Di, 23. Mai, 2023
Um Fontawesome von Version 5 auf 6 zu aktualisieren, gibt es einen Upgrade-Guide [1].
Aber das ist viel zu kompliziert :-)
nachdem ich einige Web-projekte umgestellt habe (das Intranet unseres Instituts, IML Appmonitor, ahCrawler, Pimped Apache Status) kann ich meinen Ansatz präsentieren:
- Man entferne das eingebundene CSS File von Fontawesome 5 und ersetze es durch das der Version 6, z.B.:
<link rel=”stylesheet” href=”https://cdnjs.cloudflare.com/ajax/libs/font-awesome/6.4.0/css/all.min.css” integrity=”sha512-iecdLmaskl7CVkqkXNQ/ZH/XLlvWZOJyj7Yy7tcenmpD1ypASozpmT/E0iPtmFIB46ZmdtAc9eNBvH0H/ZpiBw==” crossorigin=”anonymous” referrerpolicy=”no-referrer” />
- Die meisten Icons sollten nach wie vor da sein. Aber wir aktualisieren einmal die Schreibweise der CSS Klassen für die Version 6.
- im Projektordner Suchen und Ersetzen “fas fa” –> “fa-solid fa”
- im Projektordner Suchen und Ersetzen “far fa” –> “fa-regular fa”
Damit sind 98% erledigt. Nun sollte man die Webseite nochmal genau anschauen. Es kann sein, dass es noch das ein oder andere Prefix umzustellen gilt (z.B. für Brands). Oder aber es gibt auch einige (wenige) Icons, die nun anders heissen - wenngleich sich diese vielleicht nur schwer finden lassen - für diese muss man in [2] die neue Schreibweise ermitteln.
Viel Glück bei der Umstellung!
Weiterführende Links:
- Fontawesome.com: Upgrade (en)
- Fontawesome.com: frei verwendbare Icons durchsuchen (en)
Mo, 22. Mai, 2023
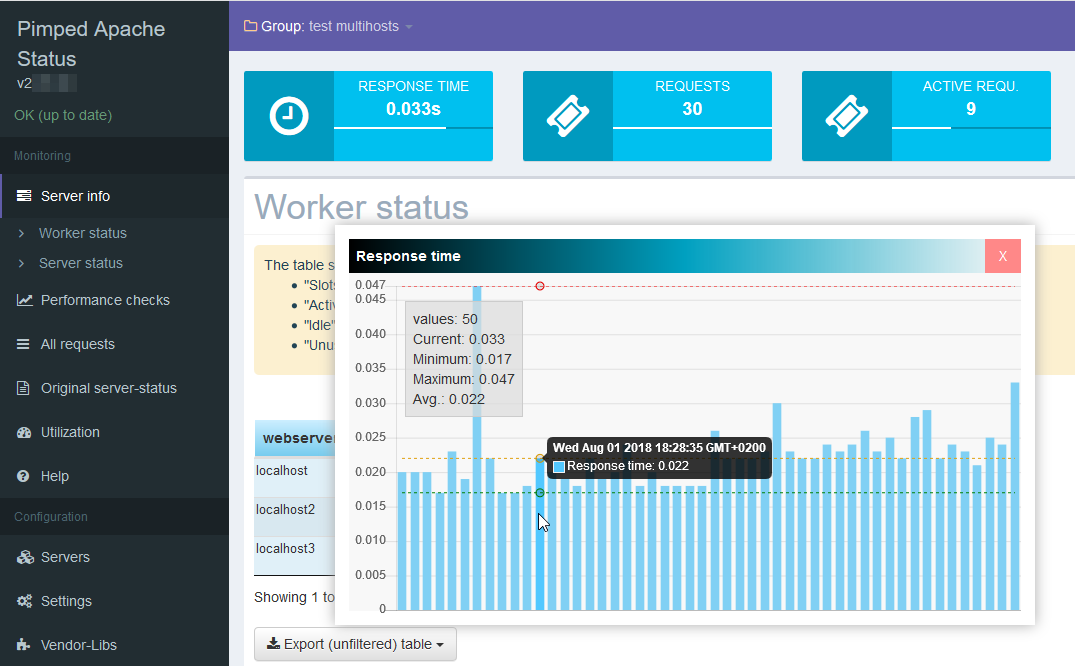
Der Pimped Apachestatus ist ein Webtool, dass die etwas schwer verdauliche Apache Serverstatus Page aufbereitet. Es gibt verschiedene Ansichten, sortier- und filterbare Tabellen und Graphen. Das ganze funktioniert nicht nur für einen einzelnen Server, sondern auch für mehrere Webhosts, z.B loadbalante Webeiten.
