Mi, 23. Oktober, 2024
Ich habe für diverse Projekte eine PHP-Entwicklungsumgebung. Mittlerweile als Docker Container.
Wenn meine Applikation in der Live Umgebung Emails versendet - wie gehe ich damit in der Dev-Umgebung um?
Ich wollte einen Email-Catcher haben, der statt Sendmail oder Postfix die Emails zu versenden, für mich abfängt.
Zum Glück ist das nicht soo schwer, dies ohne weitere Abhängigkeiten zu coden. So entstanden eine PHP-Klasse und 2 Skripte: eines, um die Emails vom STDIN einzufangen - und ein Viewer.
Ganz wichtig: es musste einfach zu verwenden sein! Voila: die Konfiguration besteht aus einer Zeile in der php.ini.
Wenn du in einer PHP Enwicklungsumgebung die versendeten Email abfangen und lesen willst: hier ist ein quick winner!
📜 License: GNU GPL 3.0
📄 Source: https://git-repo.iml … rce/php-emailcatcher
📗 Docs: https://os-docs.iml. … ch/php-emailcatcher/ (en)
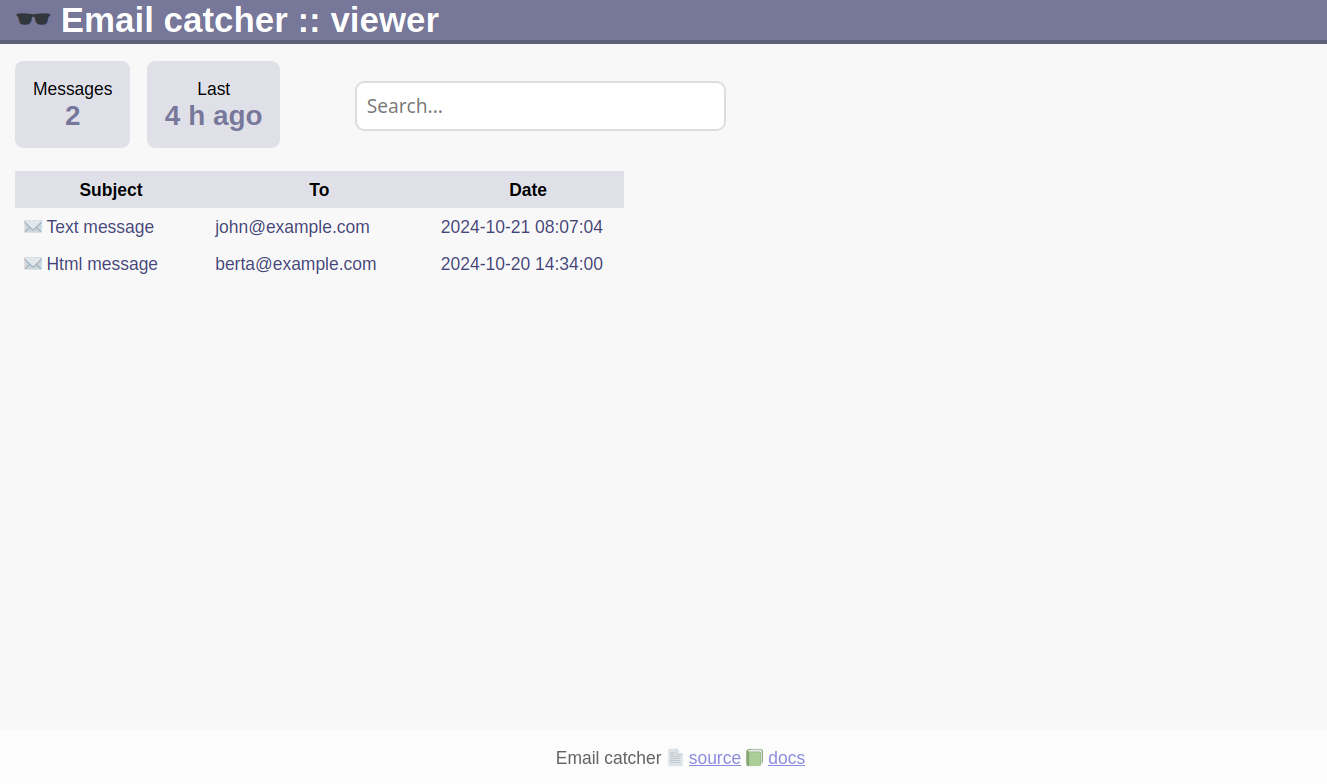
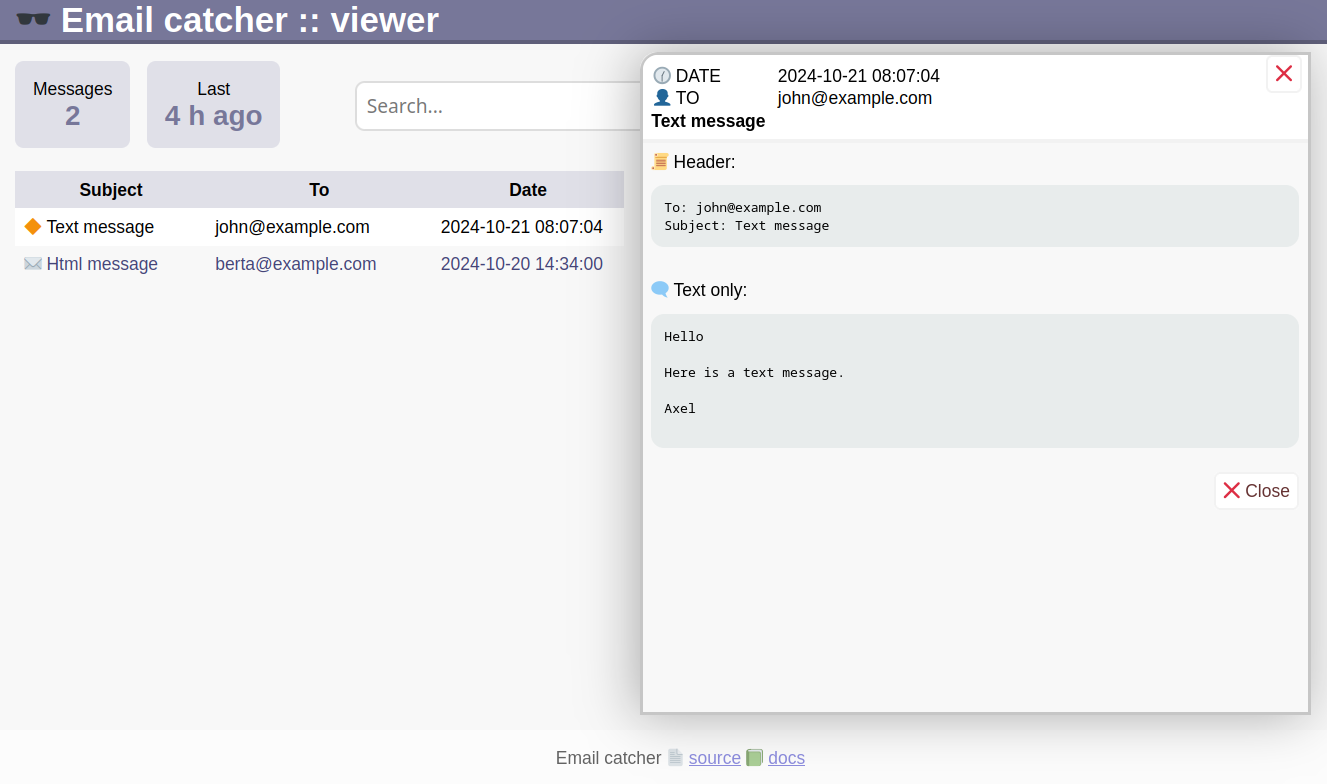
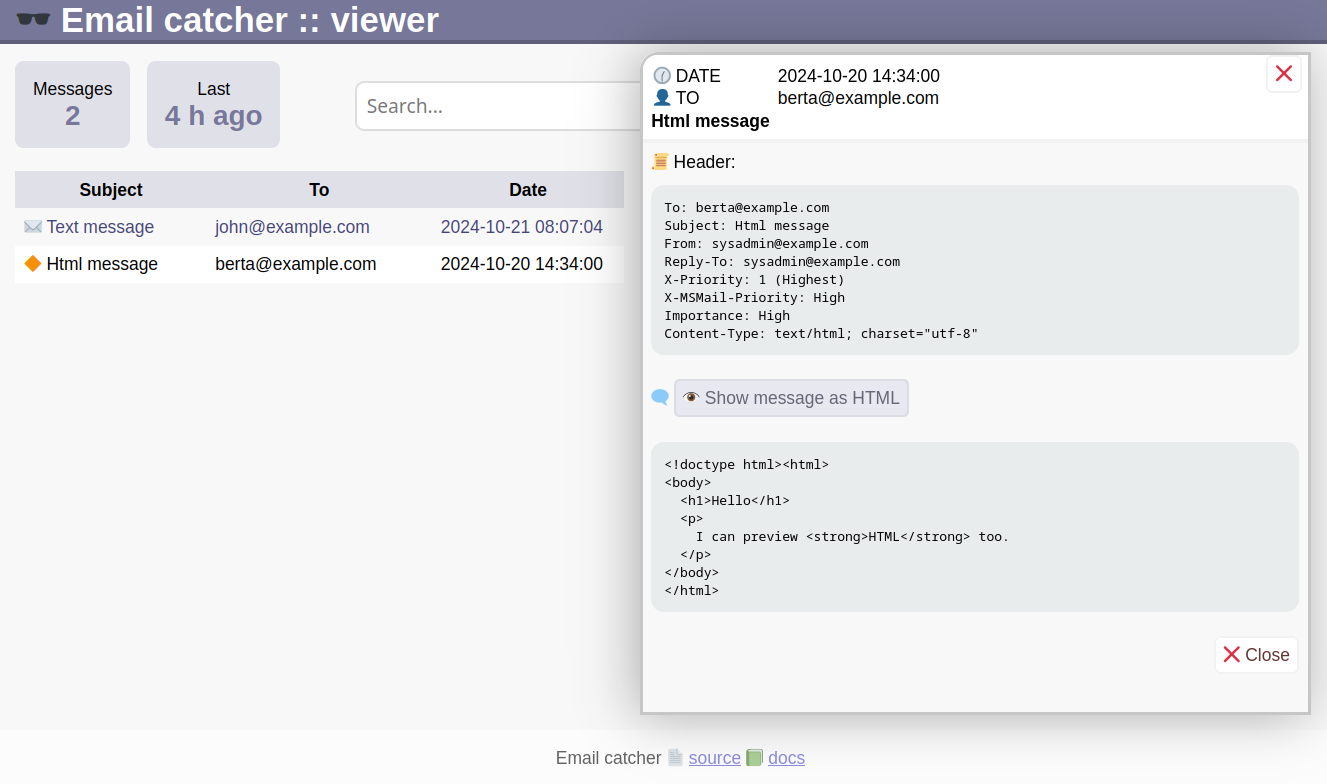
Screenshots - so sieht es aus:
Und so geht es:
Installation mit Git:
Unterhalb des Webroot lege ich im Unterverzeichnis “vendor” die Software ab.
