Mo, 7. November, 2022
Ich habe auf meinem Linux PC Streamtuner2 installiert. Das ist ein Browser von (Radio)Streaming Diensten mit deren Kategorien an Musikrichtungen. Was beim Druck auf [Play] zur Wiedergabe oder [Record] zur Aufnahme passieren soll, lässt sich konfigurieren.
Die Wiedergabe - es ist VLC vorkonfiguriert - funktioniert wunderbar. Das reicht wohl Vielen.
Zur Aufnahmefunktion … huh, da wird es langsam kompliziert. Vorkonfiguriert war das Öffnen eines Terminals. Das nimmt naturgemäss ja noch nichts auf. Das Standardwerkzeug unter Linux ist der Streamripper. Den muss man erst einmal konfigurieren.
Das habe ich gemacht. Einige Radiostreams wieden mir angezeigt, dass sie mitgeschnitten würden. Falls nicht, blitzte - wenn überhaupt - für Sekundenbruchteile ein Fenster hoch. Was nicht geht, warum es nicht geht - das zu analysieren, ist bei dieser Verfahrensweise aussichstlos. Was für ein Frust! Und all die Jahre, die Streamtuner und Streamripper existieren, gab es keine tatsächlich schlaue Lösung in der Doku?
Aber: hey, ich kann ja die Record Taste nach Audio-Typ in der Konfiguration belegen, wie ich will! Dann schreiben wir doch ein Skript, auf dass man sehen kann, was da passiert - und wenn nicht, wieso denn nicht.
Schritt 1
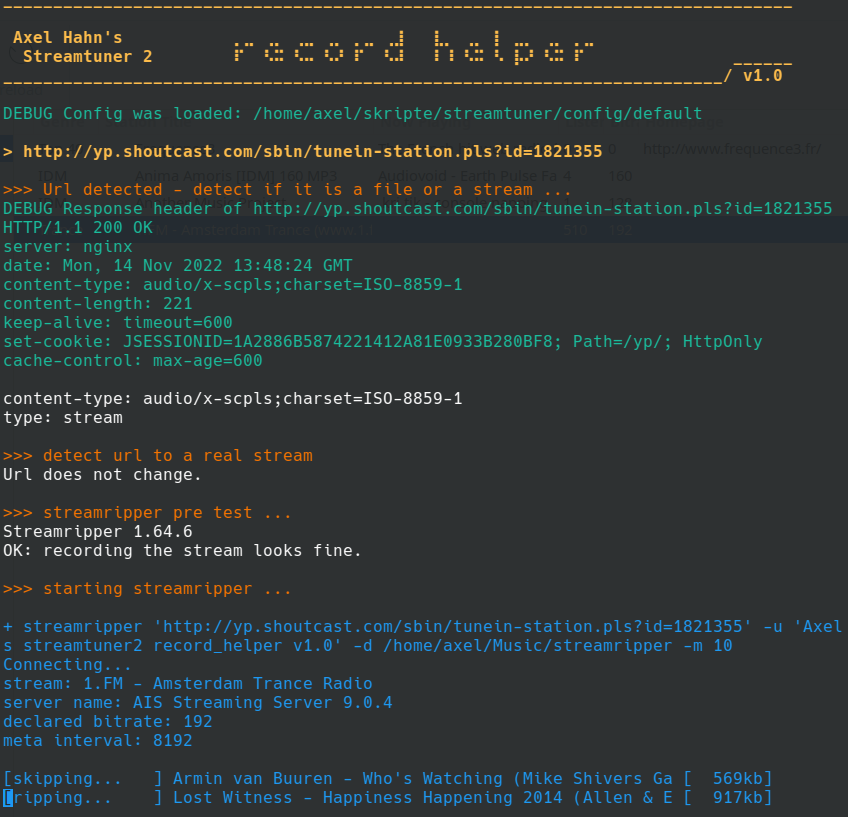
Gesagt - getan: ein Skript zeigt die übergebene URL an und was der Streamripper tut - oder aber bei Abbruch allenfalls an Fehlermeldung zurückwirft. Das Skript ist dann nicht einfach fertig - sondern wartet noch eine vordefinierte Zeit. Das war schön und ein Segen, das endlich einmal tatsächlich sehen zu können, an welcher Stelle und bei welchem Typ Url oder MIME Type er die Segel streicht.
Schritt 2
Manche Muster erkennt man: Streamripper kann bei bestimmten Playlist-URLs diese nicht parsen - er braucht dann hier eine Direkt-URL eines Streams, die man aber aus der Playlist ziehen könnte.
Oder es gibt Plugins, die einen Download eines Files anbieten - also gar keine Radiostreams sind, z.B Jamendo und MODarchive. Und beide benötigen unterschiedliche Handhabungsweisen, was bei einem Download zur Benamung der Zieldatei passieren muss.
Oh, es wird ja kompliziert - gut, wenn man noch nen Tick besser skripten kann.
Schritt 3
Wir bauen mal mehr Logik ein. Und Debugging Ausgabe, wie den Http Response Header.
Mein Downloader-Skript bekommt also eine URL. Es muss feststellen, ob es eine Datei oder eine Streaming URL ist. Dazu prüfen wir mal die URL, ob sie Weiterleitungen besitzt. Das letzte “Location:” im Http-Header bei aktiviertem Follow-Redirects ist meine finale URL zum Analysieren.
Jene Url ist entweder ein Stream oder eine Datei. Wenn es eine Datei ist, dann könnte es entweder eine Playlist sein, aus der man eine Streaming URL beziehen muss - oder eine Datei zum Download.
Seine Streaming Url oder ggf. aus der Playlist extrahierte Streaming URL wird an den Streamripper übergeben.
Ein Download File wird hingegen mit Curl heruntergeladen und je nach Typ wird eine Zieldatei geschrieben.
Ich glaube, mit einer solchen Ausgabeform kann man mit der Aufnahmefunktion und etwaigen bereits etwas mehr anfangen:
UPDTAES:
2022-11-14 - the helper script reached version 1.0 now.
weiterführende Links:
- Gihub: axelhahn st2_record_helper
- Streamtuner 2 internet radio directory browser
- Streamripper record streams as mp3 to your hard drive
- Mitteilung auf Fosstodon
Sa, 15. Oktober, 2022
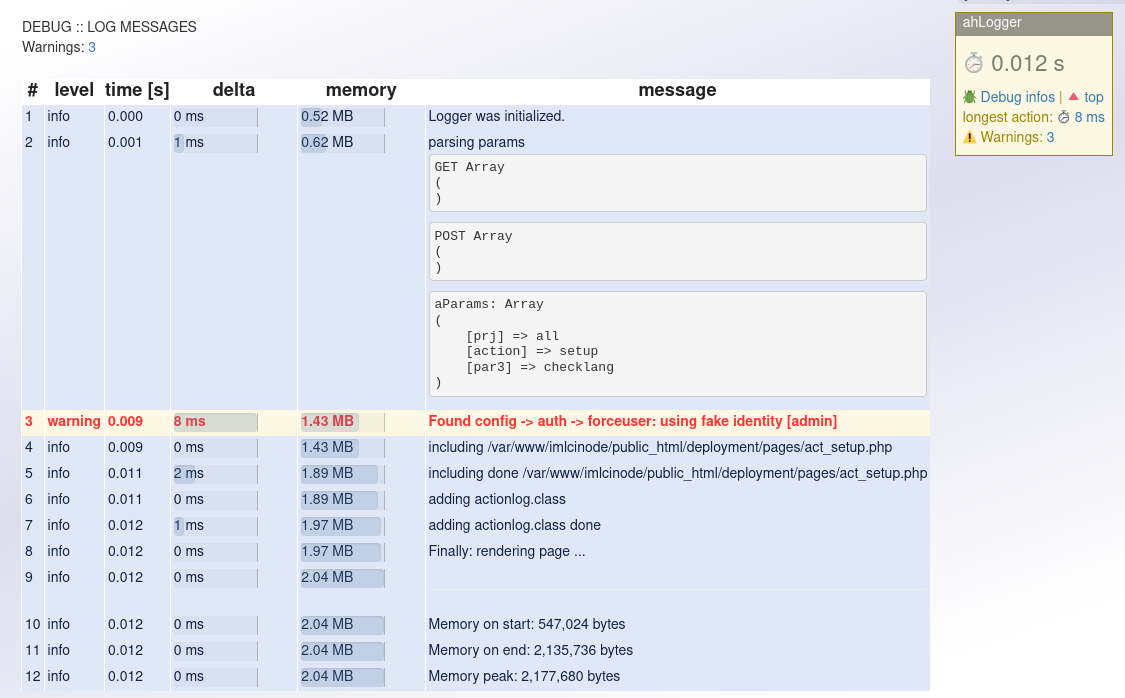
Ich habe mal diese Loggerklasse geschrieben, um in einer PHP-Anwendung Dinge während eines Client-Requests zu debuggen. Ich zeichne Meldungen auf, die mit einem Status (OK, Info, Warnung oder Fehler) versehen werden. Auch kann man übergabe-Parameter und sonstige Variablen dort reinblasen.