Am Wochenende gab es ein Update, in dem einige Vendor-Bibliotheken aktualisiert wurden.
Da die als kompatibel bestätigte Version 8.0 alsbald ausläuft, wurde es mit neueren PHP Versionen getestet. Es ist nunmehr PHP 8.2 kompatibel.
Zum Aktualisieren meldet sich der Updater. Bei Installationen mit git bitte git pull verwenden.
Weiterführende Links:
Mi, 10. Mai, 2023
Ich brauchte da auf die Schnelle mal was: ich wollte mehrere Systeme mit Ping antesten, ob sie im Netz sind.
Die Liste der zu testenden Systeme sollte untereinander stehen und pro System angeben; ich bin erreichbar … oder auch nicht.
Ja natürlich haben wir ein System-Monitoring, aber das ist etwas träge - ich wollte das Ganze alle wenige Sekunden aktualisieren. Im Rack wollte ich Kabel ziehen und umstecken - und nebenher sehen, welches Gerät offline geht und wieder da ist.
Hier mein Bash-Skript:
#!/bin/bash
cfgfile=”$0.cfg”
while true; do
clear
echo ”>>>>> PING TEST :: $( date )”
echo
cat ”$cfgfile” | grep ”^[a-z1-9]” | while read -r target
do
printf ”%-35s > ” $target
if ! ping -c1 $target 2>&1 | grep ”transmitted”; then
echo ”FAILED”
fi
done
sleep 1
done
Im Endlos-Loop wird der Bildschirm gelöscht, ein Header mit Datum ausgegeben. Ich lese eine Datei aus, die meine Liste von Geräten enthält.
Ein Gerät wird einmalig angepingt (Parameter -c 1) - genau das geht sehr schnell. Es wird ausgegeben, ob es erreichbar war oder nicht.
Nach Abarbeiten der Liste folgt ein sleep 1 - und nach dieser nur kurzen Wartezeit geht es von vorn los.
Die Configdatei mit der Liste der Server - je einer pro Zeile - Leerzeilen, Kommentare u.ä werden ignoriert:
#
# my server list
#
server-01.example.com
server-02.example.com
server-03.example.com
server-04.example.com
server-05.example.com
Das Ganze sieht in der Ausgabe am Terminal grob aus:
>>>>> PING TEST :: Mi 10 Mai 2023 16:37:41 CEST
server-01.example.com > 1 packets transmitted, 1 received, 0% packet loss, time 0ms
server-02.example.com > 1 packets transmitted, 1 received, 0% packet loss, time 0ms
server-03.example.com > 1 packets transmitted, 1 received, 0% packet loss, time 0ms
server-04.example.com > 1 packets transmitted, 1 received, 0% packet loss, time 0ms
server-05.example.com > FAILED
Das war ja ärgerlich: die Loginseite erschien nicht mehr. Ich hatte es nicht bemerkt, weil mein Login gespeichert war und ich mich nicht mehr interaktiv eingeloggt habe.
Ich hatte zuletzt in den (Smarty) Templates alle Includes mit Hochkommas versehen.
{include file=’widgets.tpl’}
Dummerweise auch in der defaults.tpl, wo eine Variable drin war - das hier hingegen funktioniert natürlich nicht:
{include file=’$content’}
Die Hochkomma müssen bei Variablen weg. Das wurde nun korrigiert.