cd [WEBROOT]
cd vendor
git clone https://git-repo.iml.unibe.ch/iml-open-source/php-emailcatcher.git emailcatcher
Einfangen der Email aktivieren:
In der php.ini ist mit sendmail_path auf das Skript php-sendmail.php zu verweisen.
[PHP]
…
sendmail_path = ”php [WEBROOT]/vendor/emailcatcher/php-sendmail.php”
Anm: Sofern php nicht im Pfad ist, muss man statt “php ” den kompletten Pfad angeben z.B. “/usr/bin/php “.
Test-Email versenden.
Viewer starten.
Unterhalb “vendor” ist im emailcatcher Verzeichnis eine viewer.php - die öffnet man im Webbrowser.
Z.B.: http://localhost/vendor/emailcatcher/viewer.php
Tja, und das war es bereits. Viel Spass damit!
Update:
Wenn man HTML Emails versendet und das Layout ansehen möchte, dann brauchte es in der präsentierten Version einige Klicks. Unnötige Klicks. Und immer wieder. HTML Emails wollte ich dann doch direkt sehen können. Im Localstorage des Webbrowsers wird sich der letzte Zustand der Anzeige gemerkt: Header anzeigen ja oder nein - und Ansicht als HTML oder Source.
Sieht wer weiteres Verbesserungspotetial zur Effiziensteigerung? Lasst es mich wissen oder macht einen Pull-Request.
Mi, 16. Oktober, 2024
An meinem Institut habe ich ein Projekt für eine Logon-Seite mit AAI / EduGain in einer funktionsfähigen Version released.
AAI ist eine Anmeldeform im universitären Bereich. Studierende und Dozenten anderer Universitäten melden sich mit dem Account ihrer eigenen Universität bei ihrem gewohnten Anmeldeprovider (IDP) an. Wenn die Authentifizierung erfolgreich war, dann kann der fremde IDP unserer Applikation den Erfolg des Logons in Form einer ID sowie einige minimale Metadaten senden. Mit jener ID lässt sich in der eigenen Anwendung ein User anlegen oder wiedererkennen. Regelbasiert oder manuell administrativ kann man einem Account Gruppen und Rollen zuweisen.
Das gibt es alles schon und ist spezifiziert, dokumentiert und schon lange produktiv im Einsatz. Sowas erfindet man nicht neu.
Mein Pro AAI Login ist in PHP programmiert - und folglich hilfreich für eine PHP-Anwendung mit Shibboleth. Der Ursprung der Entstehung war eine Ilias9 Installation.In früheren Ilias Versionen konnte man für die Start-/ Anmelde-Seite HTML-Code und Javascript einbinden. Auf diese Weise wurde ein externes Javascript WAYF (=Where are you from) von Switch eingebunden. Das funktionierte super.
In Ilias 9 kann man seine Startseite umfangreich zusammenklicken, aber Javascript konnte ich nicht einbetten. In Feldern für HTML-Code wurde es nach dem Speichern ausgefiltert. Nachdem ich mit dem Anmelde-Konfigurator aufgegeben hatte, sollte eine Seite her, die die Aufgabe der Anmeldeseite übernimmt. Zwar ist initial Ilias das erste Ziel-Projekt, aber es ist bewusst flexibel konfigurierbar ausgelegt, so dass es sich für andere Shibboleth geschützte Anwendung einsetzen liesse.
