Linkchecker auf meiner Webseite
Hinweis: Dieser Artikel von 2014 ist veraltet. Als Linkchecker verwende ich nun den meinen ahCrawler
In meiner alten Webseite hatte ich in externen Linkchecker direkt als Link im HTML-Code.
Im neuen CMS ist das nicht mehr so. Alle Links verweisen auf die echte Zielseite. Aber ich habe weiterhin einen Linkchecker integriert - allerdings als Javascript-Löung.
So funktioniert es:
Alle Links zeigen auf die Zielseite.
<a href="http://example.com/">Beispiellink</a>
Nun ist es so, dass ich in meinen Artikeln keinerlei externe Links verwende. Alle externen Links sind rechterhand platziert - in einem DIV namens “sbright” (”sb” für sidebar).
Alle Links in diesem Div - also nicht die auf der Seite insgesamt - werden geprüft, ob sie eine externe Referenz besitzen - falls ja, wird das Onclick Event umgebogen auf ein PHP-Skript inc_urlchecker.php. Diese Funktion nutzt jQuery:
/**
* change external links in the sidebar: a linkchecker will be added
* @returns {undefined}
*/
function initAddLinkchecker(){
var sLink=false;
$("#sbright a").each(function() {
// do something with external links:
if (this.href.indexOf("axel-hahn.de")<0){
sLink=this.href;
sLink="/axel/php/inc_urlchecker.php?url="+sLink;
$(this).attr("onclick", "location.href='"+sLink+"'; return false;");
}
});
}
In jenem PHP-Skript wird der übergebene Link mit einem Http Head Request mittels Curl geprüft.
// from http://php.net/manual/en/function.get-headers.php
function get_headers_curl($url) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, true);
curl_setopt($ch, CURLOPT_NOBODY, true);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_TIMEOUT, 10);
$r = curl_exec($ch);
$r = preg_split("/n/", $r);
return $r;
}
Ist der Http-Response Code OK (200er und 300er Http-Statuscodes) wird der Besucher weitergeleitet. Wenn nicht, gibt es einen entsprechenden Hinweis im Webbrowser samt Entschuldigung, Fehlermeldung und Link zurück zur letzten Seite.
Ach so, und vom letzten Test eines Links wird der Response Header in eine (Sqlite) Datenbank geschrieben. Die sehe ich gelegentlich ein und weiss, welche Links ins Nirvana gehen.