Weiterführende Links:
So, 16. April, 2023
Mein Backup-Skript (es dumpt lokale Datenbanken, unterstützt zig Hooks, sichert mit Restic/ Duplicity) kennt einen neuen Trick.
Auf meinem Linux-Desktop wollte ich Popup-Informationen zu einem im Hintergrund (Cronjob als root) gestarteten Skript sehen.
Und wie geht das?
Eine gängige Lösung ist notify-send (aus dem Paket libnotify).
$ notify-send –help
Usage:
notify-send [OPTION?] <SUMMARY> [BODY] - create a notification
Help Options:
-?, –help Show help options
Application Options:
-u, –urgency=LEVEL Specifies the urgency level (low, normal, critical).
-t, –expire-time=TIME Specifies the timeout in milliseconds at which to expire the notification.
-a, –app-name=APP_NAME Specifies the app name for the icon
-i, –icon=ICON Specifies an icon filename or stock icon to display.
-c, –category=TYPE[,TYPE…] Specifies the notification category.
-e, –transient Create a transient notification
-h, –hint=TYPE:NAME:VALUE Specifies basic extra data to pass. Valid types are boolean, int, double, string, byte and variant.
-p, –print-id Print the notification ID.
-r, –replace-id=REPLACE_ID The ID of the notification to replace.
-w, –wait Wait for the notification to be closed before exiting.
-A, –action=[NAME=]Text… Specifies the actions to display to the user. Implies –wait to wait for user input. May be set multiple times. The name of the action is output to stdout. If NAME is not specified, the numerical index of the option is used (starting with 0).
-v, –version Version of the package.
Das funktioniert problemlos im Kontext des aktuell eingeloggten Benutzers mit einer X-Session.
Aber mit sudo oder als Cronjob als root?
Aber eines nach dem Anderen.
Wenn ich ein Skript mit sudo starte, dann enthält die Umgebungsvariable SUDO_USER denjenigen Benutzer, der das sudo ausgelöst hat. Das Skript läuft dann als User root. Das notify-send soll aber nicht auf einer X-Session des root Users etwas enblenden, sondern einem anderen unprivilegierten Benutzer. Hier kommt die Variable DBUS_SESSION_BUS_ADDRESS ins Spiel. Wenn man die UID des Benutzers kennt, kann man es sich zusammensetzen. Diese bekommt man mit id -u [Benutzername] … und der Benutzername ist ja in SUDO_USER.
Snippet:
if [ -n ”$SUDO_USER” ]; then
export DBUS_SESSION_BUS_ADDRESS=unix:path=/run/user/$(id -u $SUDO_USER)/bus
fi
Mit jenem Snippet kann man im selben Skript auslösen
su ”$SUDO_USER” -c ”notify-send ’Titel’ ’Mein Nachrichtentext’”
und es kommt bei … genau: “meinem” Desktop an und nicht bei root. Wunderbar!
Jetzt ist da noch die Sache mit dem Cronjob als root. Hier ist ja kein sudo. Aber das ist gar banaler als man denkt: man setzt einfach die Variable SUDO_USER im Environment - also vor den Deinitionen der Zeitangaben und Aufrufe:
$cat /etc/cron.d/client-backup
SUDO_USER=axel
17 * * * * root /usr/local/bin/cronwrapper.sh 1440 /opt/imlbackup/client/backup.sh ’iml-backup’
Feintuning:
ein Simples notify-send “Titel” “Mein Nachrichtentext” verschwindet nach ein paar Sekunden. Wenn ein Fehler auftritt, dann möchte ich die Meldung sehen, lesen und proaktiv verschwinden lassen. Genau das erledigt der Parameter –urgency für uns
notify-send –urgency=critical “Fehler” “Da ging etwas schief :-/”
Hier noch ein kompletteres Bash Snippet:
if [ -n ”$SUDO_USER” ]; then
export DBUS_SESSION_BUS_ADDRESS=unix:path=/run/user/$(id -u $SUDO_USER)/bus
fi
(…)
# show a desktop notification using notify-send
# param string summary (aka title)
# param string message text
# paran integer optional: exitcode; if set it adds a prefix OK or ERRROR on summary and sets urgency on error
function notify(){
local _summary=”$1”
local _body=”$( date +%H:%M:%S ) $2”
local _rc=”$3”
local _urgency=”normal”
if [ -n ”$DBUS_SESSION_BUS_ADDRESS” ]; then
if [ -n ”$_rc” ]; then
if [ ”$_rc” = ”0” ]; then
_summary=”OK: ${_summary}”
else
_summary=”ERROR: ${_summary}”
_urgency=”critical”
fi
fi
su ”$SUDO_USER” -c ”notify-send –urgency=${_urgency} ’${_summary}’ ’${_body}’”
fi
}
Mi, 29. März, 2023
Ich habe einmal für den Blog Flatpress ein Theme bereitgestellt.