Eine Rendering Funktion zeichnet eine Tabelle mit allen Meldungen ans untere Ende der Webseite. Alles kein Hexenwerk.
Wenn man schon Meldungen einsammelt, dann wird auch ein Zeitstempel getrackt. Und wenn man Zeitstempel hat, dann kann man die Zeitdauer von einzelnen Aktionen messen und tracken: wie lange läuft eine Datenbank-Abfrage, ein Exec oder eine andere Aktion - das bekommt man gratis dazu: in einer Spalte der Ausgabetabelle wird das Delta zur letzten aufgezeichneten Meldung ausgegeben.
Ein Div rechts oben zeigt die Verarbeitunsdauer des Requests am Server an und kennzeichnet farblich, ob es eine Warnung oder einen Fehler gab. Man kann von hier auch direkt zu den Einträgen mit Warnung oder Fehler springen.
Mit überschaubarem Aufwand entstand ein hilfreiches Werkzeug zum Debuggen, Messen und Bottlenecks finden.
So wird es gemacht:
Nach dem Initialisieren wird mt der Methode add() beliebig oft je eine Meldung erfasst.
$oLog = new logger();
// Beispiel 1: hilfreiche Daten sichtbar machen
$oLog->add(”INFO: all GET params: <pre>” . print_r($_GET,1) . ”</pre>”);
$oLog->add(”INFO: all POST params: <pre>” . print_r($_POST,1) . ”</pre>”);
// Beispiel 2: Zeiten messen geht implizit - durch Schreiben einer neuen Logmeldung
$oLog->add(”start db request”);
$sSql=’select id, label, description from mytable;’;
// … make your query
$oLog->add(”sql query finished: ” . $sSql);
Eine render() Methode gibt am Ende das Ergebnis aus.
// die Ausgabe … aber natürlich nicht für jeden Seitenbesucher
if ($bDebugIsEnabled){
echo $oLog->render();
}
Was ist neu?
- Wenn ich bereits Zeiten mitschreibe, ist das Auslesen des Speicherverbrauchs fast ein Nobrainer. So sieht man, wo wärend der Aktionen eines Seitenaufrufs der Speicherverbrauch wie wächst.
- Balken visualisiern nun den Speichrverbrauch und die gemessenen Zeiten.
- Emoji Icons machen die Ausgabe etwas locker.
So sieht es aus:
weiterführende Links:
- Docs: ahLogger
- Github: Sourccode
Do, 13. Oktober, 2022
Nachdem vor 2 Wochen das Prune und Verify separat ausführbar und konfigurierbar wurden, gibt es nun ein weiteres Feature: Hooks.
Das Backup läuft wie folgt ab
- Initialisierung
- Start der Backups der lokalen Datenbanken (z.B. Mysql, Sqlite)
- Backup der definierten lokalen Verzeichnisse
- Prune (Ausdünnen und Löschen alter Backup-Daten)
- Verify
Die Hooks dienen zum Starten von eigenen Skripten … vor dem Start des Backups und danach sowie auch an mehreren Punkten während des Backups.
Es gibt initial diese Verzeichnisse, die du Skripte ablegen kannst, um sie zu definierten Zeitpunkten zu starten:
> tree -d hooks/
hooks/
|– 10-before-backup
| `– always
|– 12-before-db-service
| `– always
|– 14-before-db-dump (UNUSED)
| `– always
|– 16-after-db-dump (UNUSED)
| |– always
| |– on-error
| `– on-ok
|– 18-after-db-service
| |– always
| |– on-error
| `– on-ok
|– 20-before-transfer
| `– always
|– 22-before-folder-transfer
| `– always
|– 24-after-folder-transfer
| |– always
| |– on-error
| `– on-ok
|– 26-after-prune
| |– always
| |– on-error
| `– on-ok
|– 28-after-verify
| |– always
| |– on-error
| `– on-ok
`– 30-post-backup
|– always
|– on-error
`– on-ok
34 directories
Als am ehesten einleuchtende Beispiele:
- Vor dem Start des Backups kann man Sachen lokal synchronisieren, die ebenfalls ins Backup einfliessen sollen.
- Nach dem Backup kann man beispielsweise Notifikationen ins Monitoring oder per E-mail auslösen.
Bei “nach einer Aktion” zu startenden Hooks kann man jeweils getrennte Sets von Skripten starten, sobald eine Aktion OK war … oder aber fehlerhaft … oder aber auch immer (unabhängig vom Status).
Und wie ist es implementiert? Schauen wir mal auf die Bash-Interna.
Es gibt zu den definierten Zeitpunkten im Skript einen Aufruf einer Hook-Funktion - mit dem Hook-Verzeichnis als Namen als Parameter 1 und für “nach einer Aktion” zu startende Hooks den Exitcode als optionalen 2. Parameter. Als willkürliches Beispiel:
_j_runHooks ”24-after-folder-transfer” ”$myrc”
Die Hookfunktion ruft bei Exitcode 0 die Skripte im “on-ok” Untrverzeichnis - und bei Exitcode > 0 jene vom “on-error”. Anschliessend (oder bei Aufruf ohne einen Exitcode) werden vom jeweiligen Hook die Skripte im Unterverzeichnis “always” verarbeitet.
Die Ausführung der Skripte erfolgt in alphabetischer Reihenfolge - mit der Benamung kann man also die Abfolge der Abarbeitung mehrerer Skripte beeinflussen.
Die Hookfunktion sieht so aus (genaugenommen erschreckend einfach):
…
# ————————————————————
# execute hook skripts in a given directory in alphabetic order
# param string name of hook directory
# param string optional: integer of existcode or ”" for non-on-result hook
# ————————————————————
function _j_runHooks(){
local _hookbase=”$1”
local _exitcode=”$2”
local _hookdir=”$( dirname $0 )/hooks/$_hookbase”
if [ -z ”$_exitcode” ]; then
_hookdir=”$_hookdir/always”
elif [ ”$_exitcode” = ”0” ]; then
_hookdir=”$_hookdir/on-ok”
else
_hookdir=”$_hookdir/on-error”
fi
for hookscript in $( ls -1a ”$_hookdir” | grep -v ”^.” | sort )
do
if [ -x ”$_hookdir/$hookscript” ]; then
h3 ”HOOK: start $_hookdir/$hookscript …”
$_hookdir/$hookscript
else
h3 ”HOOK: SKIP $_hookdir/$hookscript (not executable) …”
fi
done
# if an exitcode was given as param then run hooks without exitcode
# (in subdir ”always”)
if [ -n ”$_exitcode” ]; then
_j_runHooks ”$_hookbase”
fi
echo
}
…
weiterführende Links:
- IML OS Docs - IML Backup: Hooks (en)
- IML OS Docs - IML Backup: Startseite (en)
Mo, 10. Oktober, 2022
Ich spiele immer fleissig Updates ein.