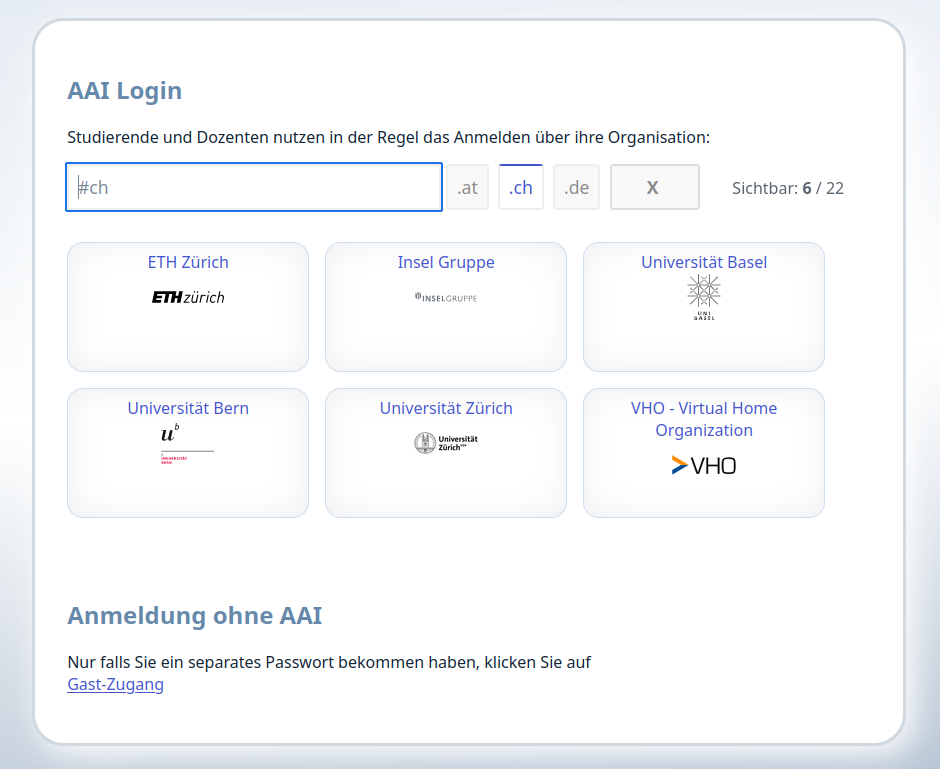
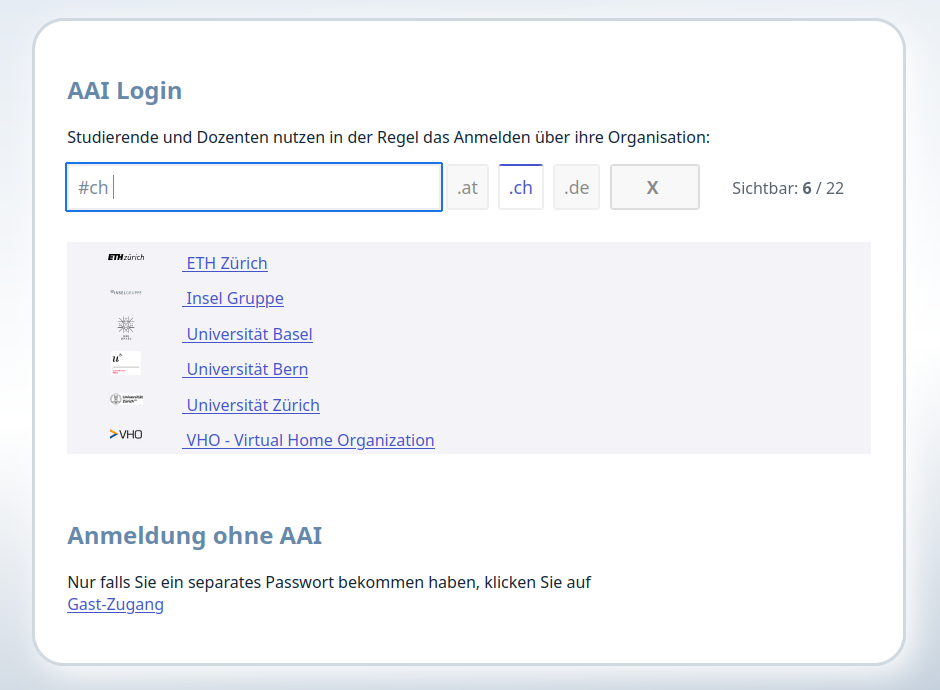
Die Logon-Seite bietet eine Liste der zugelassenen IDPs an. Mit enem Filterfeld lassen sich auf Tastendruck die angezeigten IDP reduzieren, damit ein Benutzer schnell das eigene Login finden kann.
Der Filter nach TLD (Länder-Domains) wird automatisch bereitgestellt.
Die Anmelde-(Auswahl-)Seite unterstützt Mehrsprachigkeit, mehrere Layouts (als Boxen, Liste, WAYF Auswahlseite). Hier die mitgelieferte Darstellungsform als Liste:
Weiterhin ist es flexibel bezüglich
- Sprachen. Ein deutsches und englisches Spachfile sind mitgeliefert. Der Aufwand für ein neues Sprachfile ist sehr überschaubar
- Ausgabetexte: Es gibt 3..4 Textelemente, die man frei konfigurieren kann. So kann man den HTML-Code vor und nach der Provider-Auswahl anpassen.
- Layout der Provider-Ausflistung: es werden 3 Layouts mitgliefert. 2 davon sieht man in obigen Screenshots. Ein neues Layout lässt sich schnell erstellen. Eine Klasse liefert bereits alle nötigen Daten, die man nur noch im gewünschten HTML-Code ausgeben lassen muss. Jedes Layout wird seine eigene CSS Datei einbinden - damit ist man völlig frei in der Gestaltung
- Farben: das Basislayout kommt von einer vorgegebenen CSS Datei. Mit Hilfe einer eigenen CSS Datei kann man alle CSS Rules üübersteuern und das Gesamtlayout verändern.
Die Lizenz erlaubt kostenfreie Verwendung, Einsicht in den Quellcode und Anpassung jedweder Art.
Feedbacks und Verbesserungsvorschläge sind willkommen.
📜 License: GNU GPL 3.0
📄 Source: https://git-repo.iml … pen-source/login-aai
📗 Docs: https://os-docs.iml.unibe.ch/login-aai/
Mi, 18. September, 2024
Ich habe eine Sprachdatei für ein PHP-Skript in einer JSON Datei abgelegt.