Weiterführende Links:
Webseite des SRF verschläft Start der olympischen Spiele?
Die ersten Wettkämpfe in Sotschi sind beendet.
Die offizielle Seite der Olympischen Spiele http://www.sochi2014.com/ hat rechts oben 2 Links auf SRF

Beide dortigen gehen ins Leere (die zu anderen SRG Unternehmenseinheiten hingegen sind OK).
Weder der Link
http://www.srf.ch/sotchiplayer
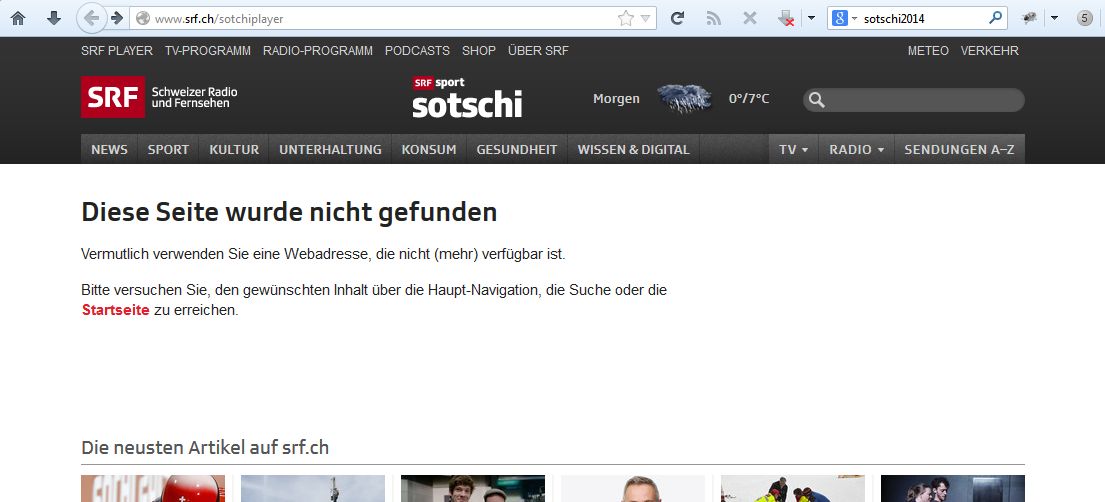
noch http://www.srf.ch/sotchi
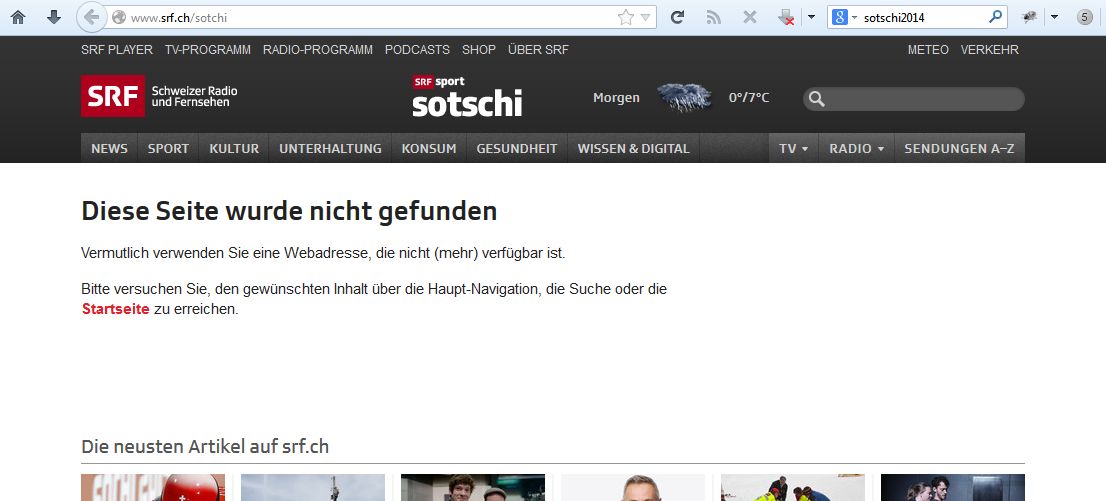
wurden gefunden.
@SRF: Es ging nun los! Bitte diese Seiten schnell freischalten :-)
Anm.: dieser Blogeintrag und Screenshots entstanden nach Kontakt-Aufnahme mit dem SRF Kundendienst. Natürlich gibt es alles rund um Olympia auf srf.ch - es geht rein um die Links, die der offiziellen Olympiaseite kommuniziert wurden.
Links:
- http://www.sochi2014.com/ (Seite leitet um auf olympic.org)
- http://www.srf.ch/sotchiplayer]www.srf.ch/sotchiplayer (Anm.: die Olympia-Player-Webseite wurde abgeschaltet)
- http://www.srf.ch/sotchi (Link wurde deaktiviert)
Updates:
10.02.: Kundendienst findet den besagten Link nicht - ich sende einen Screenshot zurück.
11.02.: Kundendienst schreibt, es wurde an die Multimedia Sportabteilung weitergeleitet.
12.02.: Redirects wurden eingerichtet - die Links funktionieren nun.
Google Analytics wurde deaktiviert
Die da in Übersee sammeln doch schon genug Daten! Mehr als genug.
Als freundliche kleine Randnotiz zu eurer Kenntnisnahme darf ich hiermit verkünden:
Das Tracking mit Google Analytics wurde auf der Webseite www.axel-hahn.de und in meinem Blog gnadenlos gekickt. Weiterhin aktiv ist die Statistische Auswertung mit der Piwik Installation unter www.axel-hahn.de - also auf “meinem” Server in D.
Leistungsschutzrecht? Lernresistenz?
Darf ich höflichst fragen, WAS GENAU das Problem ist, dass es ein Leistungsschutzrecht braucht?
Die Darstellung aller Webseiten basiert im wesentlichen auf dem Protokoll HTTP(s) und der Beschreibungssprache HTML.
