Mysql-connect sehr langsam?
Für Windows gibt es fixfertige Pakete für die Kombination Apache + Php + Mysql + X, wie z.B. XAMPP oder Wamp.
Für ein kleines Projekt habe ich auf eine solche zurückgegriffen und irgendwie war es langsam. Was genau langsam war, war nach einigem Debugging lokalisiert:
(...) $iStart=microtime(true); mysql_connect($hostname . ":" . $hostport, $username, $password); echo microtime(true) - $iStart."s to open DB $database<br>"; (...)
Das mysql_connect() brauchte regelmässig 1 Sekunde - die anschliessenden Queries 0.00x Sekunden.
Ursache ist der Zugriff mit dem Hostnamen “localhost” auf die Loopback-Adresse. Wenn man den Mysql-Service auf eine IP-Adresse bindet, geht es massiv schneller. Konfiguriert wird dies in der my.ini im Installationsverzeichnis von Mysql. Oder man verbindet sich auf die IP-Adresse 127.0.0.1.
Ach, und unter Windows den Eintrag lower_case_table_names=2 nicht vergessen - daher schiebe ich es mal hinterher:
(...) bind-address="127.0.0.1" bind-address = ::1 # fuer ipv6 lower_case_table_names=2 (...)
Nach Änderung der Konfiguration muss man den Mysql-Dienst neu starten, damit es wirksam wird.
Weiterführende Links:
Ausgabe des Blogs wurde verbessert
Ein paar Kleinigkeiten verbessert man immer mal wieder hier und da …
1) Microdata eingeführt
Naja, zumindest einmal rudimentär. Vielleicht können Suchmaschinen dann etwas genauer die Bloginhalte analysieren.
Die Anpassung erfolgte in den Template-Files unter
[Flatpress-Root]/fp-interface/themes/[Theme-Name]/*.tpl
anhand des Links [01] (s.u.).
2) Filtertyp und Wert anzeigen
Wenn man im Archiv Monat/ Jahr wählte oder aber eine der Kategorieen, so war funktionell die darauffolgende Ansicht korrekt, aber es wurde in Flatpress nicht ausgegeben, dass und welche Filteraktion gerade greift. Nun wird der Anzeigemodus eingeblendet:


Pimped Apache Status - ZPanel Modul verfügbar
Ist doch schön, dass Leute Gefallen an meinem Tool finden.
Vor ein paar Tagen hat mir Russel einen Fix gesendet, weil das Curl-Multiexec (das holt von allen Webservern parallel die Statusinformationen ab) in seiner Umgebung zu lange brauchte. Und nebenbei weiss ich nun auch, dass es auch ein ZPanel Modul für meine PHP-Applikation gibt.