Meine HTML Seite sollte in der eingebundenen Javascript-Datei die Datei ebenfalls laden und deren Inhalt einer Variable “aLang” zuweisen.
Sicher geht es noch eleganter, aber ich bin bei diesem Snippet hängengeblieben:
var sLang=’de-de’;
var aLang={};
(…)
/**
* Init step 1: load language file and make it available in aLang
*/
async function init(){
fetch(’lang/’ + sLang + ’.json’)
.then(response => response.json())
.then(aLang => {
initStep2(aLang)
})
.catch(error => console.log(error))
;
}
/**
* Init step 2
*/
async function initStep2(langArray) {
aLang = langArray;
// just to check it in the console:
console.log(aLang);
// optional: next js function to call or more js code
}
// MAIN
init();
Do, 25. Juli, 2024
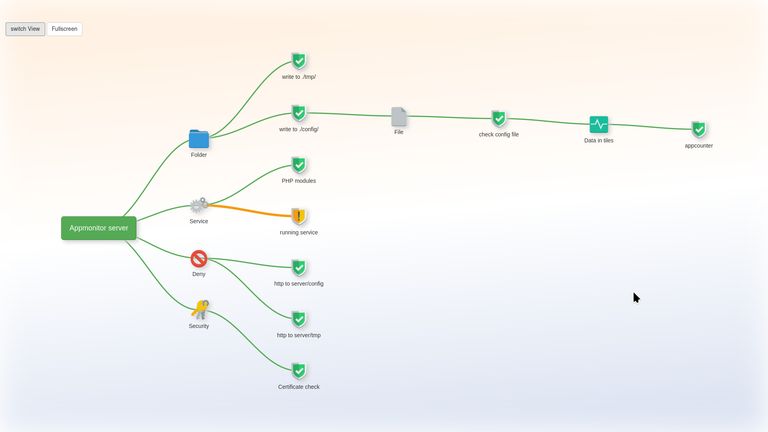
Der IML Appmonitor dient der Ergänzung unseres Systemmonitorings. Aus Sicht einer Applikation werden Prüfungen vorgenommen, die in ihrer Summe eine Aussage treffen, ob eine Applikation gerade lauffähig ist. Sei es die Verfügbarkeit von Ressourcen, APIs oder Datenbanken, Schreibzugriffe auf Upload Folder. Auch sollte man umgekehrt schützenswerte Informationen prüfen, ob diese bei gewöhnlichen Http-Anfragen eben nicht ausgeliefert werden und ein 40x Fehlercode melden.
Man kann Prüfungen miteinander verknüpfen, z.B. muss eine Konfigurationsdatei lesbar sein - die z.B. Credentials für eine Datenbank besitzt - dann ist die Prüfung der Datenbankverbindung von der Lesbarkeit der Konfigurationsdatei abhängig. So kann man einen Abhängigkeitsbaum zu visualisieren, der einem Projektmanager ein klareres Bild zu einer Störung vermitteln kann.
Im Zuge des Updates unserer PHP-Applikationen habe ich den PHP-Code unter PHP 8.3 aktualisiert:
- Bisher ist alles untypisiert gewesen. In Klassen wurden Variablen, Parameter von Methoden und deren Returncode typisiert (also eine Angabe, ob eine Variable ein String, Integer, Array, Objekt, … ist). Das hilft dem Compiler bei Optimierungen und sichert den Code ab. Ist aber auch - bei mechanischem, visuellen Ersetzen auch etwas fehleranfällig.
- PHPDoc wurde in allen Methoden geprüft - da gab es doch viele Kommentar-Sektionen, die nicht mit dem Code übereinstimmten
- Alle Arrays und Hashes wurden auf die verkürzte Array-Schreibweise umformatiert.
- Die Markdown-Hilfedateien wurden überarbeitet
Kurz: ohne Funktionalitätsgewinn wurden ein paar tausend Zeilen in 70+ Dateien geändert und heute gemergt: https://github.com/i … onitor/pull/88/files
Aber dem Programmcode tut es sicher gut, gelegentlich auf einen aktuelleren Stand gehoben zu werden.
Gleichartiges widerfuhr letzte Woche dem Code unseres Intranets.
Weiterführende Informationen:
Do, 13. Juni, 2024
Am 5. und 6. Juni fand in Berlin die Icinga Summit 2024 statt.
Es waren 2 angenehme Tage, um sich mit anderen zu Monitoring & mehr auszutauschen.
Meine erste Rede auf englisch vor “grossem” Publikum lief dann doch besser, als gedacht. Anschliessend kamen mehrere Leute auf mich zu, um mir nach dem im Vortrag Gehörtem noch Tipps mit auf den Weg zu geben. Das ist doch sympathisch!