Plötzlich überraschen mich meine Shellskripte mit der Ausgabe
grep: warning: stray before white space
Die Ursache ist schnell gefunden … eine neue Grep Version 3.8 ist aufgespielt worden, die sich offensichtlich anders verhält.
> grep –version
grep (GNU grep) 3.8
Copyright (C) 2022 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <https://gnu.org/licenses/gpl.html>.
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Written by Mike Haertel and others; see
<https://git.sv.gnu.org/cgit/grep.git/tree/AUTHORS>.
Ich hielt es bisher immer so: Sonderzeichen MUSS man im Regex maskieren … und beliebige normale Zeichen KANN man immer mit Backslash maskieren und es schadet auch nicht. Letzteres ist nun offensichtlich anders.
> echo ” OK” | grep ”\ \ ”
grep: warning: stray before white space
grep: warning: stray before white space
OK
Zur Abschaltung der Warnung entferne ich im Regex den einem Space vorangestellte Backslash:
> echo ” OK” | grep ” ”
OK
Yep.
Soweit so gut … alles gut … dachte ich.
Es kamen in anderen Skripten aber auch Meldungen der Art
grep: warning: stray before -
Also die Suche nach einem Minus muss nun auch nicht mehr mit Backslash maskiert werden? Einmal schnell testen:
> echo ”——” | grep ”\-\-\-”
grep: warning: stray before -
grep: warning: stray before -
——
Backslash weggenommen, hagelt ebenfalls eine Fehlermeldung:
> echo ”——” | grep ”—”
grep: unrecognized option ’—’
Usage: grep [OPTION]… PATTERNS [FILE]…
Try ’grep –help’ for more information.
Leider nein.
Die Lösung hier: Nun braucht es als Option ein Doppel-Minus. Und im Regex darf man das Minus nicht maskieren. Also so:
> echo ”——” | grep – ”—”
——
Ich fürchte, die neue grep Version wird mich noch in anderen Skripten ärgern.
Di, 27. September, 2022
Es ist gar nicht so lange her, dass ich 20 Jahre Cronwrapper vermeldet habe [1].
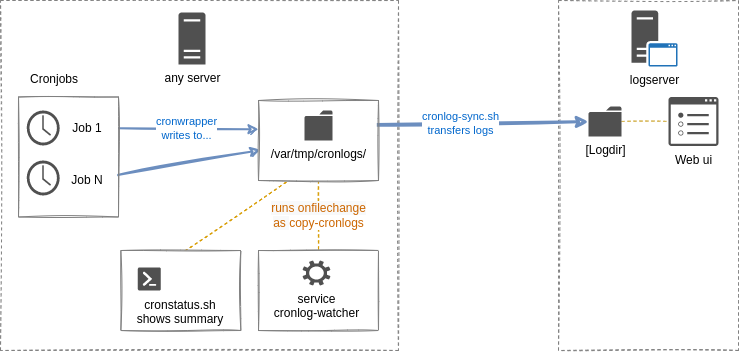
Der Cronwrapper vereinfacht die Handhabe, Logging und Überwachung von Cronjobs [2]. OK, er ist von mir geschrieben, aber ich mag irgendwie, was er wie tut - schon dass man Ausgabe schreiben kann, wie man will, sich nicht um Ausgabe-Umlenkung und Loggin kümmern muss. Die Asugabe ist normiert, dass man mit grep schnell zu Details, wie Laufzeit oder Exitcode kommt. Ein mitgeliefertes cronstatus.sh liefert basierend darauf pfannenfertig den Zustand aller lokal laufenden Cronjobs. Aber wer will sich denn dafür auf jeden Server einloggen? Ich hätte da lieber eine zentrale Cronjob-Zentrale.
Wir haben an unserem Institut 200+ Server. Die meisten haben einen Cronjob … oder mehrere. Bisher hatte ich einen Hilfs-Cronjob am Laufen, der alle 5 min ein rsync zu einem Logserver machte. Aber alle paar Minuten immer wieder nur dumm rsync starten, ist auch nicht gerade so toll.
Daher wurde das Sync-Skript [3] erweitert: er startet nur dann rsync, wenn tatsächlich ein neueres Logfile nach dem letzten Sync vorliegt. Das ist selten einfach zu implementieren: nach dem Rsync toucht man eine Datei im Logverzeichnis. Beim nächsten Aufruf ein ls -ltr und man schaut, ob die neueste Datei noch immer das Touchfile ist. Das würde die Zahl der rsyncs deutlich reduzieren, wenn es nur stündlich oder tägliche Cronjobs gibt.
Was ist noch besser? Nur dann synchen, wenn tatsächlich ein Cronjob gelaufen ist. Der Pferdefus ist: ich habe Jobs mit unsterschiedlichen Usern am Laufen. Ein Skript des Cronjobs unter einem x-beliebigen User laufend kann nicht selbst zum Abschluss das rsync auslösen.
Aber ich habe schonmal für ähnlichgelagerte Zwecke ein Skript onfilechange geschrieben [4], das bei Modifikation eines Fileobjekts ein Kommando startet. Initial entstand es, damit Vorgänge mit unprivilegierten Benutzer (mit SSH Zugang oder auch anderweitig) auf einem Applikationsserver den Webservice restarten zu können, was eben nur als root geht. Das Skript selbst loopt zwar ewig, aber man kann es recht einfach in ein Systemd Configfile verpacken, damit es als Systemd Prozess handhabbar ist [5]. Also: man kann es per systemctl starten/ stoppen oder mit jounrnalctl -u [Name] im Systemlog dessen Aktionen begutachten.
Für unsere Logs des Cronwrappers läuft ebenjenes onfilechange Skript in einem solechen systemd Service mit dem User, der berechtigt ist, zu einem Logserver per SSH zu verbinden. Es überwacht das Logverzeichnis des Cronwrappers und startet bei Änderung das Sync-Skript.
Zielserver und Zielverzeichnis liegen in einer Configdatei, die sich mit Ansible, Puppet und Co einfach generieren lässt.
Es gibt pro Server ein eigenes Zielverzeichnis - es enthält dabei den FQDN des jeweiligen Systems.