Die schlechte Nachricht: Nach Update auf die aktuelle Flatpress-Version ging leider nicht mehr viel.
Die gute: es war einfach zu beheben.
Weiterführende Links
Mi, 8. Februar, 2023
Wir lassen diverse Applikationen mit Ansible von einem Git-Repository installieren. Etwa so:
- name: ’install - Clone repo {{ repo_url }}’
ansible.builtin.git:
repo: ’{{ repo_url }}’
dest: ’{{ install_dir }}’
Dummerweise kommt dann noch ein Verschenken der Berechtigungen hinterher.
Seit Kurzem - mit einer neueren Git Version - häufen sich Abbrüche beim Git pull
detected dubious ownership in repository
Und auch die Lösung wird in der Fehlermeldung mitgegeben:
git config –global –add safe.directory [Verzeichnis]
Ja denn … packen wir doch einen Schnipsel hierfür dazu:
# set install dir as safedir …
- name: ”FIX - add installdir {{ install_dir }} as safedir”
ansible.builtin.shell: |
git config –global –get-all safe.directory \
| grep ”{{ install_dir }}” \
|| git config –global –add safe.directory ”{{ install_dir }}”
Wenn es ein paar mehr Server sind, sollte man sich das in in eine Rolle verpacken, um es etwas abstrakter zu halten.
Zum Reparieren packt man es zur einmaligen Ausführung des Playbooks VOR das ansible.builtin.git … aber dann gehört es dahinter.
Der Shell-Aufruf präft, ob der Pfad bereits aufgenommen ist - nur wenn nicht, wird er hinzugefügt. Ansonsten würde ein mehrfaches “add” zu zigfachen Duplikaten desselben Pfades führen.
Di, 3. Januar, 2023
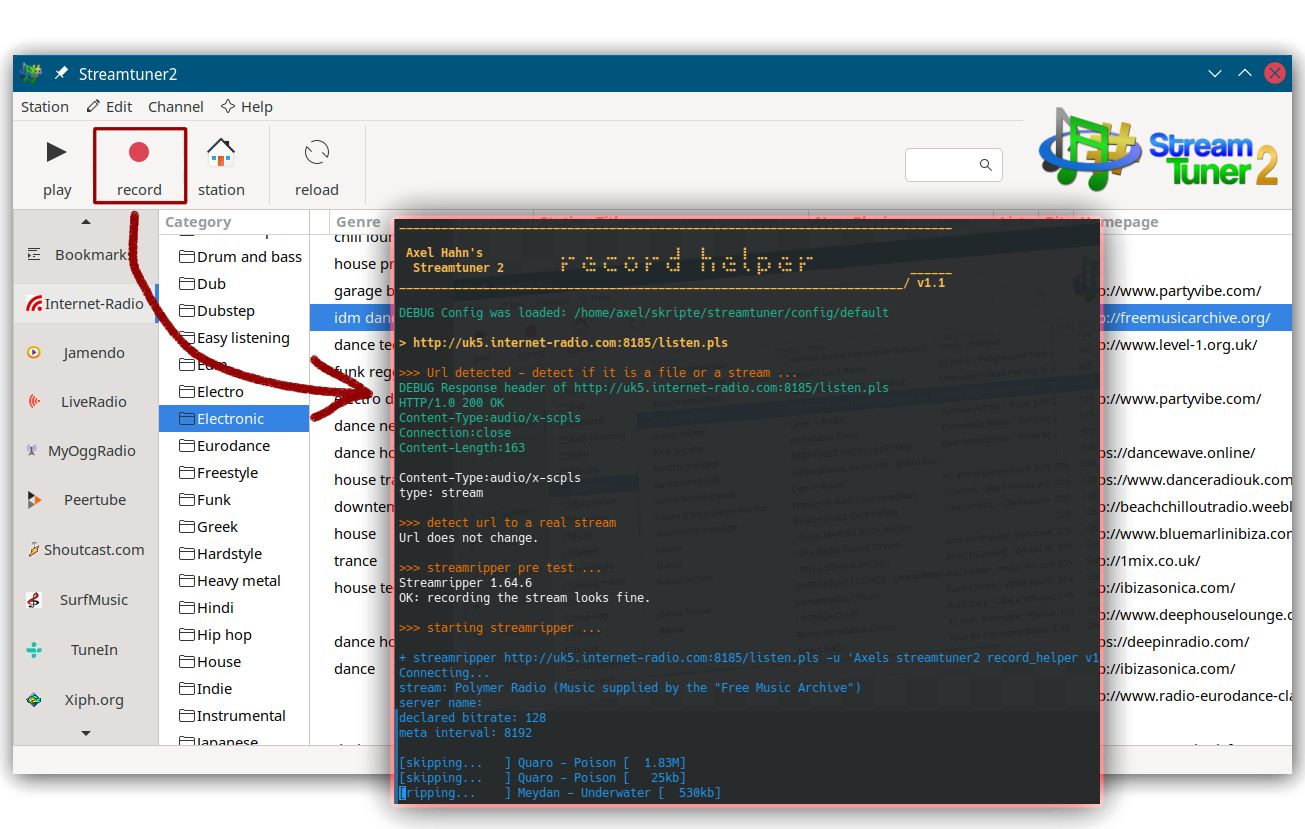
Ich schrieb vor nicht allzu langer Zeit einen Blogeintrag, um in Streamripper2 die Aufnahme-Funktion besser zu nutzen.
