLAYBACK Hardware Devices ****
card 0: NVidia [HDA NVidia], device 3: HDMI 0 [HDMI 0]
Subdevices: 1/1
Subdevice #0: subdevice #0
card 0: NVidia [HDA NVidia], device 7: HDMI 1 [HDMI 1]
Subdevices: 1/1
Subdevice #0: subdevice #0
card 0: NVidia [HDA NVidia], device 8: HDMI 2 [HDMI 2]
Subdevices: 1/1
Subdevice #0: subdevice #0
card 0: NVidia [HDA NVidia], device 9: HDMI 3 [HDMI 3]
Subdevices: 1/1
Subdevice #0: subdevice #0
card 0: NVidia [HDA NVidia], device 10: HDMI 4 [HDMI 4]
Subdevices: 1/1
Subdevice #0: subdevice #0
card 1: Generic [HD-Audio Generic], device 0: ALC892 Analog [ALC892 Analog]
Subdevices: 1/1
Subdevice #0: subdevice #0
card 1: Generic [HD-Audio Generic], device 1: ALC892 Digital [ALC892 Digital]
Subdevices: 1/1
Subdevice #0: subdevice #0
OK, anhand der letzten gelisteten Geräte wird Audiohardware nach wie vor gefunden.
# pacmd list-sinks
No PulseAudio daemon running, or not running as session daemon.
als User: wenn ich versuche, den Pulseaudio Dienst zu starten:
$ pulseaudio –start
W: [pulseaudio] core-util.c: Failed to open configuration file ’/home/axel/.config/pulse//daemon.conf’: Permission denied
W: [pulseaudio] daemon-conf.c: Failed to open configuration file: Permission denied
Das ist doch mal ein klarer Hinweis.
Im .config Verzeichnis gehörte alles meinem User - ausser dem pulse Verzeichnis:
$ ls -ld /home/axel/.config/pulse/
drwx—— 2 root root 4096 Jul 31 23:18 pulse/
So kann ein Prozess im Userkontext auch nicht zugreifen. Als root habe ich rekursiv den Owner gewechselt:
# chown -R axel. /home/axel/.config/pulse/
… und dann klappte der Start von Pulseaudio als User imTerminal auch
$ pulseaudio –start
… und auch die Wiedergabe und Lautstärkesteuerung waren wieder da.
Fr, 31. Juli, 2020
An “meinem” Institut geht ohne Open Source eigentlich nichts. Damit wir nicht nur nehmen, geben wir an und wann auch etwas als Open Source zurück. Für dieses Thema wird auf unserer Instituts-Webseite kein Platz eingeräumt, daher publiziere ich es hier in meinem privaten Blog.
Ich habe seit Anfang des Jahres eine Icinga Instanz bei uns aufgebaut. Als Icinga-Client auf unseren Servern verwenden wir ein Bash-Skript, das die REST API des Icinga-Servers als auch des Directors anspricht.
Es gibt es diverse mit Bash geschriebene Checks, die die Standard-Nagios Checks ergänzen (und nur teilw. ersetzen). Zur Abstraktion diverser Funktionen, wie z.B.
- Prüfung auf notwendige Binaries im Check
- Schreiben von Performance-Daten
- Handhabe von Exitcodes
… gibt es eine Include Datei, die gemeinsame Funktionen beherbergt. Oder anders: wer einen der Checks verwenden möchte, muss neben dem Check auch einmal die Include-Datei übernehmen.
Die Sourcecodes der Checks sind nun publiziert in [1].
Viele Plugins schreiben Performance-Daten, die wir mit dem Icinga-Graphite-Modul visualisieren. Die unsrigen Ini-Dateien der Graph-Templates liegen in einem separaten Repository [2]. Beim Schreiben der Ini-Dateien der Graph-Templates kam ich immer wieder ans Limit und es gibt (noch?) nicht so wirklich viele dokumentierte Vorlagen. Und so manche in Graphite dokumentierte Funktionen greifen (scheinbar?) nicht in den Inis für Icinga Graphite.
Ich hoffe, dass trotz ausbaufähiger Dokumentation der ein oder andere doch entwas mitnehmen kann.
Ich kann mir gut vorstellen, den ein oder anderen Check noch einmal im Detail hier im Blog vorzustellen.
weiterführende Links: (en)
- git-repo.iml.unibe.ch: icinga-checks
- git-repo.iml.unibe.ch: icinga-graphite-templates
- Graphite - Icinga Web 2 Module
- Graphite Functions
Di, 14. Juli, 2020
Wenn man im Monitoring einen Check schreiben will, der die Antwort-Zeit einer Aktion oder Response eines Servers messen will, sind sekundengenaue Angaben zu grob. Mit dem Kommando
time [Kommando]
kann man sehen, wie lange das jeweilige Kommando brauchte:
$ time ls
[… Liste von Dateien …]
real 0m0,022s
user 0m0,000s
sys 0m0,015s
Die Gesamtzeit ist in der Zeile real enthalten. Angegeben sind die Minuten, ein “m” und danach die Sekunden mit 3 Nachkommastellen. Wobei die Tausendstel je nach System/ Sprache mit Punkt oder Komma getrennt sein könnten.
Aha, nun muss man “nur” noch die Zeile mit der Angabe “real” in den letzten 3 Zeilen der gesamten Ausgabe suchen und das Ganze parsen.
Als kleines Demo anbei einmal mundgerecht als Funktion (es läuft unter Linux und mit CYGWIN unter MS Windows):
#!/usr/bin/env bash
# —— FUNCTION
# measure time in ms
# @param string command to execute / measure
function getExecTime(){
local sCommand=$1
local tmpfile=$( mktemp )
( time eval $sCommand ) >$tmpfile 2>&1
local sRealtime=`cat $tmpfile | tail -3 | grep ”^real” | awk ’{ print $2 }’`
rm -f $tmpfile
local iMin=`echo $sRealtime | cut -f 1 -d ”m” `
local iMillisec=`echo $sRealtime | cut -f 2 -d ”m” | sed ”s#[.,s]##g” | sed ”s#^0*##g” `
typeset -i local iTime=$iMin*60000+$iMillisec
echo $iTime
}
# —— MAIN
echo
echo ”ZEITMESSUNG IN MILLISEKUNDEN”
echo
mytime=`getExecTime ’ls -ltr’`
echo Dauer: ${mytime} ms