Weiterführende Links:
- https://icinga.com/summit/]icinga.com/summit/ (Seite wurde deaktiviert)
Do, 21. März, 2024
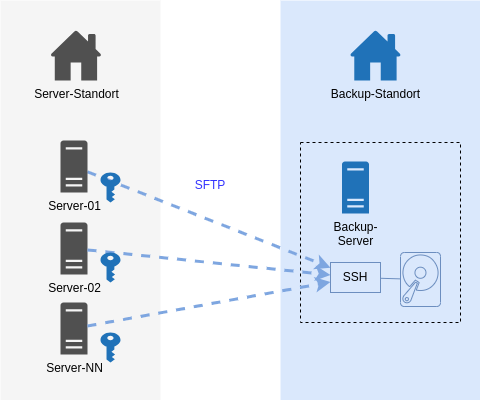
Unser Server Backup mit dem IML Backup [1] am Institut mit 150+ Systemen lief über Jahre mit Restic [2] und via SFTP zu einem Storage. Mit Restic bin ich soweit sehr zufrieden: es verschlüsselt Daten lokal vor der Übertragung und muss nach einem Initialbackup nur noch inkrementelle Backups machen. Auch das Restore von einzelnen Dateien und Ordnern hat uns nie im Stich gelassen. Insbesondere das Mounten mit Fuse ist ein hilfreiches Feature.
Dann sah ich im Januar 2024 das Videos des CCC [3]. Auf der “wichtigsten Folie des ganze Vortrags” waren Anforderungen an Backups gelistet, um sich gut gegen Ransomware-Verschlüsselungen der Infrastruktur zu wappnen. Bei vielen Punkten waren wir demnach bereits gut gewappnet. Aber es gab unschöne Schwachpunkte. Da diese jeweils eine Rechteausweitung als root voraussetzen, war dies mit “kalkulierten Risiko”.
Ein System kann seine eigenen Backup-Daten löschen.
Damit Backups nicht übermässig gross werden, werden alle N Tage im Anschluss des backups alte Daten älter 180 Tage gelöscht. Wenn ein Sysem gekapert plus der root-Account erreicht würde, kann durch böswilliges Setzen eines Delta statt 180 Tage auf 0 Tage setzend ist so ziemlich alles weggeputzt werden.
Ein System kann theoretisch Backups anderer Systeme löschen.
Bei Einbruch und Rechteausweitung auf root könnte wäre Folgendes denkbar: alle Systeme schreiben auf das Backup-Ziel mit demselben SSH-User. Auf der Zielseite gehören die Dateien demselben User und thoretisch könnte ein System Zugriff auf Backup-Daten eines anderen Systems erhalten und diese zwar nicht entschlüsseln, aber wg. Schreibrechten eben auch löschen.
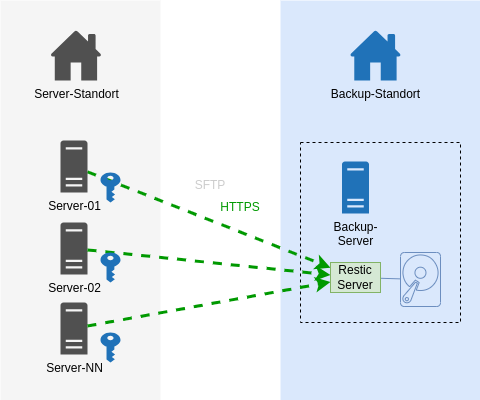
Es geht nun auch besser.
Auf dem Backup-Endpoint wurde nun der Restic-Rest-Server [4] installiert, der als Systemd Service eingerichtet wurde. Die Backup-Clients kommunizieren nun statt via SSH mit HTTPS. Sie teilen nicht mehr den auf allen Systemen gleichen privaten SSH-Schlüssel.
In den Startparametern des Rest-Servers wurden diese Optionen aufgenommen, um folgende Härtungen zu erreichen:
Ein User (Server) darf nur sein eigenes Repository beschreiben.
Option:
–private-repos
Das Unterbindet das Ausbrechen auf Backup-Daten anderer Systeme.
Jeder Backup-Client (unsere Server) bekommt einen eigenen User und ein eigenes Http-Auth Passwort zugewiesen.
Auf dem Restic Rest Server werden Usernamen und das verschlüsselte Passwort in eine .htpasswd eingetragen.
Stolperfalle: Es böte sich an, die Benutzer gleich zu benennen, wie den Server. Eine Limitierung in der der .htpasswd lässt einen Punkt im Benutzernamen jedoch nicht zu. Aber das Ersetzen des Punkts im FQDN durch einen Unterstrich führt zu keinerlei Überschneidungen. Dem schliest sich an, dass das Backup-Verzeichnis nun statt [Backup-Dir]/ nun [Backup-Dir]/ ist. Bei der Umstellung von SSH auf HTTPS muss somit das Backup-Ziel-Verzeichnis beim Backup-Server umbenannt werden.
Ein User (Server) darf Daten nur anhängen.
Option:
–append-only
Kurz: Löschen ist nicht mehr möglich. Das klingt sicher.
Der Pferdefuss: unser auf jedem Einzelsystem befindliche Restic Prune Job zum Löschen älter N Tage funktioniert so nicht mehr. Ich habe es auch probiert: es wird mit einem 40x Statuscode zurückgewiesen.
Unsere Abhilfe sieht wie folgt aus: auf dem Backup-Zielserver läuft nun ein Cronjob, der über alle Backup-Repos das Pruning macht [4]. Wir lassen es erkennen, wie alt das letzte Prubg war und pausieren das Prune auf ein Repository dann für N Tage. Damit Restic auf Inhalte zugreifen kann, muss das Passwort zum Entschlüsseln aller Serverdaten für das Skript greifbar sein. Wir generieren mit Ansible eine Konfigurationsdatei, die alle Benutzernamen und Restic-Verschlüsselungspasswörter am Backup-System niederschreibt. Diese Datei gehört root:root und hat die Rechte 0400.