Diese muss man konfigurieren - also schlusendlich einen Kommandozeilenaufruf hinterlegen. Klassischerweise wird für Radiostreams das Tool Streamripper konfiguriert - und um eine optische Ausgabe zu haben, setzte man einen Konsolenaufruf davor. Ich fand das sehr bescheiden - sehr oft war bei egenen Versuchen war das Konsolenfenster gleich wieder zu und damit auch eine etwaige Fehlermeldung weg. Das ist doch nur unbefriedigend.
So fing alles an. Ich kann zum Glück etwas Shellprogrammierung.
Es sollte zunächst ein kleiner Wrapper sein, der anzeigt, welches Kommando mit welchen Parametern aufgerufen wird - und im Falle eines Abbruchs mich auch den Fehlertext lesen lässt.
Aber das wurde schnell etwas mehr, weil ich mit den ersten Versionen des Wrapperskripts nun auch die verschiedenen Fehlerkonstellationen von Streamripper sehen konnte. Mit Hilfe von Curl wurden die Http Response Header angezeigt, was weitere Dinge aufzeigt. So ergaben sich diese Fehlermuster:
Problem: Fehler 404 oder 410.
Lösung: keine - der Stream existiert nicht mehr.
Problem: Fehler 50x
Lösung: Ein Streamingserver arbeitet derzeit nicht oder reagiert nicht schnell genug (Timeout). Lösen kann ich das nicht, aber eine Meldung ausgeben, damit man weiss, dass es wohl ein nur temporäres Problem gibt und man es später wieder versuchen kann.
Problem: die URL ist kein abspielbarer Stream, sondern eine Playlist.
Lösung: Die Playlist wird ausgelesen und die erste Streaming-URL daraus extrahiert. Anm.: Es gibt durchaus auch Playlisten-Typen, die Streamripper versteht.