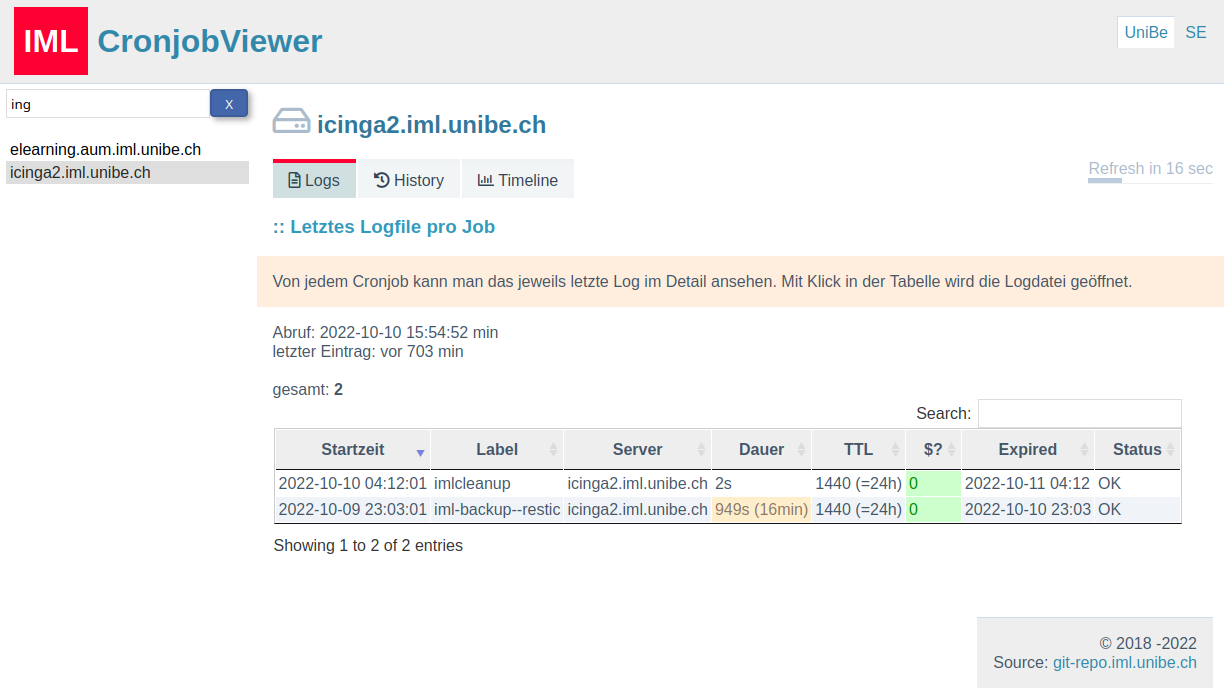
Last but not least: Auf einem Logserver ein grosses Logverzeichnis vieler Server … wie ist nun das zu handhaben? Dazu ist vor ein paar Jahren auch ein Webinterface mit PHP entstanden, das über alle Server und Jobs durch deren Logs browsen lässt: der Cronlog Viewer [6].
weiterführende Links:
- Blog: 20 Jahre Axels Cronwrapper (en)
- Cronwrapper Docs: Start (en)
- Cronwrapper Docs: Cronlog-Sync (en)
- onfilechange Docs: Start (en)
- onfilechange Docs: Systemd] (en)
- Git-Repo: Cronlog Viewer
Di, 30. August, 2022
Der IML CI Server ist ein seit 2015 produktives Werkzeug, mit dem bei uns am Institut gut 50 Projekte ausgerollt werden. Bediente Programmiersprachen für unsere Projekte sind PHP, NodeJs und Ruby - aber eine Zielsprache ist nicht limitiert. Der CI Server erzwingt den Workflow der Installations-Reihenfolge über Preview -> Stage -> Live.
Einschub:
F: Warum beschreibe ich das hier auf einer privaten Webseite?
A: Opensource wird an unserem Institut in einem Ausmass genutzt, dass ohne Opensource Produkte bei unserem Betrieb so ziemlich nichts ginge. Aber auch hauseigene Opensource-Projekte werden auf unserer offiziellen Seite ferngehalten. Begriffe, wie “Opensource” oder “GPL” sind genauso inexistent, wie “mein” hier beschriebener CI Server in der Rubrik Software-Entwicklung.
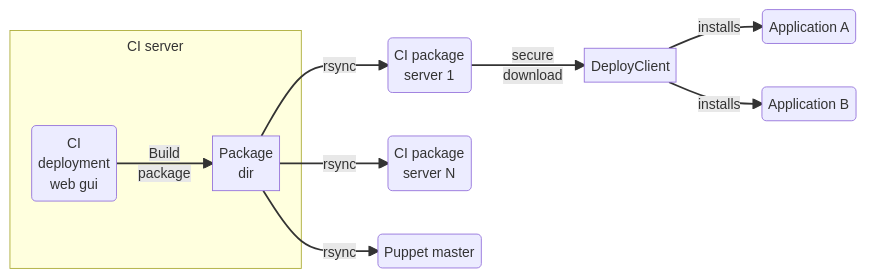
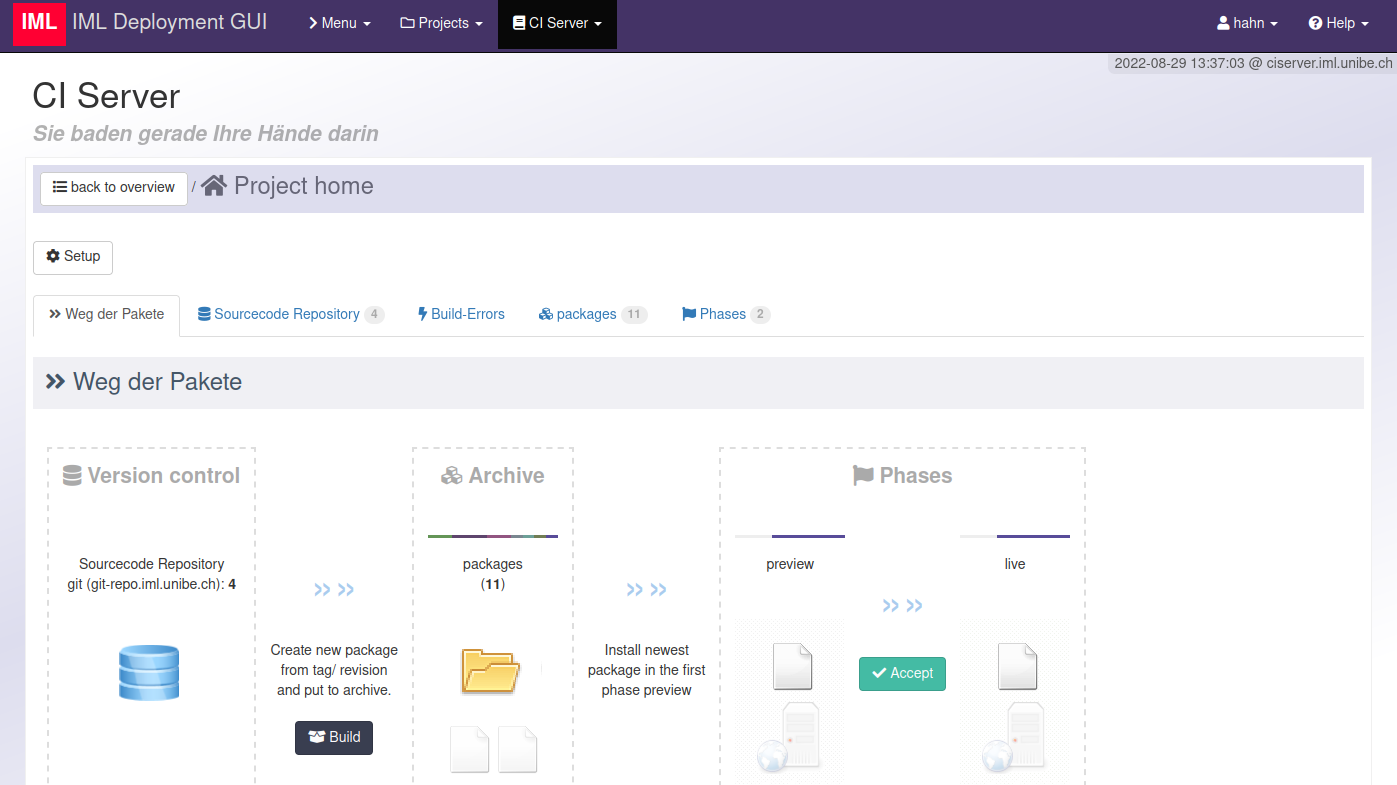
Wie das Rollout im Groben funktioniert:
Build
- Mit einem Git clone wird der Sourcecode des Projektes in ein temporäres Build-Verzeichnis geholt.
- Das Projekt kann mit einem definierten Hook-Skript Aktionen triggern, um Module nachzuladen, etwas compilieren, Javascript+CSS minimieren … was auch immer
- Was dann noch im Build-Verzeichnis überbleibt, wird zu einem Archiv zusammengepackt und eine Metainfo-Datei angelegt.