Nachtrag:
Ich hab soeben auch auf Version 1.08 aktualisiert, die den Fix für curl und als neues Feature die Anzeige von Balken enthält.
- Pimped Apache Status - Webseite
- Pimped Apache Status - auf Sourceforge
- http://forums.zpanelcp.com/showthread.php?28323-Pimped-Apache-Status - ZPanel Forum mit Installationsanleitung für ZPanel (Anm.: Die Webseite forums.zpanelcp.com wurde deaktiviert)
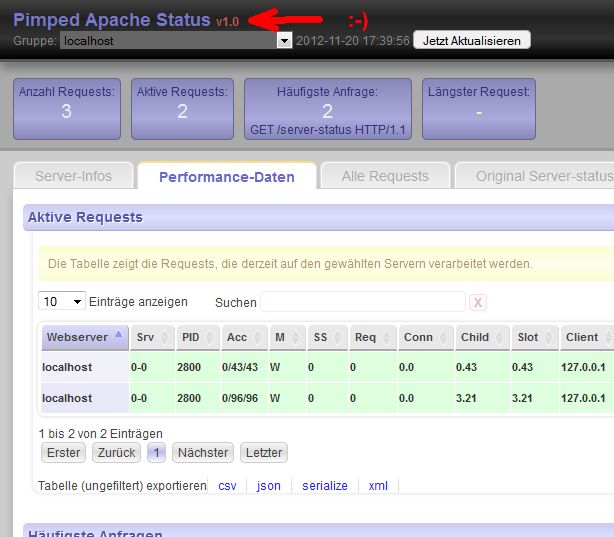
Pimped Apachestatus - v1.0 released
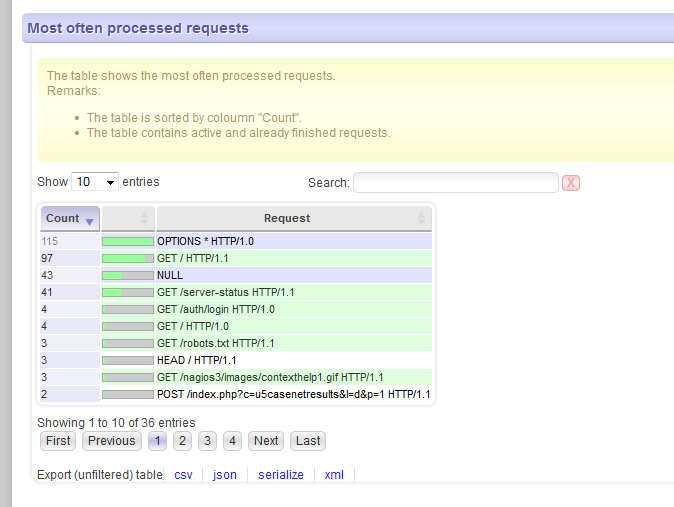
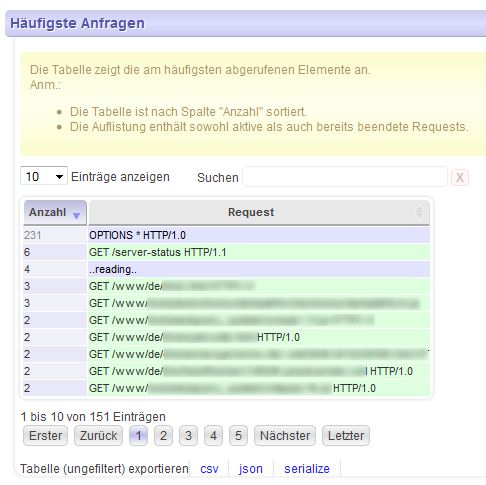
Viele kennen den Apache Webserver … und dann wohl auch dessen Server-status Seite. Weil man diese HTML-Seite nicht wirklich toll lesen und verwerten kann, habe ich mir ein Tool geschrieben, das diese Seite parst und durch verschiedene Filter gejagt, die verschiedensten Infos als Tabellen darstellt:
- nur aktive Requests anzeigen
- häufigste Requests
- längste Requests
- u.v.m.
Alle Tabellen sind per Mausklick sortierbar und lassen sich durch Texteingabe filtern.
Die Tabellen lassen sich exportieren, z.B. CSV oder XML.
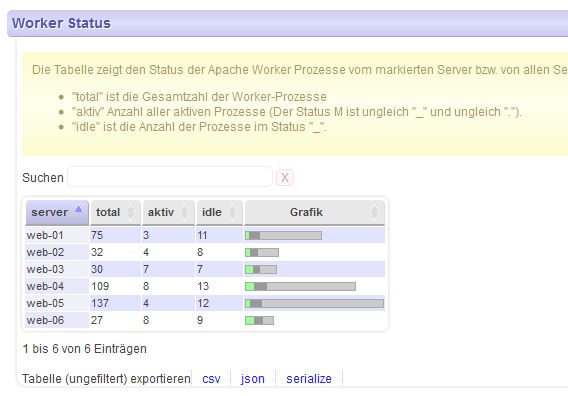
Das Ganze funktioniert nicht nur mit einem einzelnen Apache-Server - man kann mehrere Apache-Server, die gemeinsam hinter einem Loadbalancer dieselbe Webseite ausliefern, in einer Tabelle zusammenfassen. Die häufigsten oder längsten Requests auf 5 oder 10 Servern zu ermitteln - das ist mit Lesen der Server-Status-Seiten unmöglich - mit meinem Tool wird’s zum Kinderspiel.
Seit einem Jahr sind immer wieder etliche Versionen veröffentlicht wurden, bei denen ich das Gefühl hatte: “Ja eigentlich funktioniert ja alles, wie es soll”.
Heute - ja heute - ist alles anders: mein heutiger Release heisst Version 1.0. Tusch!!!
Weiterführende Links:
- Sourceforge (englisch) Projektseite und Download
- Axels Webseite
- Dokumentation (englisch)
PHP-Schnipsel: Hintergrundjobs durch Seitenaufrufe auslösen lassen
Wenn man bei seinem Provider keinen Cronjob einrichten kann, aber genügend Besucher hat, kann man ggf. Hintergrundjobs während der Seitenaufrufe auslösen. Man muss dafür sorgen, dass nicht jeder einzelne Seitenaufruf die Verarbeitung triggert, sondern es soll max alle n Sekunden geschehen.