Problem: Streamipper wird mit einem 403 abgewiesen.
Lösung: Manche Streamingserver verweigern den Zugriff je nach Useragent und unterbinden den Abruf durch den Streamripper. Aber im Kommandozeilenaufruf des Streamrippers kann man den Useragent umschalten.
Problem: Streamriupper meldet -28 [SR_ERROR_INVALID_METADATA]
Lösung: Keine - das ist ein Fehler im Streamripper selbst: er fordert Daten mit Http1.1 an, versteht aber selbst nur Http 1.0 und kommt dann mit der Antwort des Streamingservers nicht klar. Neben dem kurzen kryptischen Fehlercode wird dann ein ergänzender Hinweis eingeblendet. Es gibt einen nicht offiziellen Patch, mit dem man Streamripper neu complilieren kann - da die letzte Streamripperversion 2008 erschien, wird es wohl nicht mehr offiziell gefixt.
Weil es im Streamripper noch Plugins auf MODarchive und Jamendo gibt: ich habe noch Downloads mit Curl ergänzt:
- für Trackerfiles von MODarchive hinzugefügt (die Benamung der Zieldatei hole ich aus dem Http Response Header aus dem Attachment Filenamen)
- für jamendo MP3s (die Benamung der Zieldati erfolgt nach Aufruf von ffprobe - welches zu ffmpeg gehört - und wird aus Titel, Künstler und Jahr zusammengesetzt)
Im Dezember erschien die Version 1.1 - diese prüft die benötigten Tools und hat eine Erweiterung in der Cleanup-Funktionalität erfahren.
Die kleinen Heilungsfunktionen und verwertbare Meldungen für ein Debugging im Fehlerfalls sind doch immer hilfreich. Das scheint auch anderen zu gefallen. Mario Salzer verlinkte den Wrapper auf fossil.include-once.org - ich setze hiermit einen Link auch gern zu ihm zurück.
weiterführende Links:
- Axels Blog: Streamtuner2 - Aufnahmen/ Downloads