Wenn das Problem denn tatsächlich wäre, dass Google & Co. Inhalte von Verlagen indexieren, dann ist es doch extrem einfach: Man nimmt sich 10 Minuten Zeit und studiert, wie man das Indexieren seiner Webseite unterbindet.
Selbstverständlich geht das und ist zudem genauestens spezifiziert. Seit über 15 Jahren. Nochmal in Worten: Fünfzehn Jahren.
Wie wäre es mit einer solchen robots.txt
User-agent: * Disallow: /
… oder auf einelnen, nicht zu indexierenden Webseiten ein
<meta name="robots" content="noindex">
in den Header einzubauen?
Was darf man von einer Person/ Instanz halten, die nach mehr als 1 Jahrzent des Vorhandenseins einer Regelung krampfhaft versucht, auf lernresistent zu machen?
Links zum Thema:
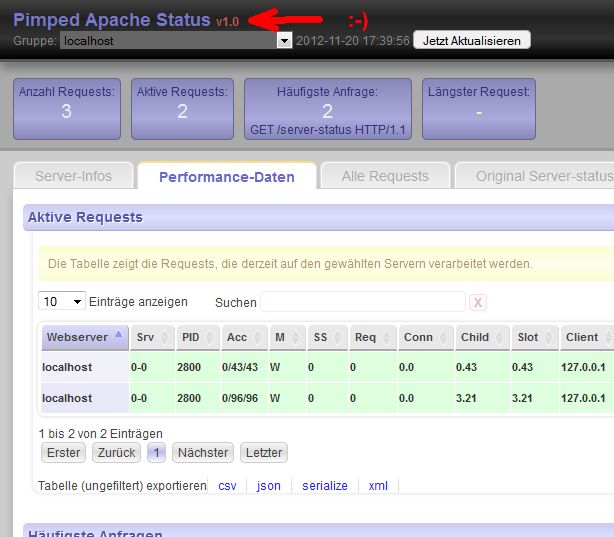
Pimped Apachestatus - v1.0 released
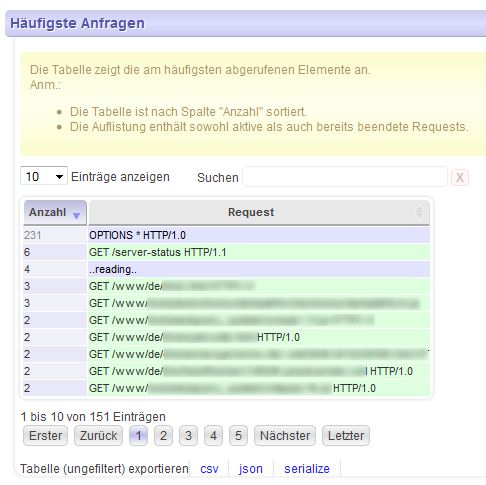
Viele kennen den Apache Webserver … und dann wohl auch dessen Server-status Seite. Weil man diese HTML-Seite nicht wirklich toll lesen und verwerten kann, habe ich mir ein Tool geschrieben, das diese Seite parst und durch verschiedene Filter gejagt, die verschiedensten Infos als Tabellen darstellt:
- nur aktive Requests anzeigen
- häufigste Requests
- längste Requests
- u.v.m.
Alle Tabellen sind per Mausklick sortierbar und lassen sich durch Texteingabe filtern.
Die Tabellen lassen sich exportieren, z.B. CSV oder XML.
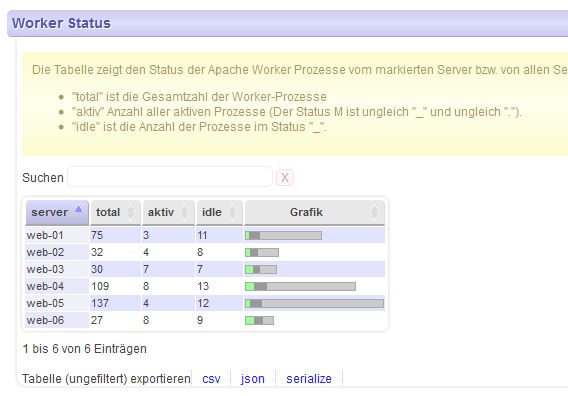
Das Ganze funktioniert nicht nur mit einem einzelnen Apache-Server - man kann mehrere Apache-Server, die gemeinsam hinter einem Loadbalancer dieselbe Webseite ausliefern, in einer Tabelle zusammenfassen. Die häufigsten oder längsten Requests auf 5 oder 10 Servern zu ermitteln - das ist mit Lesen der Server-Status-Seiten unmöglich - mit meinem Tool wird’s zum Kinderspiel.