In PHP definiere ich ein Array mit der Konfiguration und ein Arbeitsverzeichnis. Im Arbeitsverzeichnis wird bei Ausführung eines Jobs eine Datei zum Merken des letzten Ausführungsdatums getoucht (jaja, ein schönes deutsches Wort). Soll derselbe Job erneut ausgeführt werden, wird das Alter der Datei im Arbeitsverzeichnis geprüft. Wenn das Alter Älter als mein definiertes Limit ist, dann wird der Job erneut ausgeführt - ansonsten nicht.
Klingt einfach … - ist es auch ;-)
Voraussetzungen, damit das nachfolgende Beispiel funktioniert:
- wget muss am Webserver vorhanden sein (alternativ liessen sich auch curl oder lynx verwenden)
- PHP-Funktion exec muss zugelassen sein
- getestet wurde es nur mit einem Unix-System als Webserver (für Windows s. Anmerkungen unten)
PHP mit Sqlite - mein erster Gehversuch
Ich habe mal einen Download-Zähler gebaut: mittels .htaccess werden alle Dateizugriffe auf ein PHP-Skript umgebogen, welches einmal die angeforderte Datei ausliefert und den Zugriff protokolliert.
In PHP5 ist Sqlite direkt mitgeliefert. Die Sqlite Datenbank ist eine Textdatei, auf die ohne einen laufenden Server zugegriffen wird. Für kleine Webauftritte, wo das Webroot nicht auf einem NFS- oder SMB-Share liegt, ist dies problemlos.
Der wesentliche Vorteil einer SQl-Datenbank zu einer (CSV-) Textdatei ist die Auswertung der Daten: mit SQL Queries kommt man schnell zu den gewünschten Informationen.
Ich definiere mal in PHP eine Variable mit dem Dateinamen zur Datenbank:
$sqliteDB = $_SERVER['DOCUMENT_ROOT']."/sqlite/downloads.sqlite";
In dieser Datenbank ist - weil es zum Einstieg einfacher ist: mit einem grafischen Tool - eine Tabelle angelegt worden:
CREATE TABLE "downloadcount" ( "id" INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL UNIQUE , "time" DATETIME, "file" TEXT, "ext" TEXT, "ip" TEXT, "referrer" TEXT, "usaeragent" TEXT )
Dann muss man nur noch wissen, welcher Sqlite Treiber beim Provider vorhanden ist. Das kann wahlweise Sqlite2, Sqlite3 oder PDO Sqlite sein. Die Versionen unterscheiden sich bei den Kommandos zum Öffnen der Datenbank oder beim Aufruf zum Ausführen eines Queries.
Bei Sqlite 3
$db = new SQLite3($sqliteDB);
Bei PDO Sqlite 3:
$db = new PDO("sqlite:".$sqliteDB);
Ich beziehe mich mal auf die PDO Variante…
So öffnet man eine DB und fügt mit Ausführung eines SQL Statements einen Eintrag hinzu. Eingefügt werden hier die aktuelle Uhrzeit (des Requests), Dateiname und dessen Erweiterung, IP-Adresse des Aufrufers, Referrer und User-Agent.
// $filename enthält den Dateinamen der heruntergeladenen Datei
$db = new PDO("sqlite:".$sqliteDB);
if ($db) {
$path_info = pathinfo($filename);
$ext=$path_info['extension'];
$sql="INSERT INTO `downloadcount`
(`time`, `file`, `ext`, `ip`, `referrer`, `useragent`)
VALUES ('".date("Y-m-d H:i:s")."', '" . $filename . "', '".$ext."', '" . getenv("REMOTE_ADDR") . "', '" . getenv('HTTP_REFERER') ."','".getenv('HTTP_USER_AGENT')."');
";
// echo "SQL:<br>$sql<br>";
$db->exec($sql);
}
Weiterführende Links:
- DBeaver - Datenbankverwaltung für div. Datenbanken(kostenlos, Opensource; für Windows, Mac, Linux; unterstützte Datenbanken: Sqlite, Mysql, Postgres, Oracle u.v.a.)
- Sqlite Administrator (Freeware; Windows)
- www.php.net - PDO Sqlite
- www.php.net - Sqlite 3