- Github: mein ST2 record helper (en)
- Docs: mein ST2 record helper (en)
- sourceforge - Streamtuner2 Diskussion “ST2 does not record” (en)
- fossil.include-once.org: Hilfe zu Streamtuner2 (en)
- Streamtuner2 (en)
- Streamripper (en)
Mi, 14. Dezember, 2022
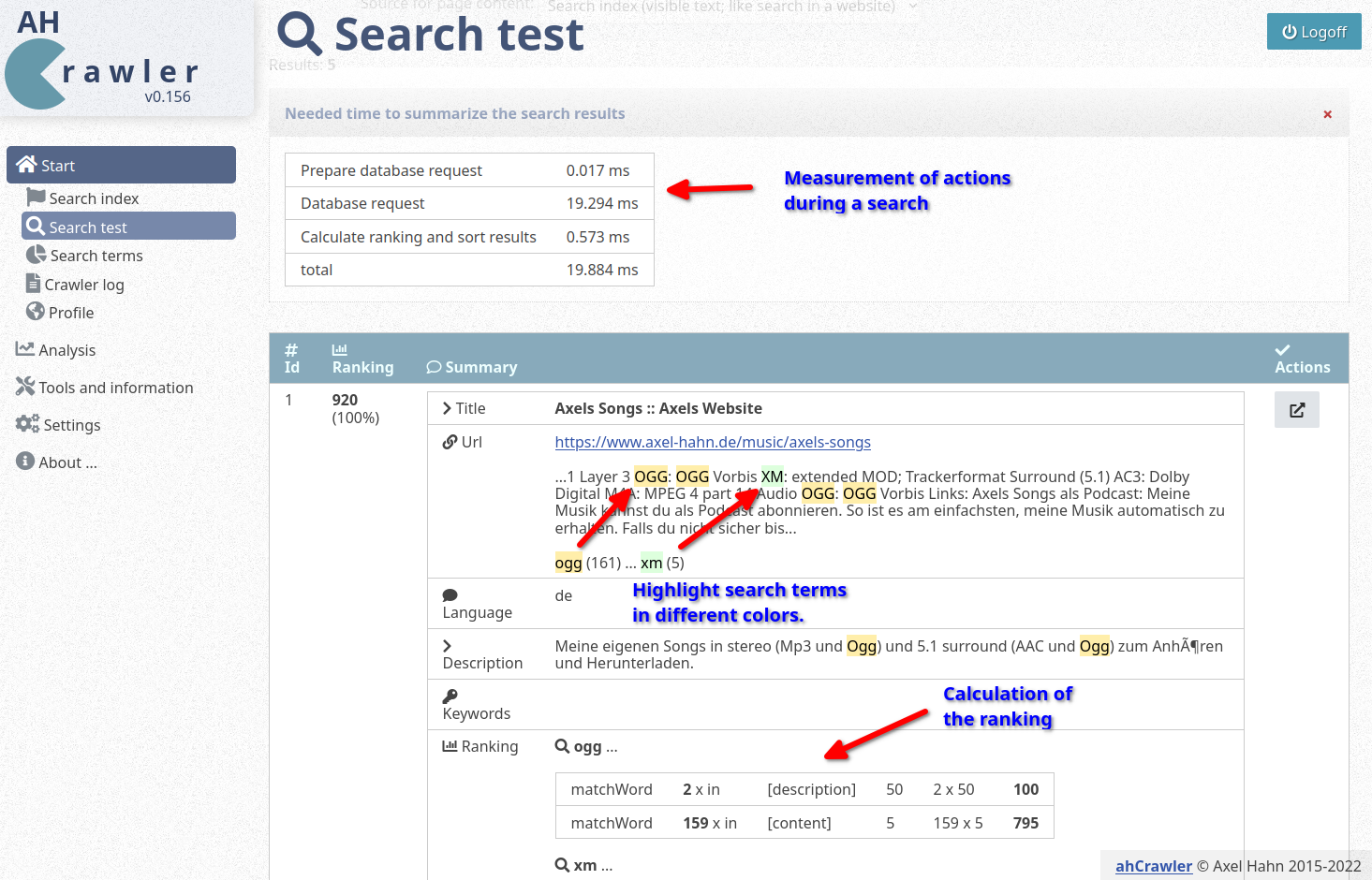
Ich habe ein Update des ahCrawler veröffentlicht.
In diesem Release kamen hinzu
- meine Docker-Entwicklungsumgebung wurde aufgenommen
- die Dokumentation wurde neu geschrieben als Markdown und ebenfalls im Repo aufgenommen
- es gibt zahlreiche Updates im Bereich der Suche im Backend und Frontend.
Das führte dazu, dass die Verzeichnisstruktur des Repos verändert werden musste. Alle bisherigen Files konnten unterhalb Webroot in einem beliebigen Unterverzeichnis geklont werden. Nun wurden alle Webfiles in den Unterordner “public_html” verschoben. Git basierte Installationen machen eine laufende Instanz mit einem Update kaputt, aber ich hoffe, ich habe es gut genug dokumentiert.
weiterführende Links:
- Github: Sourcecode
- Docs (axel-hahn.de): Changelog
- Docs (axel-hahn.de): Upgrade auf v0.156 (Zielseite wurde wg. veralteter Version entfernt)
- Twitter-Post zum Update
- Mastodon: Tröööt zum Update auf fosstodon.org
Di, 22. November, 2022
Ich habe da eine unbekannt lang laufende Aufgabe: ich möchte vom Backup-Tool Restic das Backup-Repository auf Version 2 migrieren. OK, eigentlich ist die Aufgabe ja egal. Alle 100+ Systeme kommen damit nicht in der Nacht durch.
Ich möchte …
- dass pro Nacht nur einige Systeme eine lang laufende Aufgabe wahrnehmen
- nach N Tagen soll sichergestellt sein, dass auch alle Systeme den Job 1x gemacht haben.
Mir kam der Modulus in den Sinn. [Weiterlesen…]