Seit einem Jahr sind immer wieder etliche Versionen veröffentlicht wurden, bei denen ich das Gefühl hatte: “Ja eigentlich funktioniert ja alles, wie es soll”.
Heute - ja heute - ist alles anders: mein heutiger Release heisst Version 1.0. Tusch!!!
Weiterführende Links:
- Sourceforge (englisch) Projektseite und Download
- Axels Webseite
- Dokumentation (englisch)
Google Analytics - Ladezeit real?
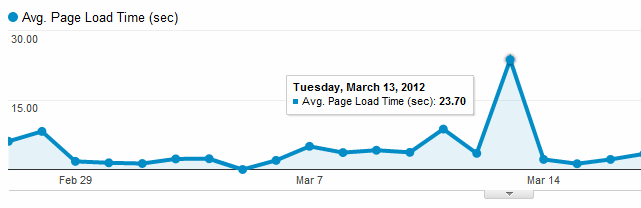
Ich habe mich bei Google Analytics in die Angabe der durchschnittlichen Ladezeit verirrt.
Da werden doch völlig dreist aktuell als Durchschnitt(!!!) saftige 8 Sekunden angegeben - Mitte des Monats gar über 20 Sekunden!
Ich frage mich: Haben die ein 33k Modem?
Jubiläum: Axel ist nun 15 Jahre im Web!
Ich habe kürzlich mein uralt-ZIP-Drive rausgekramt und ein altes Backup gefunden.
Meine erste Webseite ging vor - sage und schreibe - 15 Jahren online! F… (ferdammt), ich bin mit der Meldung genaugenommen sogar ein paar Tage zu spät ;-)
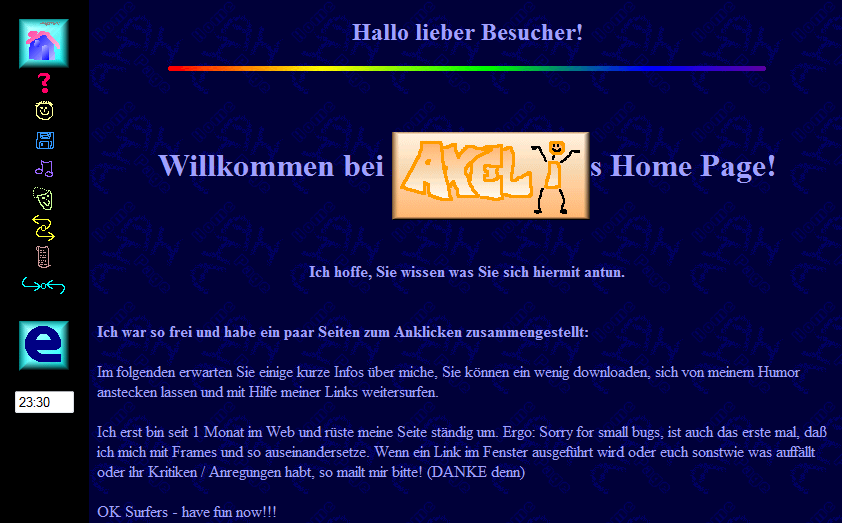
Zur Technik:
Damals war HTML 3.2 “state of the art”. Das heisst: die Webseite bestand aus Frames - und es gab zusätzlich eine Noframe-Variante. Es gab auch einige dezent animiert GIFs - natürlich alle selbsterstellt ;-)
Linkerhand das Menü enthielt Icons, die im onmouseover-Event Grafiken austauschten. Tja, das CSS-Pseudoelement :hover - geschweige denn CSS gab es ja noch nicht.
Ich habe versucht, den goldenen Regeln für schlechtes HTML möglichst gekonnt auszuweichen (heute gibt es ja zuhauf HTML-Validatoren und SEO-”Zeugs”).