- Der CI Server kann die Installation triggern. Mitgeliefert werden 2 Plugins für einen SSH-Aufruf und Ansible AWX. Damit etwaige Tools die Installation starten können - und ohne Zugriff auf den CI-Server im internen Netz haben zu müssen, kann man das Paket per Rsync zu mehreren Zielsystemen syncen, z.B. zu einem Puppet Master oder einem abgesicherten Software-Download-Server (das ist ein seperates Open Source-Projekt).
Installation auf der ersten Phase (Preview)
- Das Paket wartet in der Queue im Modus “zur Installation bereit”. Die Queue besitzt eine zeitliche Freigabe. Man kann erzwingen, dass eine Installation beipielsweise nur von Montag bis Donnerstag im Zeitfenster 14:00-15:00 Uhr erfolgen darf.
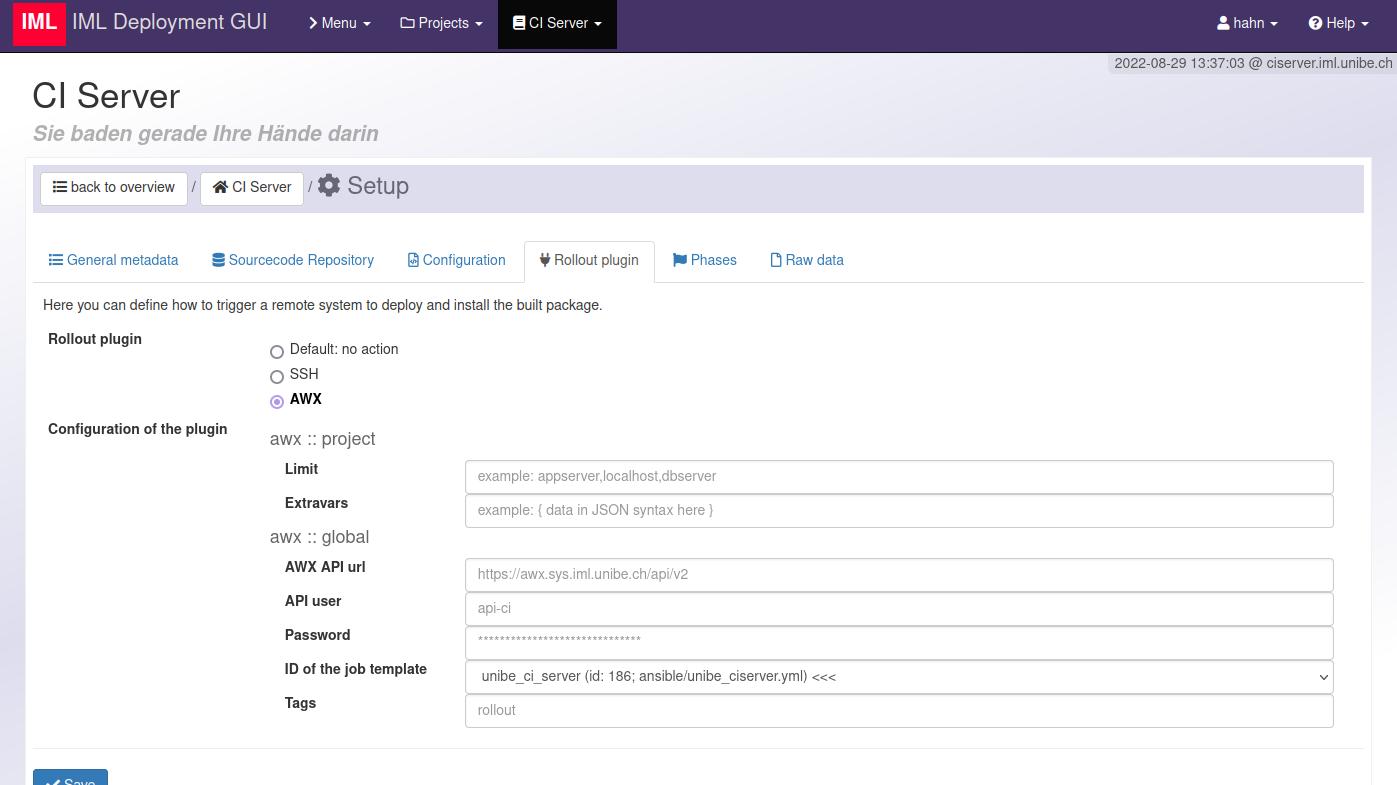
- Im Projekt-spezifischen Setup ist festgelegt, ob das Rollout per SSH oder AWX mit entsprechender Parametrisierung erfolgt … und auch welche Zielsysteme existieren. Das AWX Rollout-Plugin holt sich per API die Templates, Inventories und Playbooks vom AWX Server, die in den Prohjekteinstellungen als Dropdown zur Auswahl stehen. Nach einem Build wird das Rollout-Plugin auf die erste Projekt-Phase angewendet, um das Projekt zu installieren.
- Die Implementierung der Installation ist keine Komponente des CI Servers. Es gibt aber eine Bash-Implementierung für ein Installations-Werkzeug (ebenfalls ein separates Opensource Projekt).
- Unsere Installation umfasst … (sicherer) Download des Software Archivs … Entpacken dessen … Start eines Hook-Skripts zur Installation und anderen Aktionen (Cleanup des Cache, Restart von Services) … Generieren von systemspezifischen Konfigurationsdateien mittels Templates
- Feedback an den CI Server, damit dieser weiss, wie weit das Paket ausgerollt wurde.
Rollout auf Stage und Live
Rein technisch ist das identisch mit dem, was zur Installation auf Preview gesagt wurde.
Damit ein Paket von einer zur nächsten Phase freigegeben werden kann, bedingt es die Interaktion - den Klick eines [Accept] Buttons plus Bestätigung, dass man die Featrues und Software-Zustand für OK befunden hat.
Zum Update auf PHP 8.1 habe ich für eine Entwicklungsumgebung mit rootless Docker die benötigte Konfiguration aufgebaut - diese ist im Repository im Unterverzeichnis “docker” enthalten (zuvor habe ich mit einer lokalen Virtualbox-Instanz entwickelt). Das wird Weiterentwicklungen vereinfachen.
Das Update beinhaltet rein die Portierung auf ein aktuelles PHP 8.1 um es auf einem Server mit aktuellesten OS zum Laufen zu bringen. Andere Komponenten, wie Bootstrap 3 sind gnadenlos veraltet und dürfen wohl in naher Zukunft aktualisiert werden.