Zustand NEU:
Das Ergebnis ist derselbe Datenfluss - nur mit einem anderen Protokoll - Https statt ssh. Entscheidend sind die 2 o.g. Optionen für den Restic Server auf dem Backup-Ziel.
Dies war eine Beschreibung mit hoher Flughöhe mit weniger technischen Details. Bei Fragen nutzt gern die Kommentarfunktion oder fragt mich an.
Weiterführende Links:
- Docs: IML Backup (en)
- Github: Restic (en)
- CCC Dez 2023: Hirne hacken - Hackback Edition
- Github: Restic REST Server (en)
- os-docs.iml.unibe.ch: rest-pruner.sh (en)
Mi, 13. Dezember, 2023
In Manjaro Linux gibt es Pakete - darunter auch PHP und ist schnell installiert. Den Composer nachzuschieben ist ein Nobrainer und dann kann man
composer global require daux/daux.io
aufrufen, um Daux lokal zu installieren. Das klingt alles straight forward. Wie bei allen anderen Distros mit Paketmanagement auch.
Es gibt jedoch unter Manjaro ein ABER: ein “daux generate” verweigert seinen Dienst, sobald man das Generieren einer Offline-Javascript Suche in einem Doc Projekt aktiviert hat. Es fehle die Funktion iconv. Das entsprechende PHP-Paket kann man installieren, aber dann wird der Apache httpd gleichsam installiert.
Daher nochmal Reset und von vorn. Wie bekommt man Daux nun inkl. Suche zum Laufen? Also, ohne einen Webserver installieren zu müssen und rein mit PHP-CLI?
(1) PHP-Quelle einbinden
Es gibt neben Manjao-Paketen weitere Quellen, die man einbinden kann.
https://aur.archlinux.org/pkgbase/php82
Man folge der dortigen Anleitung:
(a) als root in der /etc/pacman.conf eintragen
[home_el_archphp_Arch]
Server = https://download.opensuse.org/repositories/home:/el:/archphp/Arch/$arch
(b) als root in der Shell:
key=$(curl -fsSL https://download.opensuse.org/repositories/home:el:archphp/Arch/$(uname -m)/home_el_archphp_Arch.key)
fingerprint=$(gpg –quiet –with-colons –import-options show-only –import –fingerprint <<< ”${key}” | awk -F: ’$1 == ”fpr” { print $10 }’)
pacman-key –init
pacman-key –add - <<< ”${key}”
pacman-key –lsign-key ”${fingerprint}”
Und zum Aktualisieren der Paket-Datenbank
pacman -Syy
(2) PHP Pakete installieren
Man installiere diese Pakete:
php82
php82-cli
php82-iconv
php82-mbstring
php82-openssl
php82-phar
Jene werden benötigt, um den Composer zu compilieren.
(3) php verfübar machen
Noch schnell ein Zwischenschritt.
Nach Installieren von PHP82-cli wird bei Eingabe “php” auf der Shell kein Binary gefunden. Das, weil es “php82” heisst - Daux wird aber nach “php” suchen. “which php82” verrät uns, dass es unter /usr/bin liegt (oder aber man schaut in die Paket-Details).
Wie lösen wir das? Ich würde zu einem Softlink greifen.
Man kann sich mit “echo $PATH” ansehen, welche bin-Verzeichnisse verfügbar sind. Weil ich bei mir am Rechner nur allein mit meinem lokalen User arbeite, lege ich den Softlink unter meinem $HOME an. Soll es global für alle User funktionieren, würde ich den Softlink in /usr/bin/ anlegen.
cd ~/bin/
ln -s /usr/bin/php82 php
Test: Wenn anschliessend “php -v” nun etwas ausgibt, dann passt es.
(4) PHP Composer 8.2 installieren
Nun kann man den php82-composer aus den AUR installieren. AUR muss man folglich im Paketmanager aktiviert haben.
(5) Daux installieren
composer82 global require daux/daux.io
Also … statt “composer” ist “composer82” entsprechend der PHP-Version aufzurufen.
(6) Daux verwenden
daux generate
… voila: funktioniert nun inkl. Suche! Viel Spass!
Weiterführende Links:
- daux.io (en)
- Arch :: Package Base Details: php82 (en)
So, 3. Dezember, 2023
PHP hat kürzlich die Version 8.3 herausgegeben [1] - und gleichzeitig erhält PHP 8.0 keinerlei Support mehr.
Mein Werkzeug ahCrawler [2], [3] - eine Suchmaschine für diie Webseite und Webseiten-Analysetool - darf hier nicht aussen vor sen. Sie wurde in einem Docker-Container mit der neuen PHP Version 8.3 durchgetestet … und für gut befunden.
Die vorherige Version lief bereits mit dem aktuellen PHP - es gab im Minor-Update nur kleine, nichtfunktionale Updates, die wie immer via Web UI oder Git pull oder Updater eingespielt werden können.
Die Suchseite hinter www.axel-hahn.de ist bereits aktualisiert worden.