Dies war die Frame-Variante:
Inhalt:
Was stellte ich in meiner ersten Webseite online? Es gab einige meiner damaligen mit Delphi und Turbo Pascal erstellten Programme für Windows und DOS zum Download - ebenso 2 Tracker-Songs.
Meine Webseiten entstanden mit einem DOS-Editor (Teil des hammermässigen Norton Commander Clons namens “DCC”), für den ich auch gleich eine Datei für das Syntax-Highlight von HTML anbot.
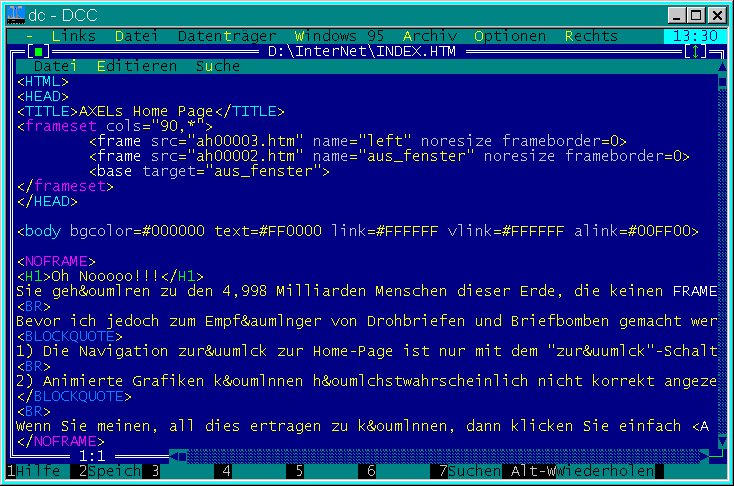
Ja, ich weiss, im Screenshot gibt es HTML-Syntax-Fehler - es ist ja meine allererste Seite ;-)
Und auch damals gab es schon unterschiedliche Browser, auf die es Rücksicht zu nehmen galt. Frames und Animationen konnten nicht alle Webbrowser.
Oooh jaaa. Lang-lang ist’s her!
Links:
- Die Goldenen Regeln für schlechtes HTML
- http://www.emerge.de/dcc.htm (Anm.: die Seite zum DCC wurde deaktiviert)
X-powered im Header will ich nicht
Wenn in einer bei einem Provider gehosteten Webseite im Header etwas mitgesendet wird, wie
X-Powered-By PleskLin
… das muss ja nicht sein. Selbst wenn der HTTP Response Header selbst nicht als Text auf der Webseite sichtbar ist - Webentwicklertools, wie die “Web Konsole” im Firefox oder “Entwicklertools” in Chrome können es mit den Standard-Boardmitteln eines Webbrowsers anzeigen lassen.
Mit Daten, was für ein System da wohl am Laufen ist, sollte man generell sparsam sein.
Wenn ein Apache Webserver im Einsatz ist (das ist bei Hostern für private Webseiten zumeist der Fall), kann man dies in der .htaccess im Webroot entfernen lassen. Man fügt folgende Zeilen hinzu:
<IfModule mod_headers.c> Header unset X-Powered-By </IfModule>
Google+ Button Html5 konform einbetten
Hinweis:
Dieser Inhalt ist veraltet. Google Plus exitiert nicht mehr.
—
Um den G+ Button einzubetten, sieht Google das Laden eines Javascripts vom Google-Server und diesen Tag vor:
<!-- Place this tag where you want the +1 button to render --> <g:plusone annotation="inline"></g:plusone>
Nur ist das nicht konform mit der HTML-Syntax, auch nicht mit HTML5. Macht man einen Testlauf mit einem Validator, so wird diese Zeile angemahnt.
[Weiterlesen…]
DRS Livestreams und Sendungen mit Android hören
Bei der Radioseite des quasi öffentlich rechtlichen Scheizer Radio und Fernsehen stehen ausgestrahlte Sendungen der letzten Jahre (MP3-Flashstream) und Livestreams als u.a. als Flashstream (MP3 und AAC+) zur Verfügung.
Bisher liessen sich diese auf einem Webbrowser unter Android trotz installiertem Flash nicht auf der DRS Webseite wiedergeben.
Dies ist nun korrigiert und das wirklich sehr umfangreiche ins Web gestellte Audio-Angebot lässt sich im Webbrowser unter Android nutzen.