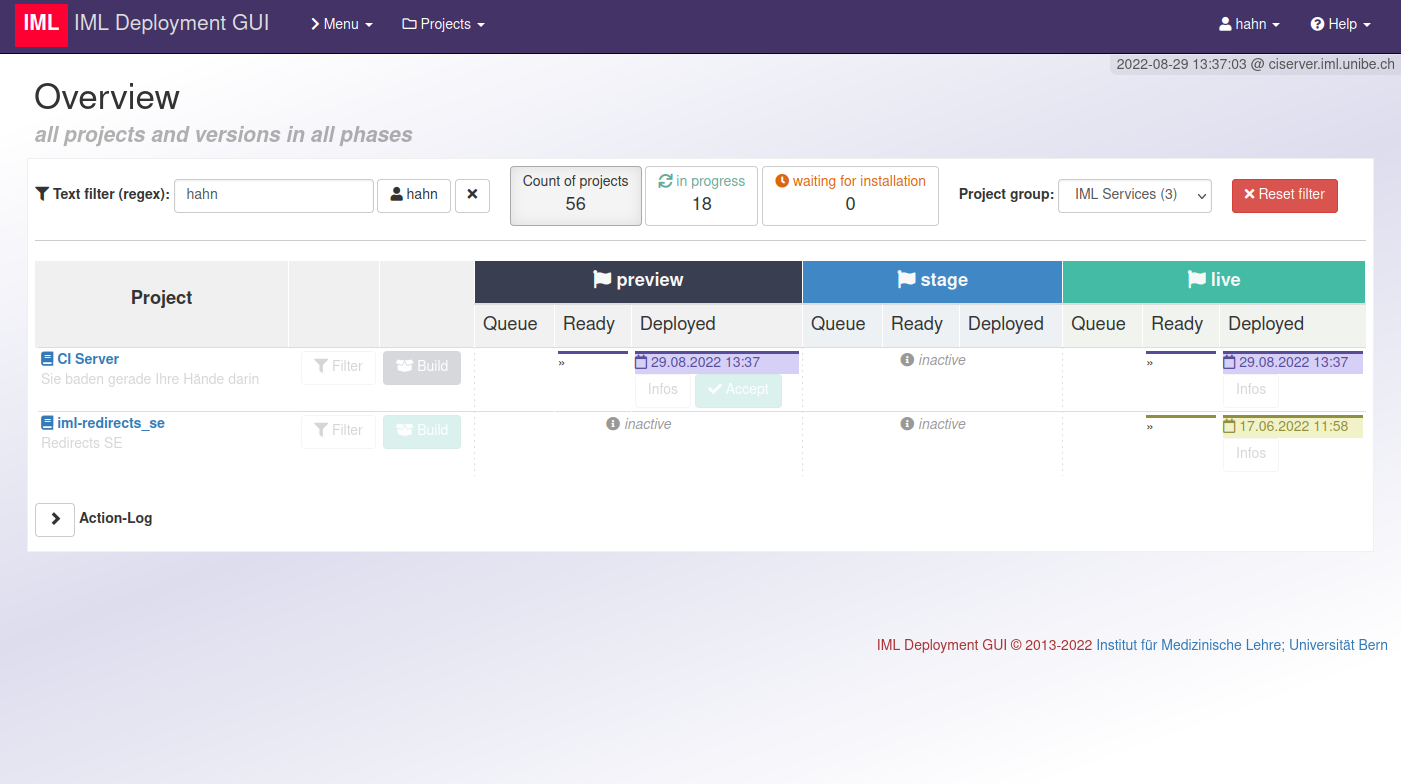
Screenshots
In der Übersichtsseite aller Projekte kann man filtern, um die Ansicht zum Auffinden “seines” Projektes zu reduzieren.
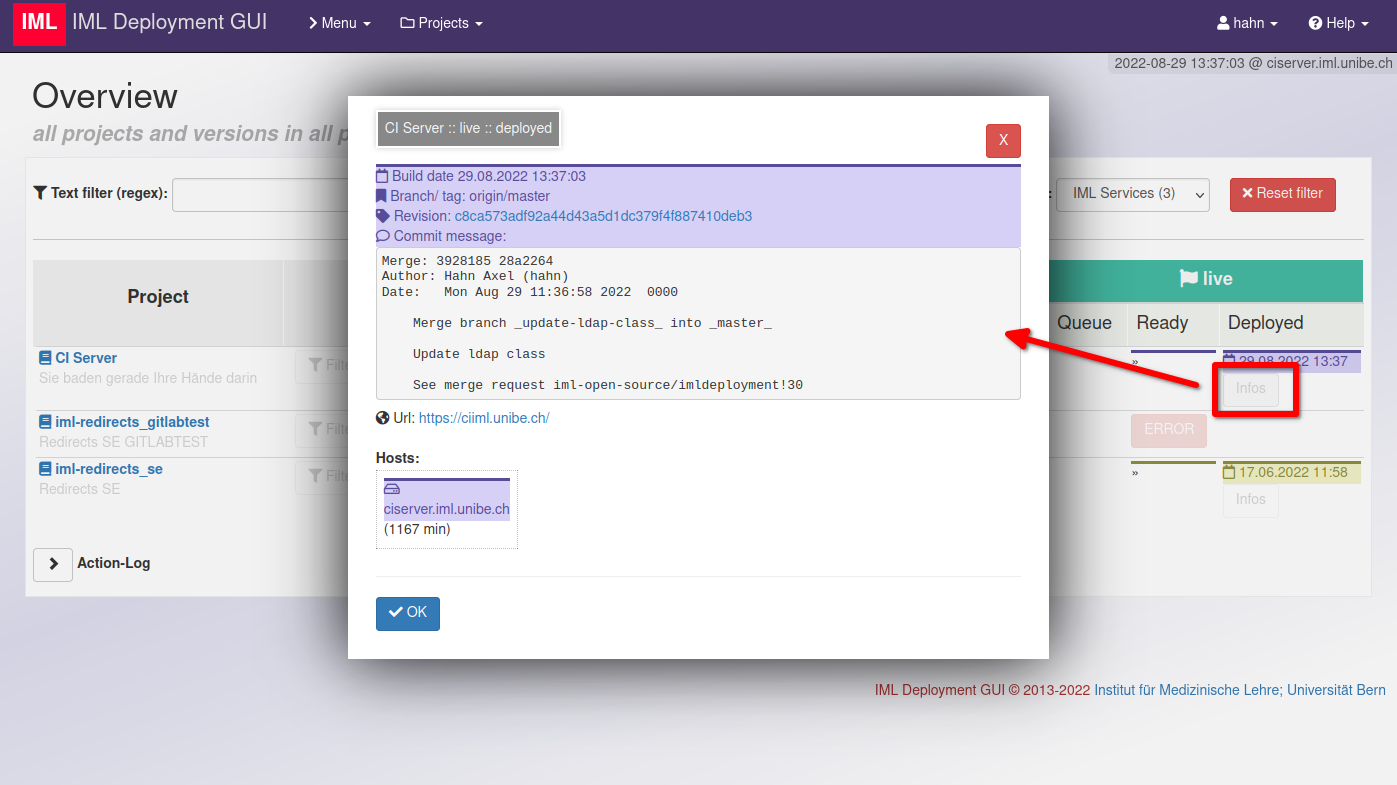
Ein neuer Build erhält basierend auf dem Hash der Commit ID einen Farbcode. Damit lässt sich optisch darstellen, wie weit ein neuer Build bereits ausgerollt ist. In jeder Phase gibt es [Info] Buttons, die einem Details im Popup aufzeigen.