Weiterführende Links
- php.net: PHP 8.3 Released (en)
- Docs ahCrawler (axel-hahn.de) (en)
- Sourcecode ahCrawler (github.com) (en)
Fr, 25. August, 2023
Ich skripte meine Dinge hauptsächlich in Bash.
Und weil niemand etwas nutzt, was nicht dokumentiert ist, habe ich 2 neue Dokumentationen online gestellt:
(1)
Kürzlich habe ich eine Bash-Komponente geschrieben, die die Handhabe der ANSI Farben vereinfacht.
Man kann eingfach Farben für Vordergrund und Hintergrund setzen - mit Namen einer Farbe oder HTML-CSS-Farbangabe.
Doc zu bash_colorfunctions
Rein zur Veranschaulichung: damit kann man farbige Texte ausgeben mit
color.echo ”white” ”green” ”Yep, it seems to work!”
… oder aber die Farbe nur setzen, um nachfolgende Kommandos in jener Farbe die Ausgabe machen zu lassen. Zum Aufheben der Farbdefinition ruft man ein color.reset auf:
color.fg ”blue”
ls -l
color.reset
(2)
Schon einige Monate auf Github ist mein Projekt, das mit Hilfe eines lokal installiertten Nginx den Zugriff auf eine Webapplikation als Docker Container mit Https und mit Namen der Applikation ansprechen lässt.
Doc zu nginx-docker-proxy
Beide Projekte sind freie Software und Opensource.
Do, 25. Mai, 2023
Wie oft ich das schon im Linux Filesystem gebraucht habe: in einem aktuellen oder angegebenen Verzeichnis prüfen, ob der Linux-Benutzer XY bis dorthin “durchkommt” und Berechtigungen in einem Verzeichnis oder auf eine Datei hat.
Also schrieb ich ein Shellskript. Man ruft es mit einem Parameter für ein zu prüfendes Verzeichnisses auf. Oder ohne Parameter für das aktuelle Verzeichnis.
Ich fange mal mit dessen Ausgabe an:
$ lsup
drwxr-xr-x 1 root root 244 Apr 2 23:34 /
drwxr-xr-x 1 root root 100 Jun 4 2022 /home
drwx—— 1 axel autologin 1.7K May 25 18:17 /home/axel
drwxr-xr-x 1 axel autologin 232 May 25 19:50 /home/axel/tmp
Ab dem Root-Verzeichnis werden mit ls -ld alle Verzeichnisebenen bis zum angegebenen Punkt angezeigt.
Syntax:
$ lsup -h
===== LSUP v1.3 :: make an ls upwards … =====
Show directory permissions above by walking from / to the given file.
You can add no or one or multiple files as params.
SYNTAX:
lsup Walk up from current directory
lsup FILE [FILE N] Walk up from given file/ directory
If the target is relative it will walk up
to the current directory
lsup -h Show this help and exit
EXAMPLES:
lsup
lsup .
lsup /var/log/
lsup my/relative/file.txt
lsup /home /tmp /var
Zur Installation: als User root;: cd /usr/bin/ und nachfolgenden Code in eine Datei namens “lsup” werfen und ein chmod 0755 lsup hinterher.
#!/usr/bin/env bash
# ======================================================================
#
# Make an ls -d from root (/) to given dir to see directory
# permissions above
#
# ———————————————————————-
# 2020-12-01 v1.0 Axel Hahn
# 2023-02-06 v1.1 Axel Hahn handle dirs with spaces
# 2023-02-10 v1.2 Axel Hahn handle unlimited spaces
# 2023-03-25 v1.3 Axel Hahn fix relative files; support multiple files
# ======================================================================
_version=1.3
# ———————————————————————-
# FUNCTIONS
# ———————————————————————-
function help(){
local self=$( basename $0 )
cat <<EOH
===== LSUP v$_version :: make an ls upwards … =====
Show directory permissions above by walking from / to the given file.
You can add no or one or multiple files as params.
SYNTAX:
$self Walk up from current directory
$self FILE [FILE N] Walk up from given file/ directory
If the target is relative it will walk up
to the current directory
$self -h Show this help and exit
EXAMPLES:
$self
$self .
$self /var/log/
$self my/relative/file.txt
$self /home /tmp /var
EOH
}
# ———————————————————————-
# MAIN
# ———————————————————————-
if [ ”$1” = ”-h” ]; then
help
exit 0
fi
test -z ”$1” && ”$0” ”$( pwd )”
# loop over all given params
while [ $# -gt 0 ]; do
# param 1 with trailing slash
mydir=”${1%/}”
if ! echo ”$mydir” | grep ”^/” >/dev/null; then
mydir=”$( pwd )/$mydir”
fi
ls -ld ”$mydir” >/dev/null 2>&1 || echo ”ERROR: File or directory does not exist: $mydir”
ls -ld ”$mydir” >/dev/null 2>/dev/null || exit 1
mypath=
arraylist=()
arraylist+=(’/')
IFS=”/” read -ra aFields <<< ”$mydir”
typeset -i iDepth=${#aFields[@]}-1
for iCounter in $( seq 1 ${iDepth})
do
mypath+=”/${aFields[$iCounter]}”
arraylist+=( ”${mypath}” )
done
# echo ”>>>>> $mypath”
eval ”ls -lhd ${arraylist[*]}”
shift 1
test $# -gt 0 && echo
done
# ———————————————————————-
Viel Spass damit!