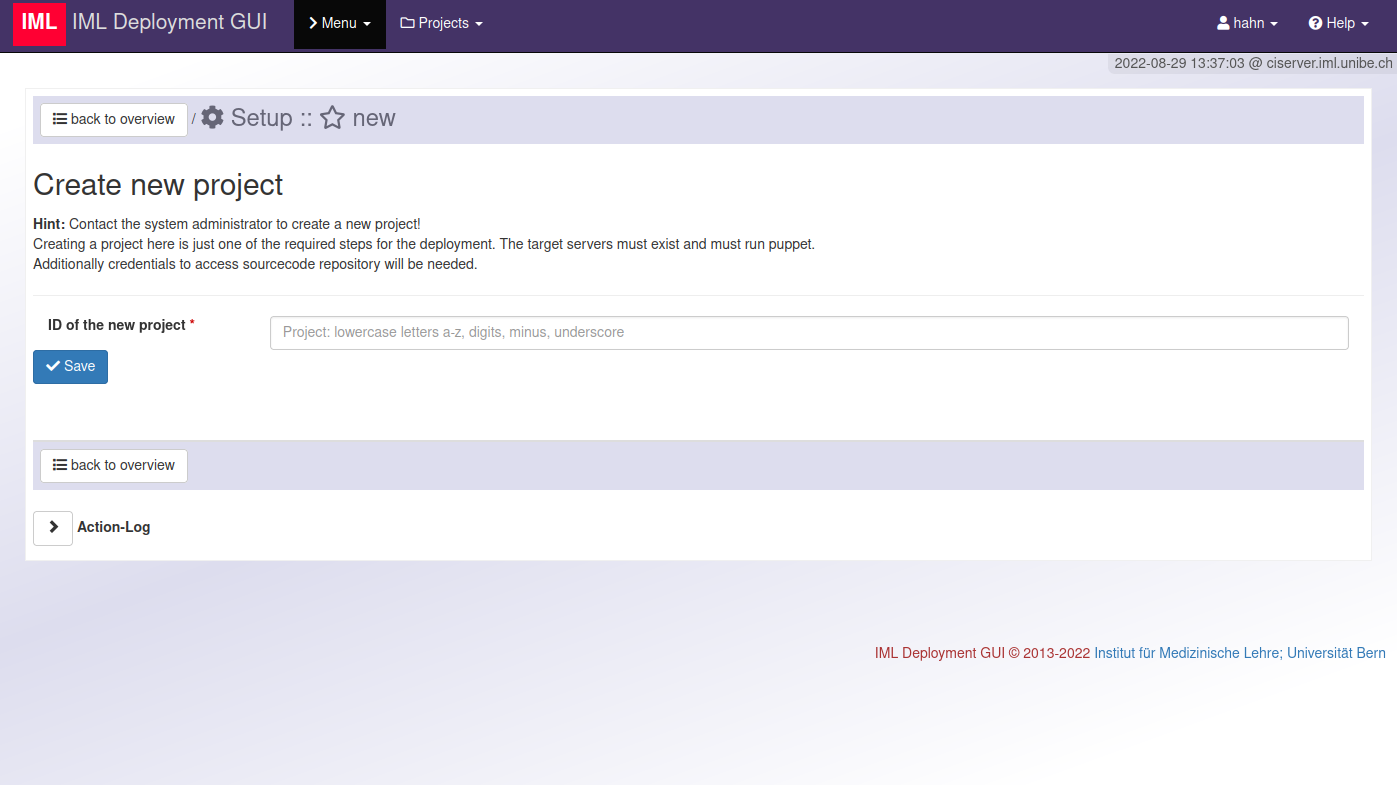
Erstellen eines neuen Projektes.
Wahlt man ein Projekt, sieht man zunächst eine Seite mit Repo, Archiv (der Builds) und die Phasen des Projekts
In den Projekt-Einstellungen .. Tab Rollout: hier das AWX-Plugin mit den allg. Voreinstellungen. Jedes einzelne Feld lässt sich in jeder der Phasen äbernehmen oder aber nochmals übersteuern.
weiterführende Links:
- Repo: IML CI Server (Opensource; GPL 3.0)
- Docs: IML CI Server auf os-docs.iml.unibe.ch (WIP)
- Repo: IML CI Paket Server (Opensource; GPL 3.0) - Software-Archiv für ein öffentlich zugängliches System, welches nur sichere Downloads mit one time Tokens zulässt
- Docs: IML CI Paket Server auf os-docs.iml.unibe.ch
- Repo: IML CI Deployment Client (Opensource; GPL 3.0) - Bash-Skript zur Installation via IML CI Paket Server, Ondeploy-Hook, Generierung von Konfigurationen aus Templates
- Docs: IML CI Deployment Client auf os-docs.iml.unibe.ch
Fr, 19. August, 2022
Unter https://www.axel-hahn.de/docs/[POJEKT] habe ich diverse Hilfen für PHP- und Javascript Tools bereitgestellt, die ich mit einem Parser generieren lasse. Jener Ansatz ist etwas älter und länger her - und stellt bereits geraume Zeit so einige meiner Dokumentationen bereit…
Eigentlich suchte ich nach einem mehr generischen Ansatz, um heutzutage in Git übliche Markdown-Dateien in statisches HTML umzuwandeln. Es gibt da diverse Tools, aber ich bin beim PHP-CLI Tool Daux hängengeblieben. Insbesondere, weil ich hier im Gegensatz zu anderen angetesten Werkzeugen keine Extra Konfiguration für einen Navigationsbaum als Config-Datei hinterlegen muss. Auch hat der Entwickler sehr schnell reagiert und auf gemeldete Feature Requests reagiert. Kurz: ich habe nun diverse einzelne Dokumentationen verschiedener Produkte und Klassen mit Daux gebaut. Das sind jeweils statische Verzeichnisse mit statischen HTML-Dateien + Javascript und Css out of the Box in jedem Browser laufen, wenn man sie vom Filesystem oder aber USB-Stick startet.
Was diverse Markdown zu Html Generatoren bieten, ist ein eingebauer Webserver für eine Vorschau. Der hilft beim Schreiben der Markdown-Dateien. Mittlerweile in Markdown Quasi-Standard ist der Support von mathematischen Formeln oder aber Graphen (mermaid.js) - das soweit ich auf Github, Gitlab oder aber lokal im Visual Studio Code per Markdown Preview gesehen habe.
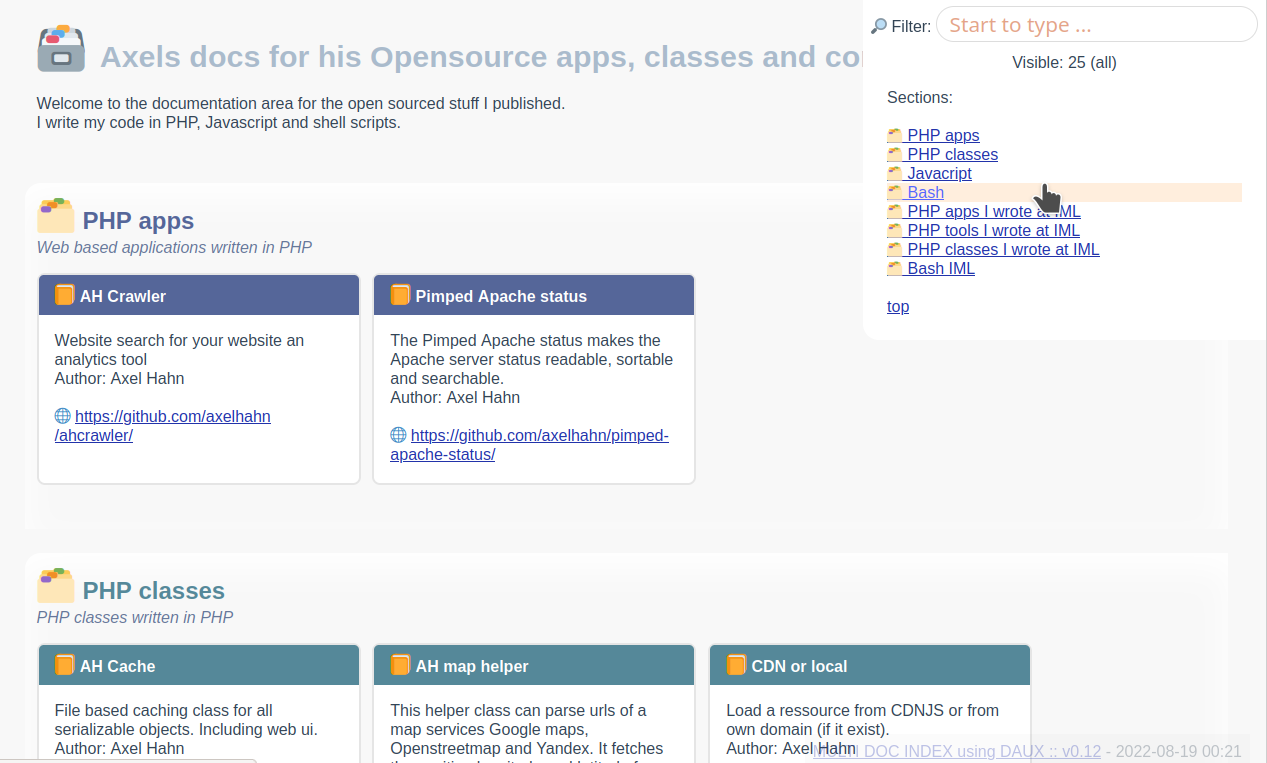
Soweit so gut. Und wenn ich nun zig alleinstehende Dokumentationen habe und eine Index-Seite haben will?
Ich habe dazu einen Ansatz zum Generieren einer Index-Seite wie folgt gewählt:
- ich möchte Gruppen: nach Programmiersprache oder nach einer sonstigen Rubrik
- in jeder Rubrik werden N Projekt-Dokumenationen verlinkt
- … wobei jene referenziert wird als Git-Repository, um diese mit Daux on the fly generieren zu lassen
- … oder aber: weil ich noch meine geparsten Dokumentationen habe: ich kann anderweitig bestehende Dokumentationen ebenfalls einbetten
- die Index-Seite soll flexibel sein und verschiedene Templates/ CSS/ Javascritpt unterstützen
Ich habe dazu ein Bash-Skript geschrieben, das mit jq eine JSON Config-Datei parst und mittels eines Templates die Seitenelemente generieren lässt. Die Flexibilität steckt in den Templates - dese bestimmen, ob es ein
OK, all das ist zu viel Text … so sieht meine Übersichtsseite mit dem Template mit Gruppen und Boxen sieht so aus: Axels Docs
weiterführende Links: (en)
- Axels Docs-Index-Seite
- daux.io Hilfe-generator - Markdown zu HTML
- Github: axelhahn/multidoc-generator
- Statische Hilfe zum multidoc-generator
- Mermaid.js
Mo, 27. Juni, 2022
Mein Theme des Flatpress-Blog hat vor ein paar Wochen ein Update erhalten und wurde responsive. OK, das war auch überfällig, dass man auf Smartphone und Tablets ebenfalls Blog Texte lesen kann. Es gibt 3 Zoomstufen mit unterschiedlichen Rahmenbreiten.
Bei kleinen Auflösungen werden linke/ rechte Spalte mit Klick auf ein Hamburger-Menü eingeblendet.
Nun kam noch ebenjenes im Screenshot sichtbare Farbschema neu hinzu: den ganz farbenreichen Themes gesellt sich nun ein etwas einfacheres und mehrheitlich weisses. Ich hoffe es gefällt.
Zum Updaten in seiner Flatpress Instanz: im Ordner ./fp-interface/themes/ das Verzeichnis “atog” löschen und durch den im Github Repository ersetzen. In der Admin von Flatpress unter “Themes” kann man das Theme “A touch of glass” wählen und mit dem Link “Styles” die Farbwahl treffen.
weiterführende Links:
- Github: Projekt Seite des Themes
- Github: Theme A Touch Of Glass als ZIP
- Flatpress.org Blogging Engine in PHP ohne Datenbank
Mi, 13. April, 2022
Ich hatte bereits einmal einen ähnlichen Blog Eintrag geschrieben:
Bash: Ausführungszeit eines Kommandos in Millisekunden messen
Jene Methode basierte auf dem Parsing der Ausgabe des time Kommandos.
Nachfolgendes Beispiel-Snippet nimmt einen anderen Ansatz: Das Date-Kommando kann mit %N den Anteil der Nanosekunden zurückgeben. Man nimmt das date Kommando, um einen initialen Zeitstempel zu speichern. Zur Ausgabe der vergangenen Zeit liest man die Zeit erneut aus und berechnet die Differenz. Dazu könnte man bc hernehmen, aber das ist per Default auf einem Linux-Server vorinstalliert. Daher ist mal hier eine Variante mit awk:
export CW_timer_start
# Step 1
# start/ reset timer
# no parameter is required
function start_timer(){
CW_timer_start=$( date +%s.%N )
}
# Step 2 (as often you want)
# get time in sec and milliseconds since start
# no parameter is required
function show_timer(){
local timer_end=$( date +%s.%N )
local totaltime=$( awk ”BEGIN {print $timer_end - $CW_timer_start }” )
local sec_time=$( echo $totaltime | cut -f 1 -d ”.” )
test -z ”$sec_time” && sec_time=0
local ms_time=$( echo $totaltime | cut -f 2 -d ”.” | cut -c 1-3 )
echo ”$sec_time.$ms_time sec”
}
Die Funktion start_timer setzt den initialen Wert bzw. ein Reset.
Die Funktion show_timer zeigt die vergangene Zeit in Sekunden + Punkt + 3stellige Millisekunden an.
Ein Snippet zum Messen sieht grob etwa so aus:
# reset timer
start_timer
# hier irgendwas machen
# sei kreativ :-)
# Ausführungszeit:
echo ”verbrauchte Zeit: $( show_timer )”
Die Ausgabe ist dann soetwas, wie:
verbrauchte Zeit: 0.014 sec
Di, 22. März, 2022
Ich verwende diesen Aufruf, um Schemata auf dem Mysql Server zu dumpen:
mysqldump –opt
–default-character-set=utf8
–flush-logs
–single-transaction
–no-autocommit
–result-file=”$_dumpfile”
”$_dbname” 2>&1
$myrc=$?
… und stand vor dem Phänomen, dass der Exitcode 0 war - also eigentlich den Erfolg meldet - aber es keinerlei Daten im Dump gab.
Das Betriebssystem war ein Centos8 Stream. Das Problem lag in der Option –flush-logs, die nicht ausgeführt werden konnte, da das Verzeichnis /var/log/mysql/ (warum auch immer) nicht mehr vorhanden war. Dass ein leerer Dump ohne Daten erzeugt wird und kein Exitcode > 0, ist m.E. ein Fehler im mysqldump. Und den versuche ich, zu umschiffen.
Ich habe nach dem Dump noch einen Check hinzugefügt, der das Vorhandensein auf mind. ein CREATE oder aber INSERT Statements prüft. Oder anders: wenn man eine (korrekte) leere Datenbank ohne einzige Tabelle oder auch nur 1 einzigem gesicherten Datensatz hat, würde ein Fehler beim Backup gemeldet. Ich meine, damit lässt es sich leben.
mysqldump –opt
–default-character-set=utf8
–flush-logs
–single-transaction
–no-autocommit
–result-file=”$_dumpfile”
”$_dbname” 2>&1
$myrc=$?
if [ $myrc -eq 0 ]; then
if ! zgrep -iE ”(CREATE|INSERT)” ”$_dumpfile” >/dev/null
then
typeset -i local _iTables
_iTables=$( mysql –skip-column-names –batch -e ”use $_dbname; show tables ;” | wc -l )
if [ $_iTables -eq 0 ];
then
echo ”EMPTY DATABASE: $_dbname”
else
echo ”ERROR: no data - the dump doesn’t contain any CREATE or INSERT statement.”
# force an error
$myrc=1
fi
fi
fi
if [ $myrc -eq 0 ]; then
echo ”OK”
# Und dann hier noch komprimieren…
# gzip $_dumpfile”
# … und Erfolg der Kompression auswerten
else
echo ”ERROR: mysqldump failed.”
fi
Update:
- 24.03.2022 - eine leere Datenbank würde als Fehler gemeldet - daher zähle ich mal noch die Tabellen
weiterführende Links:
- mysql.com: mysqldump
- mariadb.com: mysqldump
- IML open source: IML-Backup (mein Backup Tool an unserem Institut zum lokalen Dumpen div. DBs und Backup mit Restic/ Duplicity)
- DOCs: os-docs.iml.unibe.ch/iml-backup/